논문 링크 : https://proceedings.neurips.cc/paper_files/paper/2015/hash/11d0e6287202fced83f79975ec59a3a6-Abstract.html
Abstract
기계 학습의 성공이 다양한 분야에서의 수요를 촉진시키고 있으며, 이로 인해 비전문가들도 쉽게 사용할 수 있는 기계 학습 시스템의 필요성이 증가하고 있다. 이러한 시스템이 실제로 효과적이려면 새로운 데이터셋에 대해 적절한 알고리즘과 특성 전처리 단계를 자동으로 선택하고, 해당 하이퍼파라미터를 설정할 수 있어야 한다.
최근의 연구에서는 효율적인 베이지안 최적화 방법을 활용하여 이러한 자동 기계 학습(AutoML) 문제를 해결하려는 시도가 시작되다. 이를 바탕으로, 저자들은 scikit-learn을 기반으로 하는 강력한 새로운 AutoML 시스템을 소개하고 있으며, 이 시스템은 15개의 분류기, 14개의 특성 전처리 방법, 그리고 4개의 데이터 전처리 방법을 사용하여 110개의 하이퍼파라미터로 구성된 구조화된 가설 공간을 제공한다.
이 시스템은 AUTO-SKLEARN이라고 불리며, 기존의 AutoML 방법들을 개선하고 있다. 이는 유사한 데이터셋에서의 과거 성능을 자동으로 고려하고, 최적화 과정에서 평가된 모델들로부터 앙상블을 구성함으로써 달성됩니다. 이 시스템은 진행 중인 ChaLearn AutoML 챌린지의 첫 번째 단계에서 우승했으며, 100개가 넘는 다양한 데이터셋에서의 포괄적인 분석 결과, 이전의 AutoML 기술에 비해 훨씬 뛰어난 성능을 보여준다고 한다. 또한, 각 기여에 따른 성능 향상과 AUTO-SKLEARN의 개별 구성 요소의 효과를 분석하여 설명하고 있다.
Introduction
최근 기계 학습(machine learning)이 많은 응용 분야에서 큰 진전을 이루면서 기계 학습 시스템에 대한 수요가 증가하고 있음을 설명하고 있습니다. 이에 따라, 기계 학습을 비전문가들이 효과적으로 사용할 수 있도록 지원하는 것을 목표로 하는 상업적 기업들이 늘고 있다. 예를 들어 BigML.com, Wise.io, SkyTree.com, RapidMiner.com, Dato.com, Prediction.io, DataRobot.com, Microsoft의 Azure Machine Learning, Google의 Prediction API, Amazon Machine Learning 등이 있다.
기계 학습 서비스의 핵심은 주어진 데이터셋에 사용할 기계 학습 알고리즘을 결정하고, 특성을 전처리할지 여부와 방법을 결정하며, 하이퍼파라미터를 어떻게 설정할지를 결정하는 기본적인 문제들을 해결하는 데 있다. 더 구체적으로, 이 연구는 자동 기계 학습(AutoML)을 살펴봅니다. AutoML은 새로운 데이터셋에 대해 사람의 입력 없이 테스트 세트 예측을 생성하는 문제로, 고정된 계산 budget 내에서 이루어진다.
AutoML 문제는 공식적으로 아래와 같이 정의된다.
Definition 1 (AutoML problem)
- Train Dataset
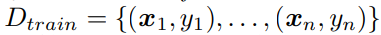
- Test dataset
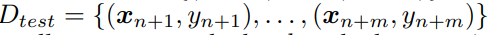
- loss of a soltion
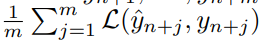
- budget b
computational resources, such as CPU, wallclock time, memory usage 등이 있다. - F : machine learning framework
Contribution
본 논문은 AutoML 접근방식을 다양한 방법으로 확장하여 그 효율성과 견고성을 크게 향상시키는데 기여하고 있다.
첫째로, 낮은 차원의 최적화 문제에 대한 이전의 성공적인 작업을 따라, 데이터셋 간에 추론하여 새로운 데이터셋에서 잘 수행되는 기계 학습 프레임워크의 인스턴스를 식별하고, 이를 바탕으로 베이지안 최적화를 warm start한다.
둘째, 베이지안 최적화에서 고려된 모델들의 앙상블을 자동으로 구축한다.
셋째, 인기있는 기계 학습 프레임워크인 사이킷런에 구현된 높은 성능의 분류기와 전처리기로부터 매우 매개변수화된 기계 학슴 프레임워크를 신중하게 설계한다.
