Efficient time series anomaly detection by multiresolution self-supervised discriminative network (2022) 리뷰
Abstract
시계열 이상 탐지는 전체 시퀀스의 시간적 행동과 현저하게 다른 시계열의 비정상적인 시퀀스를 식별하는 것을 목표로 한다. 이전의 density 기반 또는 proximity 기반 이상 탐지 방법은 일반적으로 이상 탐지에 사용되지만, 테스트 중에 전체 교육 데이터 세트를 통과해야 하기 때문에 여전히 높은 계산 비용으로 어려움을 겪고 있다.최근에는 시계열 이상 탐지에 재구성 기반 딥 러닝 방법이 인기를 끌고 있다.
그러나 고주파 노이즈를 포함하여 시계열에 나타나는 모든 정보를 복구하는 것이 목표이기 때문에 잘 작동하지 않을 수 있습니다. 본 논문에서는 효율적인 시계열 이상 탐지를 위한 Multiresolution Self-Supervised Discriminative Network(MS2D-Net)라는 간단하면서도 효율적인 방법을 제안한다. 구체적으로, MS2D-Net은 Multiresolution 다운샘플링 모듈, feature extraction 모듈 및 self-supervised discriminative 모듈을 포함한다. Multiresolution 다운샘플링 모듈은 서로 다른 샘플링 속도로 원래 시계열을 다운샘플링하여 일부 다중 해상도 샘플을 생성하고 시계열에서 다중 스케일 동작을 나타내는 서로 다른 pseudo-label을 생성한다. 그런 다음 feature extraction 모듈에서 얕은 컨볼루션 네트워크를 사용하여 시계열의 temporal dynamics을 여러 해상도로 추출한다. 마지막으로,self-supervised discriminatio 모듈은 다중 해상도 다운샘플링 모듈에서 얻은 pseudo-label을 자기 지도 정보로 사용하여 정상 시계열 샘플에서 이상 징후를 분리하는 데 도움이 된다. 실험 결과는 제안된 MS2D-Net이 훨씬 낮은 계산 비용으로 시계열 이상 탐지를 위한 18개 벤치마크에서 최근의 강력한 딥 러닝 기준선을 능가할 수 있음을 보여준다.
Introduction
강력한 비지도 학습 프레임워크로서, self-supervised 방법은 object detection and segmentation을 포함하여 컴퓨터 비전 작업에 성공적으로 적용되었다. 주요 아이디어는 주어진 데이터에 대한 강력한 표현을 학습하는 데 도움이 되는 효율적인 보조 작업을 설계하는 것이다. 인기 있는 보조 자체 감독 작업(예: 분류)은 이미지 회전, 픽셀 순열 및 변환을 포함한 이미지 확대 작업을 기반으로 한다. 최근에는 이미지 이상 감지 작업에 self-supervised 기법이 적용되고 있다. 적합한 보조 분류 작업을 도입함으로써 이미지 데이터의 정상 패턴은 self-supervised 판별기에 의해 쉽게 캡처될 수 있다. 우리가 아는 한, self-supervised 방법은 시계열 이상 탐지에서 아직 탐구되지 않았다. 시계열에서 self-supervised 기법을 직접 사용하기 어려운 주요 어려움 중 하나는 우리가
이미지 변환과 같은 유익한 시계열 augmentation 전략을 명확하게 정의할 수 없다는 것이다. 부적절한 augmentation 변환은 시계열의 정규 시간 패턴을 쉽게 손상시키고 잘못된 모델 훈련에 추가적인 노이즈를 초래할 수 있다.
본 논문에서, 우리는 시계열의 multiresolution temporal information가 시계열 이상 탐지를 위해 일종의 self-supervision information를 사용할 수 있다고 주장한다. 구체적으로, 우리는 다중 해상도 자체 감독 차별 네트워크(MS2 D-Net)라는 간단하면서도 효율적인 모델을 제안한다. 제안된 모델은 i) 다중 해상도 다운샘플링 모듈, ii) 얕은 컨볼루션 네트워크 기반 기능 추출 모듈 및 iii) 자체 감독 판별 모듈의 세 가지 기본 구성 요소로 구성된다. 다중 해상도 다운샘플링 모듈은 (다른 다운샘플링 속도에 의해) 다른 시간 해상도로 증강 샘플을 생성합니다. 각 증강 샘플에 대해 의사 레이블은 해당 다운샘플링 속도에 의해 할당된다. 그 후 얕은 컨볼루션 기반 특징 추출 모듈을 기반으로 각 다운샘플링 시계열에 대한 시간적 표현을 추출할 수 있다. 마지막으로, 선형 매핑 기반 자체 감독 판별 모듈은 감독 방식으로 학습할 수 있다. 직관적으로, 이 자체 감독 판별 모듈은 다양한 시간 분해능에서 정상 패턴을 설명하는 것을 목표로 한다. 비정상 인스턴스를 테스트할 때, 자체 감독 판별 모듈은 일부 해상도 수준에서 판별 신뢰도가 감소하기 때문에 비정상 인스턴스의 패턴을 판별하지 못합니다. 따라서 변칙 점수의 지표로 discrimination confidence을 사용할 수 있다.
