SelfMatch : Robust semisupervised time-series classification with self-distillation (2022) 논문 리뷰
Abstract
수년에 걸쳐 시계열 분류(TSC)를 위해 많은 준지도 딥 러닝 알고리듬이 제안되었다. 준감독 딥 러닝에서 표현 계층의 관점에서 낮은 수준에서 추출된 의미 정보는 높은 수준에서 추출된 의미 정보의 기초이다. 저자들은 추출된 높은 수준의 의미 정보가 낮은 수준의 의미 정보를 포착하는 데도 도움이 되는지 궁금해한다. 본 논문은 이 문제를 연구하고 SelfMatch라고 불리는 TSC에 대한 기존의 준지도 학습(SSL) 기법을 단순화하는 자기 증류(SD)를 가진 강력한 준지도 모델을 제안한다. 셀프매치는 지도 학습, 비지도 학습 및 SD를 혼합한다. 비지도 학습에서 SelfMatch는 레이블링된 데이터의 피쳐 추출에 의사 레이블링을 적용한다. 약한 증강 시퀀스는 동일한 시퀀스의 타임컷 증강 버전의 예측을 안내하는 대상으로 사용된다. SD는 낮은 수준의 의미 정보 추출을 안내하면서 더 높은 수준에서 더 낮은 수준으로의 지식 흐름을 촉진한다. 이 논문은 기능 및 관계 추출을 담당하는 ResNet-LSTMaN라고 불리는 TSC용 기능 추출기를 설계한다. 실험 결과는 셀프매치가 다수의 최첨단 준감독 및 감독 알고리듬과 비교하여 널리 채택된 35개의 UCR2018 데이터 세트에서 우수한 SSL 성능을 달성한다는 것을 보여준다.
Introduction
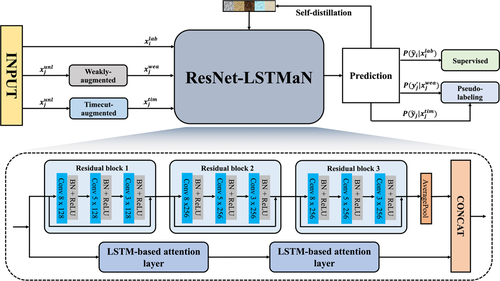
SelfMatch는 지도 학습, 비지도 학습 및 SD를 우아하게 통합하여 시계열 데이터에 숨겨진 표현을 탐색한다. 대부분의 감독 알고리듬과 마찬가지로, SelfMatch는 레이블이 지정된 데이터에 대한 교차 엔트로피 손실 함수를 사용하여 예측 벡터를 실제 레이블로 안내한다. 감독되지 않은 학습 측면에서, 우리는 FixMatch의 pseudo-labeling 기술을 적용하여 레이블링되지 않은 데이터 범주 간의 관계를 캡처한다. 시계열 데이터는 이미지 데이터와 다르기 때문에 FixMatch의 데이터 확대 방법을 TSC에 직접 적용할 수 없습니다. SelfMatch는 “약하게”와 “시간 단축”의 두 가지 범주의 증강을 사용한다 인공 레이블은 약하게 증강된 시퀀스(예: 원시 데이터에 가우스 함수를 추가하여)를 기반으로 획득되며 모델에 동일한 시퀀스의 타임컷 증강 버전이 제공될 때 대상으로 간주된다. 타임컷 증강 방법은 주어진 시퀀스의 왜곡된 버전을 생성하기 위해 시계열 데이터에서 컷아웃의 수정된 버전이다. FixMatch에 이어 충분히 큰 확률이 가능한 클래스 중 하나에 할당된 경우에만 인공 레이블을 유지한다. 한편, 지식 흐름을 더 높은 수준에서 더 낮은 수준으로 안내하기 위해 BYOT의 연결 접근법을 사용한다. 즉, 출력 계층에서 얻은 지식은 더 낮은 수준에서 각 블록에서 출력되는 지식을 감독하는 역할을 한다. SelfMatch의 개요는 그림 1에 나와 있다.