마지막으로, 다양한 데이터셋 모음을 사용하여 광범위한 경험적 분석을 수행함으로써, 결과적으로 얻어진 AUTO-SKLEARN 시스템이 이전의 최첨단 AutoML 방법보다 뛰어난 성능을 보여주는 것을 입증함. 또한, 각 기여가 상당한 성능 향상을 가져오는 것을 보여주며, AUTO-SKLEARN에서 사용된 개별 분류기와 전처리기의 성능에 대한 통찰력을 얻음
AutoML as a CASH problem
AutoML의 형식화를 AUTO-WEKA의 AutoML 접근법에서 사용된 알고리즘 선택(Algorithm Selection)과 하이퍼파라미터 최적화(Hyperparameter Optimization)를 결합한 CASH 문제로 검토하는 것으로 시작한다 . AutoML에서 두 가지 중요한 문제는 (1) 단일 기계 학습 방법이 모든 데이터셋에서 최상의 성능을 내지 않는다는 것과 (2) 일부 기계 학습 방법들(예: 비선형 SVMs)이 하이퍼파라미터 최적화에 크게 의존한다는 것이다.
후자의 문제는 베이지안 최적화를 사용하여 성공적으로 해결되었으며, 현재 AutoML 시스템의 핵심 구성 요소로 자리잡고 있다. 전자의 문제는 하이퍼파라미터가 적절하게 조정되는지 여부에 따라 알고리즘의 순위가 달라지므로 후자의 문제와 서로 관련이 있다. 다행히도, 이 두 문제는 단일 구조화된 결합 최적화 문제로 효율적으로 해결될 수 있다.
Definition 2 (CASH)
CASH(Combined Algorithm Selection and Hyperparameter optimization)는 아래 손실을 최소화하는 알고리즘과 하이퍼파라미터 설정을 함계 찾는 것이다.
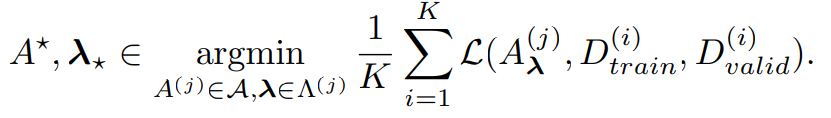
- A : set of Algorithm
- K : k-fold cross validation의 fold 수
CASH 문제는 처음으로 Thornton 등이 AUTO-WEKA 시스템에서 WEKA 머신 러닝 프레임워크와 트리 기반의 베이지안 최적화 방법을 사용하여 해결했다. 간단히 말해, 베이지안 최적화는 하이퍼파라미터 설정과 그들의 측정 성능 사이의 관계를 포착하는 확률 모델을 적합시키고, 이 모델을 사용하여 가장 유망한 하이퍼파라미터 설정을 선택한다(새로운 영역 탐색과 알려진 좋은 영역에서의 활용 사이의 균형을 맞추면서). 그 다음 해당 하이퍼파라미터 설정을 평가하고, 결과로 모델을 업데이트하고 반복한다. 가우시안 프로세스 모델을 기반으로 한 베이지안 최적화는 수치형 하이퍼파라미터를 가진 저차원 문제에서 가장 잘 작동하지만, 트리 기반 모델은 고차원, 구조화된, 부분적으로 이산적인 문제에서 더 성공적으로 적용됐다. CASH 문제와 같은 문제들은 이에 해당하며, HYPEROPT-SKLEARN이라는 AutoML 시스템에서도 사용된다.
트리 기반의 베이지안 최적화 방법 중에서 Thornton 등은 랜덤 포레스트 기반의 SMAC이 트리 Parzen 추정기 TPE보다 더 우수한 성능을 보인다고 발견했으며, 따라서 본 논문에서는 CASH 문제를 해결하기 위해 SMAC를 사용한다. 랜덤 포레스트를 사용하는 것 외에도, SMAC의 주요 특징은 한 번에 하나의 폴드를 평가하여 빠른 교차 검증을 가능하게 하고, 초기에 성능이 떨어지는 하이퍼파라미터 설정을 일찍 버리는 것이다.
New methods for increasing efficiency and robustness of AutoML
AutoML 접근법을 개선한 두 가지 방법론은 다음과 같다. 첫째, 메타러닝 단계를 포함하여 베이지안 최적화 과정을 웜스타트하는데, 이로 인해 효율성이 크게 향상된다. 둘째, 자동 앙상블 구성 단계를 포함하여 베이지안 최적화로 찾은 모든 분류기를 사용할 수 있도록 한다.

위의 그림은 두 가지 개선 사항을 포함하여 전체 AutoML 워크플로우를 요약하고 있다. 유연한 ML 프레임워크(예: 많은 알고리즘, 하이퍼파라미터, 전처리 방법을 제공하는)에 대해 이들의 효과가 더 크게 나타날 것으로 예상된다는 점을 언급한다.