우리는 그림 2에서 기존 재구성 프레임워크와 제안된 차별적 프레임워크 사이의 주요 차이점을 강조한다. 알 수 있듯이 재구성 프레임워크는 원래 시간 순서 공간에서 시계열 기능만 캡처합니다. 그러나, 그것의 성능은 종종 선택된 인코더와 디코더의 피팅 용량에 의해 제한된다. 다르게, 우리가 제안한 차별적 프레임워크는 보조 다중 해상도 자체 감독 작업으로 정규성을 설명하며 복잡한 비선형 시계열을 재구성할 필요가 없다.
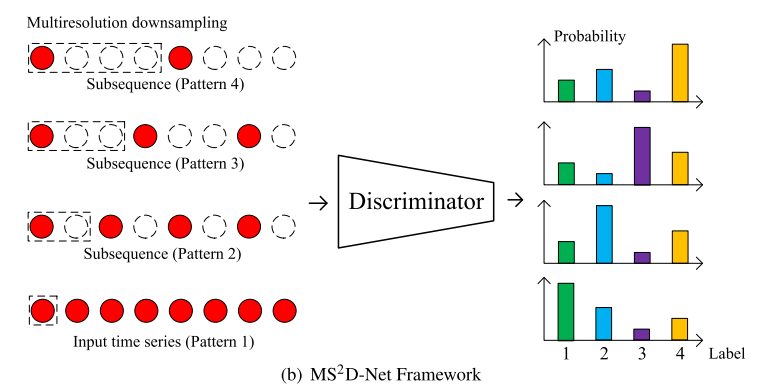
Contribution
- 우리는 다중 해상도 자체 감독 차별 네트워크(MS2 D-Net)라는 새로운 모델을 제안한다. 제안된 MS2 D-Net은 복잡한 비선형 시계열을 auto-encoding하거나 self-predict할 필요가 없으므로 시계열 이상 징후 감지에 효과적이다.
- 다중 해상도 자체 감독 체계는 다중 해상도에서 시계열의 정상적인 특성을 모델링하기 위해 개발된다;
- 제안된 모델은 더 낮은 계산 비용으로 18개의 시계열 이상 탐지 작업에서 최고의 평균 성능을 달성한다. 시각화, 초 매개 변수 민감도 및 계산 효율성에 대한 자세한 분석도 제안된 방법의 효과를 검증한다.