Contribution
- 우리는 SelfMatch의 기능 추출기, 즉 그림 1의 ResNet LSTMaN으로 잔류 네트워크(ResNet)와 LSTM 기반 주의 네트워크(LSTMaN)를 결합한다. ResNet과 LSTMaN은 각각 데이터의 로컬 및 글로벌 패턴을 추출하는 역할을 한다.
- 우리는 출력 계층에서 얻은 의미 정보에 의한 하위 수준의 의미 정보 추출을 감독하기 위해 SD 기술을 적용한다.
- 실험에 따르면 TSC에 대한 여러 SSL 알고리듬과 비교하여 레이블이 지정된 데이터가 교육 데이터의 10%만 차지할 때 SelfMatch는 UCR2018 아카이브에서 선택된 35개의 데이터 세트 중 24개를 획득한다. 레이블이 지정된 데이터가 교육 데이터의 30%를 차지할 때, 셀프매치의 성능은 35개의 UCR 데이터 세트에서 최악의 감독 알고리듬, 즉 Fast Shaplets(FS)에 가깝다.
Proposed Method
SelfMatch
SelfMatch는 그림 1과 같이 지도 학습, 비지도 학습, SD로 구성되어 있습니다. ResNet –LSTMaN은 기능 추출기이며, ResNet은 로컬 패턴 마이닝에 초점을 맞추고 LSTMaN은 글로벌 패턴을 발견하는 역할을 한다. 대부분의 감독 알고리듬과 마찬가지로 이 연구는 교차 엔트로피 손실 함수를 사용하여 레이블이 지정된 데이터의 예측 벡터와 지상 실측값 레이블 사이의 차이를 계산한다. 감독되지 않은 학습 측면에서 셀프매치는 레이블이 없는 데이터에서 풍부한 표현을 캡처하기 위해 높은 신뢰도의 예측을 가진 의사 레이블링을 적용하며, 여기서 모델이 동일한 시퀀스의 타임컷 증강 버전을 제공할 때 약하게 증강된 시퀀스를 채택하여 인공 레이블을 생성한다. 마지막으로, 이 논문은 L1 손실 기능이 있는 SD를 사용하여 높은 수준의 블록에서 낮은 수준의 블록으로의 지식 전달을 촉진한다
Data Augmentation
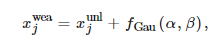
위의 수식으로 weakly augmented sequence를 얻을 수 있다.
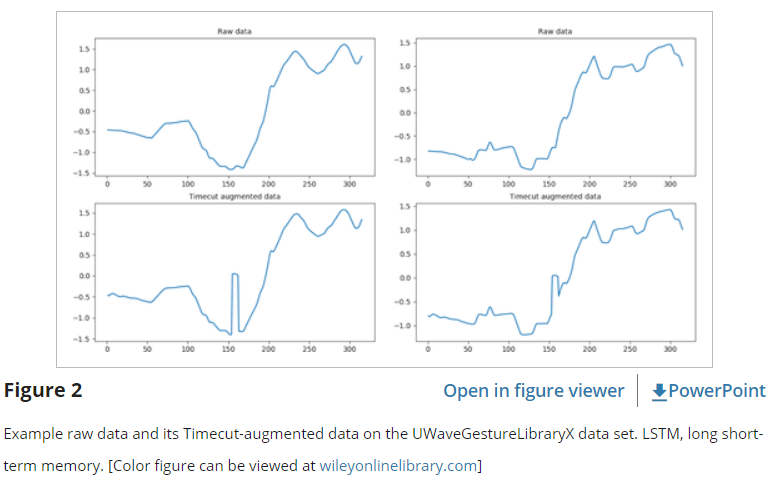
반면, 타임컷 증강 시퀀스인 x_tim은 전체 추세를 변경하지 않고 레이블이 지정되지 않은 원시 데이터의 작은 부분을 무작위로 변경하는 컷아웃 기술의 수정된 버전이다. 그림 2는 UWaveGestureLibraryX 데이터 세트의 원시 데이터와 결과 타임컷 증강 데이터의 샘플을 보여줍니다.