Proposed Method
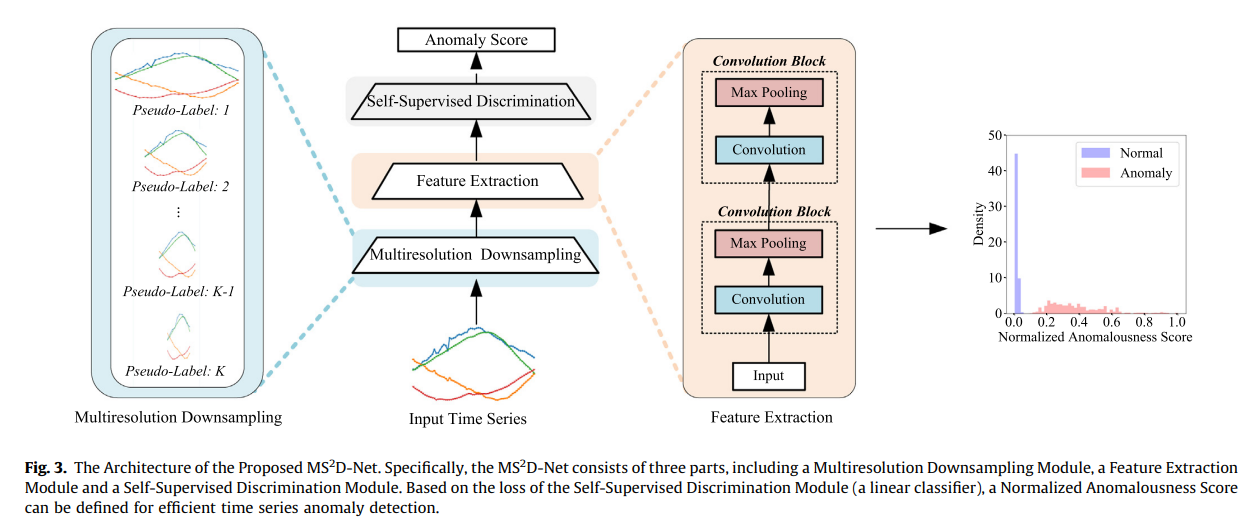
Multiresolution Downsampling Module
시계열의 경우 일, 주, 월 등과 같은 다른 시간 분해능에서 항상 설명할 수 있습니다. 이러한 관찰을 바탕으로, 우리의 다중 해상도 다운샘플링 모듈은 여러 시간 해상도에서 간단한 다운샘플링 전략을 통해 유익한 자체 감독 정보를 직접 추출한다. 또한 해당 다운샘플링 속도는 훈련을 위한 의사 레이블로 사용될 것이다.
이러한 유사 레이블을 기반으로, 모든 다운샘플링된 샘플은 범주 1;2;……K의 분포에서 가정할 수 있습니다. 그런 다음 원래의 이상 탐지 문제는 supervised discrimination 문제로 던져질 수 있다. 우리의 다중 해상도 자체 감독 판별 프레임워크는 다중 해상도 다운샘플링을 기반으로 하기 때문에, 얻은 다운샘플링 인스턴스 {X_i^f}는 다양한 길이를 가지고 있다. 구현을 용이하게 하기 위해, 우리는 그림 4와 같이 모든 데이터가 동일한 길이를 갖도록 동일하지 않은 길이의 샘플 끝에 0을 패딩한다. 제로 패딩 후에도 모든 인스턴스가 동일한 길이를 갖지만 다양한 시간 척도와 다른 시간적 특성을 여전히 보여준다.
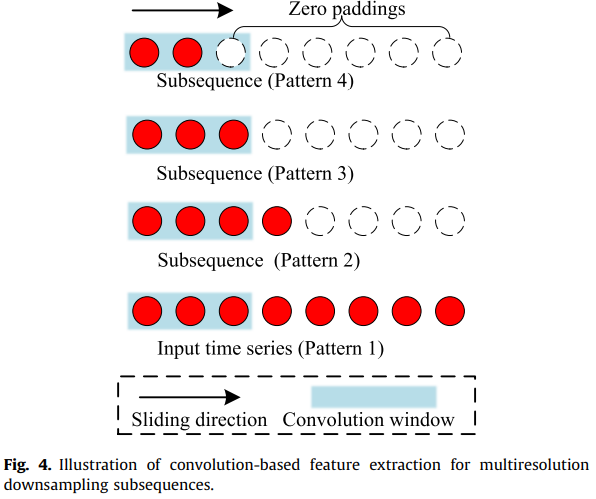
Feature Extraction Module
컨볼루션 신경망은 기능 학습에서 우수성을 보여주었다. 우리의 특징 추출 모듈은 얕은 컨볼루션 신경망을 기반으로 한다. 그림 3에 나타난 바와 같이, 우리는 우리의 특징 추출 모듈에서 두 개의 컨볼루션 블록을 사용하고 각각은 컨볼루션 레이어와 최대 풀링 레이어로 구성된다.
Self-Supervised Discriminative Module
제안된 방법은 K 시간 분해능에 해당하는 K 유사 레이블이 있는 여러 다운샘플링 인스턴스에 대한 교차 엔트로피 손실을 기반으로 한다. 다음으로, 우리는 시계열 이상 탐지를 위해 훈련된 다중 해상도 자체 감독 판별 모듈을 사용하는 방법을 명확히 하기 위해 이상 점수 공식을 공식적으로 제공할 것이다.
Anomaly Score
test데이터에 대한 anomaly score는 아래 수식과 같이 구할 수 있다.
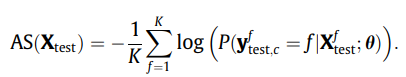
정규화된 버전의 anomaly score는 아래와 같다.
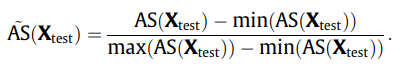
또한, 전체 프로세스에 대한 수도코드는 아래와 같다.

Experiment
Dataaset
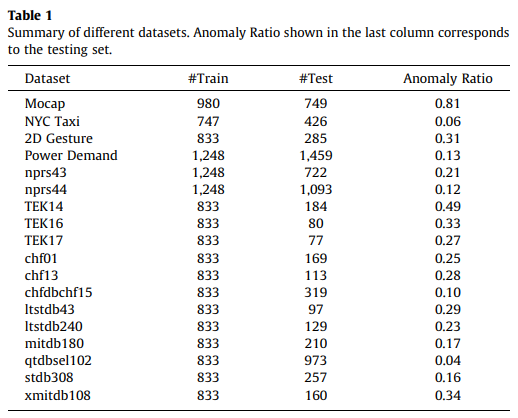
- 모션 캡처 데이터 세트2는 걷기, 등산, 달리기 등 여러 피사체가 수행하는 다양한 모션을 포함한다.
- NYC 택시 승객 수 데이터 세트[44]는 30분 간격으로 집계되는 뉴욕시 택시 승객 데이터 스트림을 수집한다.
- 2D 제스처 데이터 세트[16]는 장시간 비디오에서 손 제스처의 X-Y 좌표를 포함한다.
- 전력 수요 데이터 세트[16]는 1997년 전체 네덜란드 연구 시설의 전력 소비를 측정한 실제 전력 수요 데이터 세트이다.
- 호흡[16]에는 두 개의 데이터 세트(nprs43 및 nprs44)가 포함되며, 각 데이터 세트는 흉부 확장에 의해 측정된 환자의 호흡을 수집하며 샘플링 속도는 10Hz이다.
- 우주왕복선[16]에는 세 개의 데이터 세트(TEK14, TEK16, TEK17)가 포함되어 있으며, 각 데이터 세트에는 NASA 엔지니어가 주석을 달았던 우주왕복선 마로타 밸브 시계열이 포함되어 있다.
- 심전도(ECG)[16]에는 9개의 실제 데이터 세트(chf01, chf13, chfdbchf15, ltstdb43, ltstdb240, mitdb180, qtdbsel102, stdb308 및 xmitdb108)가 포함되어 있으며, 각각은 심실 전 수축에 해당하는 단일 이상 결과를 포함한다.
교육 전에 Mocap 데이터 세트를 사전 처리하기 위한 BeatGAn에서 권장하는 방법을 따른다. 각 데이터 세트에 대해 슬라이딩 창을 사용하여 시계열 세그먼트를 추출한다. 특히, 전력 수요 및 호흡 데이터 세트의 경우, 훈련 데이터 세트에서 슬라이딩 단계가 80인 크기 200의 창을 사용한다. 다른 데이터 세트의 경우, 우리는 (훈련 데이터 세트에서) 120의 슬라이딩 단계와 함께 160의 창을 사용한다. 테스트 데이터 세트의 경우 슬라이딩 단계가 10으로 설정되어 테스트 데이터 세트의 크기가 적절한 크기로 유지될 수 있다. 세그먼트 내에 이상 타임스탬프가 있으면 샘플이 비정상으로 간주됩니다.
OCSVM 및 LOF와 같은 전통적인 이상 탐지 방법은 일반적으로 (시간 데이터보다) 정적 특징에 초점을 맞추고 있지만, 여전히 시간 종속성을 무시하여 시계열을 고차원 특징 벡터로 취급할 수 있다. 이러한 이유로, 우리는 또한 이러한 전통적이지만 인기 있는 기계 학습 기준선을 제안된 모델과 비교한다. 비교의 공정성을 위해 동일한 슬라이딩 창을 사용하여 시계열을 해당 정적 피처 벡터로 변환한다.
Evaluation Metrics
평가를 위해, 우리는 두 가지 일반적으로 사용되는 메트릭, 즉 수신기 작동 특성 곡선 아래 영역(AUROC)[47]과 정밀 호출 곡선 아래 영역(AUPR)[47]을 사용한다. AUROC는 참 긍정, 참 부정, 거짓 긍정 및 거짓 부정 사이의 균형을 반영한다. 우리는 또한 특이치를 양의 클래스로 사용하는 경우인 AUPR 메트릭을 사용한다. AUROC 및 AUPR 값이 높을수록 성능이 향상됩니다. 두 가지 모두 이상 탐지 작업에 널리 사용되는 메트릭이다[36].