Lstm-based attention layer
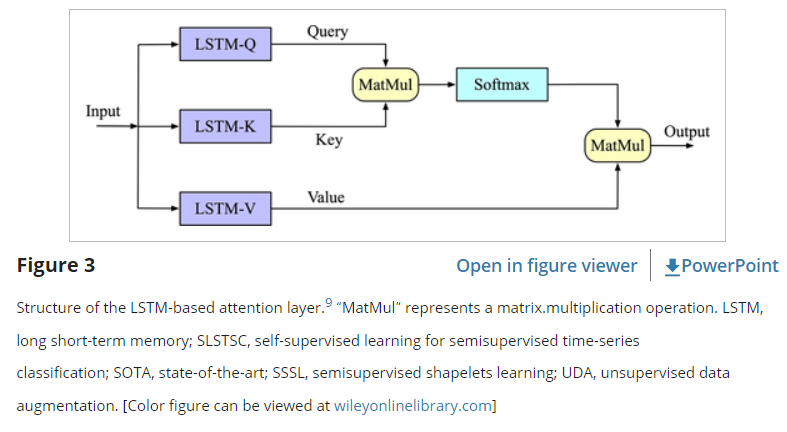
최근, 두 개의 LSTM 기반 주의 계층으로 구성된 LSTMaN은 다양한 일변량 및 다변량 시계열 데이터 세트에서 적절한 성능을 달성했다. 이 네트워크는 비주기적 데이터의 글로벌 변형에 초점을 맞춰 기본 기능 간의 의미 있는 관계를 추출했다. 이 논문은 LSTMaN을 ResNetLSTMaN에 관계 추출 네트워크로 통합한다. 첫 번째 계층은 입력에서 기본 관계를 마이닝하는 반면, 두 번째 계층은 이전에 캡처한 관계 중에서 복잡한 표현을 추출한다.
Self-Distillation
SD는 특별한 교사-학생 모델입니다. 그 자체는 교사이면서 동시에 학생이며, 높은 수준의 블록에서 낮은 수준의 블록으로 지식을 이전한다. SelfMatch에 대한 SD loss는 아래 수식과 같다.
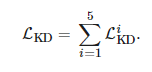
Experiment
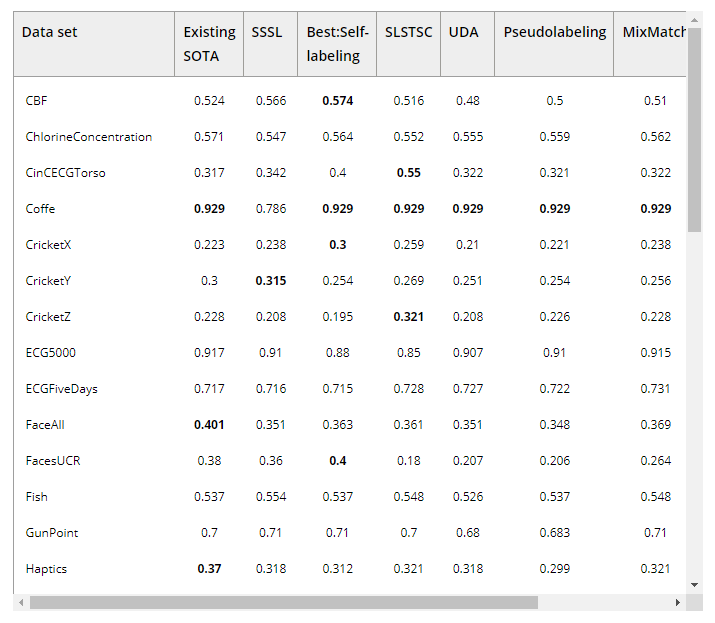
첫째, SelfMatch는 모든 SSL 알고리즘 중에서 가장 높은 평균 ACC 및 “최상” 값(즉, 0.600 및 24)을 얻고 가장 작은 AVG_rank 점수(즉, 1.843)를 획득하여 가장 우수한 성능을 발휘합니다. SelfMatch는 위의 네 가지 주류 SSL 기술을 활용하여 레이블이 지정되지 않은 데이터에서 얻은 클래스 표현 간의 본질적인 연결을 캡처합니다. 한편, SelfMatch는 SD를 활용하여 출력 계층에서 얻은 의미 정보에 의한 하위 수준의 의미 정보 추출을 안내한다. 하위 수준에서 기능 추출 기능을 향상시키면 상위 수준에 더 의미 있는 정보를 제공하는 데 도움이 됩니다. AVG_rank 및 MeanACC 값에 따르면 믹스매치의 성능은 모든 앙상블 기반 알고리즘 중에서 최악입니다. 그러나 최고의 비앙상블 기반 알고리듬인 기존 SOTA보다 성능이 뛰어나다. 이 현상은 여러 SSL 기술을 앙상블하는 것이 레이블이 지정되지 않은 데이터를 처리하는 데 유용하다는 것을 의미한다. 반면, UDA는 데이터 증강 및 일관성 훈련만 사용되기 때문에 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터 내의 숨겨진 표현을 효과적으로 추출하기 어렵다. 이것이 UDA가 “최고”, MeanACC 및 AVG_rank 값 측면에서 모든 비교 알고리즘 중에서 최악의 성능을 발휘하는 이유이다.