직관적으로, AUROC는 양의 샘플과 음의 샘플이 각각 변칙 샘플과 정상 샘플에 해당하는 양의 샘플과 음의 샘플 사이의 순열을 예측하기 위한 모델의 정확성을 나타낸다. 양의 샘플의 예측 순열이 음의 순열보다 먼저 순위를 매길 때, 그것은 좋은 모델 추론으로 간주된다. 이상 점수가 AS이고 AUROC 메트릭은 아래 수식과 같이 계산할 수 있는 동안 시험 단계에 m개의 양성 샘플과 n개의 음성 샘플이 있다고 가정한다.
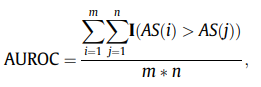
AUPR 메트릭은 곡선 아래의 영역에 해당하며, 방법에 대한 양성 검체의 정밀도 및 회수에 의해 구성됩니다. AUPR 메트릭은 일반적으로 정상 샘플 또는 비정상 샘플을 양의 샘플로 나타내는 AUPR-in과 AUPR-out의 두 가지 특정 지표를 포함한다. 중요한 것은 AUPR-out(이 논문에서 보여주는 AUPR)은 무작위 추측이 (대부분의 상황에서 작은) AUPR 메트릭에 대한 이상 비율을 얻는 반면, 무작위 추측은 AUPR 메트릭에 대해 0.5 점수를 얻기 때문에 다양한 이상 탐지 방법을 평가하는 데 더 우수하다는 것이다. 이 논문에서, 우리는 또한 부록에 AUPR-in 결과를 제시한다.
Results and Analysis
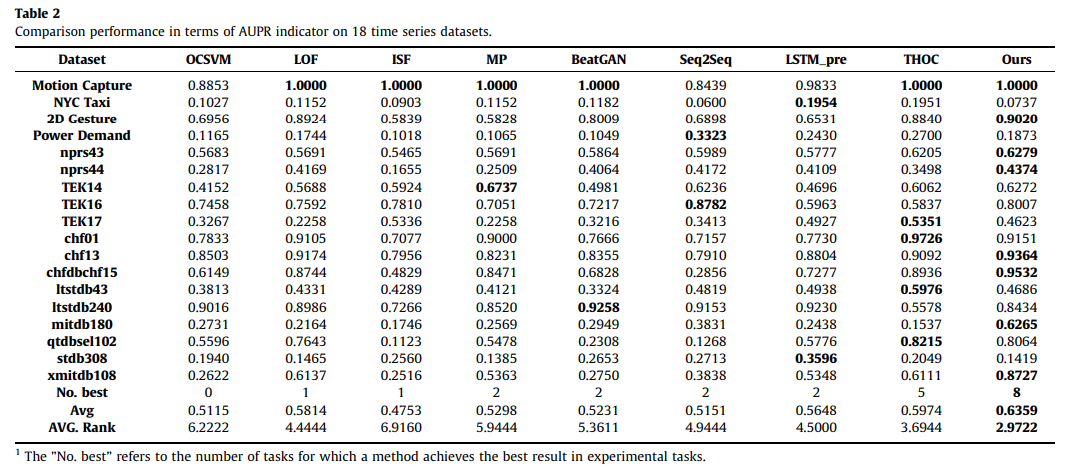
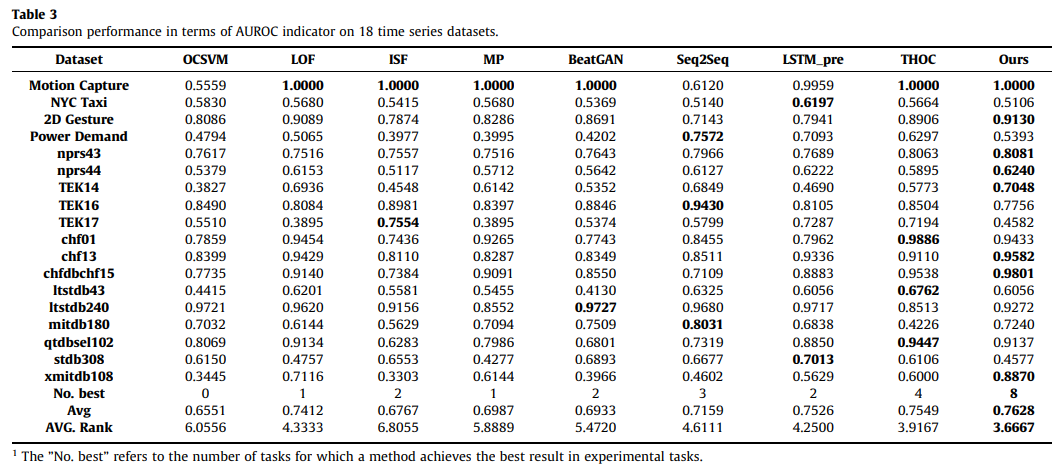
알 수 있듯이, 우리의 MS2 D-Net은 18개 작업 중 8개 작업에서 최고의 성능을 달성하고 모든 기준선 중에서 가장 높은 순위를 달성하여 그 효과를 입증한다. 결과에 따라 다음과 같은 결론을 추가로 도출할 수 있습니다:
a) MS2 D-Net은 기존의 기계 학습 이상 탐지 방법과 비교하여 평균 정확도 측면에서 이를 능가한다. MP와 LOF는 OCSVM과 ISF보다 더 나은 성능을 보이지만(평균 순위가 더 높은), 여전히 두 가지 문제로 인해 쉽게 어려움을 겪는다. 첫 번째는 테스트하는 동안 모든 훈련 샘플을 통과해야 한다는 것입니다. 또 다른 한계는 MP가 시계열 왜곡에 제한되는 거리 정렬에 기반한 방법이라는 것이다. 우리의 MS2 D-Net은 한 번에 테스트 세트를 추론하고 다중 해상도 다운샘플링 모듈에 의한 로컬 시계열 왜곡을 부드럽게 할 수 있다.
b) MS2 D-Net은 기존 딥러닝 기반 기준선보다 우수하다. 기준 LSTM_predictor와 비교하여 MS2 D-Net은 AUPR에서 약 7%, AUROC에서 약 1% 향상될 수 있다. LSTM_predicator의 회귀 용량은 정상 패턴을 구별하기 위한 정상 샘플을 모델링하기 어려운 반면, MS2 D-Net은 다중 해상도 방식으로 정상 패턴을 인식하여 비정상 패턴과 정상 패턴을 구별하는 데 좋은 성능을 낸다.
c) 기준선 Seq2Seq 및 BeatGAN과 비교하여 MS2 D-Net은 여전히 큰 개선을 보여준다. Seq2Seq는 비트 동안 반복 신경망의 회귀 용량에 의해 쉽게 제한된다GAN은 불안정한 적대적 훈련으로 어려움을 겪고 있다. 이 두 가지 방법과 달리, 우리의 MS2 D-Net은 간단하지만 효율적인 자체 감독 식별 프레임워크이다. 회귀 모델링이나 적대적 훈련에 의존하지 않는다. 정상 데이터로부터 다중 해상도 자체 감독 정보를 학습함으로써 정상성을 효과적으로 설명할 수 있다.
d) 최근의 강력한 기준 THOC에 비해 우리의 MS2 D-Net은 여전히 AUPR에서 약 4%, AUROC 지표에서 약 1% 향상된 것으로 나타났다. 이는 THOC의 클러스터링 공간도 비정상적인 패턴과 정상적인 패턴을 구별하기 어렵다는 것을 의미한다. 반대로 MS2 D-Net의 다중 해상도 다운샘플링 공간은 정상 샘플을 모델링하는 데 더 적합하며, 이는 모델이 비정상 패턴과 정상 패턴을 구별하는 데 도움이 된다.
Conclusion
본 논문에서는 훨씬 낮은 계산 비용으로 변칙적인 시계열 결과를 식별할 수 있는 다중 해상도 자체 감독 판별 네트워크(MS2D-Net)를 개발하였다. 다중 해상도 다운샘플링 전략을 자체 감독 차별 학습과 통합하여 높은 계산 효율성을 달성한다. 기존 시계열 탐지 방법과 비교하여 제안된 모델은 재구성(또는 자체 예측)에 의존하지 않는다. 실험에서, 우리는 18개의 시계열 이상 탐지 작업에서 우수성을 입증한다.