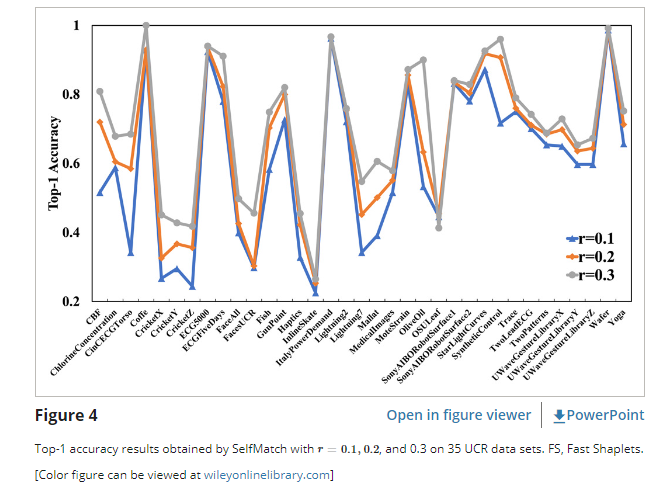
둘째, r이 SelfMatch에 미치는 영향을 연구하기 위해, 우리는 그림 4의 35개 UCR 데이터 세트에 대해 r=0.1, r=0.2 및 0.3으로 SelfMatch에서 얻은 상위 1개의 정확도 결과를 보여준다. 레이블이 지정된 데이터가 많을수록 모델에 더 많은 사전 지식이 제공되므로 셀프매치가 데이터에 숨겨진 더 풍부한 규정과 연결을 추출하는 데 도움이 됩니다. 레이블이 지정된 데이터가 많을수록 셀프매치의 성능이 점차 향상되는 이유다.
Conclusion
SelfMatch는 4가지 주요 SSL 기술과 SD를 혼합합니다. 여기서 ResNet은 다음과 같습니다LSTMaN은 특징 추출기의 역할을 한다. 이러한 SSL 기술은 레이블이 지정되지 않은 데이터에서 얻은 클래스 표현 사이의 본질적인 연결을 마이닝하는 데 민감하다. SD는 출력 계층에서 캡처된 의미 정보에 의해 하위 수준의 의미 정보 추출 프로세스를 감독한다.
ResNet_LSTMaN은 로컬 및 글로벌 데이터 패턴을 모두 강조하여 SelfMatch에 충분한 표현을 제공한다. 실험 결과에 따르면 레이블이 지정된 데이터가 교육 데이터의 10%만 차지할 때 SelfMatch는 35개의 UCR 데이터 세트 중 24개를 획득한다. 레이블링된 데이터가 교육 데이터의 30%를 차지할 때, 35개의 UCR2018 데이터 세트에서 셀프매치의 성능은 감독 알고리듬인 FS의 성능에 매우 근접하여, 셀프매치가 실제 TSC 문제에 적용될 수 있음을 보여준다.
또한 셀프매치에는 많은 중요한 하이퍼 파라미터가 존재하기 때문에 각 데이터 세트에서 셀프매치의 최적의 성능을 얻기 위해 이러한 하이퍼 파라미터를 적절하게 설정하는 것은 상당히 어렵다. 향후 최적의 하이퍼 파라미터 설정을 자동으로 검색하는 자동 기계 학습(예: 신경 아키텍처 검색) 방법을 도입할 계획이다.