Meta-learning for finding good instantiations of machine learning frameworks
도메인 전문가들은 이전 작업으로부터 지식을 추출한다: 그들은 기계 학습 알고리즘의 성능에 대해 배운다. 메타러닝(meta-learning) 분야는 데이터셋 간 학습 알고리즘의 성능에 대해 추론함으로써 이 전략을 모방한다. 이 연구에서는 새로운 데이터셋에서 잘 수행될 가능성이 높은 주어진 기계 학습 프레임워크의 실체를 선택하기 위해 메타러닝을 적용한다. 구체적으로 많은 수의 데이터셋에 대해 성능 데이터와 메타 특성(meta-features)을 수집한다. 여기서 메타 특성이란 효율적으로 계산할 수 있고 새로운 데이터셋에 어떤 알고리즘을 사용할지 결정하는 데 도움이 되는 데이터셋의 특성을 말한다.
이 메타러닝 접근법은 ML 프레임워크를 최적화하기 위해 베이지안 최적화와 상호 보완적이다. 메타러닝은 ML 프레임워크의 일부 구성 요소를 빠르게 제안할 수 있으며 이들이 상당히 잘 수행될 가능성이 높지만, 세밀한 성능 정보를 제공할 수는 없다. 반면에, 베이지안 최적화는 전체 ML 프레임워크와 같이 큰 하이퍼파라미터 공간에서 시작할 때 느리지만, 시간이 지남에 따라 성능을 미세 조정할 수 있다. 메타러닝을 기반으로 k개의 구성을 선택하고 그 결과를 사용하여 베이지안 최적화를 시작하는 이 방식을 통해 이 상호 보완성을 활용한다. 이러한 메타러닝에 의한 웜스타팅 최적화 접근법은 이미 성공적으로 적용되었다[4, 5, 6], 하지만 전체 ML 프레임워크의 구성 요소 공간을 검색하는 것처럼 복잡한 최적화 문제에는 적용되지 않았다. 마찬가지로, 데이터셋 간 학습은 협력적 베이지안 최적화 방법에서도 적용되었습니다[16, 17]; 이러한 접근법은 유망하지만, 아직 매우 적은 수의 메타 특성으로 제한되어 있고, AutoML에서 직면하는 고차원 부분 이산 구성 공간을 처리할 수 없다.
이 메타러닝 접근법은 ML 프레임워크를 최적화하기 위해 베이지안 최적화와 상호 보완적이다. 메타러닝은 ML 프레임워크의 일부 구성 요소를 빠르게 제안할 수 있으며 이들이 상당히 잘 수행될 가능성이 높지만, 세밀한 성능 정보를 제공할 수는 없다. 반면에, 베이지안 최적화는 전체 ML 프레임워크와 같이 큰 하이퍼파라미터 공간에서 시작할 때 느리지만, 시간이 지남에 따라 성능을 미세 조정할 수 있다. 메타러닝을 기반으로 k개의 구성을 선택하고 그 결과를 사용하여 베이지안 최적화를 시작하는 이 방식을 통해 이 상호 보완성을 활용한다. 이러한 메타러닝에 의한 웜스타팅 최적화 접근법은 이미 성공적으로 적용되었다[4, 5, 6], 하지만 전체 ML 프레임워크의 구성 요소 공간을 검색하는 것처럼 복잡한 최적화 문제에는 적용되지 않다. 마찬가지로, 데이터셋 간 학습은 협력적 베이지안 최적화 방법에서도 적용되었다[16, 17]; 이러한 접근법은 유망하지만, 아직 매우 적은 수의 메타 특성으로 제한되어 있고, AutoML에서 직면하는 고차원 부분 이산 구성 공간을 처리할 수 없다.
더 정확하게는, 우리의 메타러닝 접근법은 다음과 같이 작동한다. 오프라인 단계에서, 데이터셋 저장소의 각 기계 학습 데이터셋에 대해(우리 경우에는 OpenML 저장소의 140개 데이터셋), 메타 특성 세트를 평가하고 베이지안 최적화를 사용하여 해당 데이터셋에 대해 강력한 경험적 성능을 가진 주어진 ML 프레임워크의 구성 요소를 결정하고 저장한다. (자세히 말하면, 데이터의 3분의 2에서 10-겹 교차 검증으로 24시간 동안 SMAC을 실행하고, 나머지 3분의 1에서 최상의 성능을 보인 ML 프레임워크 구성 요소를 저장했다.) 그런 다음 새로운 데이터셋 D가 주어지면, 메타 특성을 계산하고, 모든 데이터셋을 메타 특성 공간에서 D와의 L1 거리로 순위를 매기고, 저장된 ML 프레임워크 구성 요소를 k=25 개의 가장 가까운 데이터셋에 대해 평가하기 전에 선택하여 베이지안 최적화를 시작한다.
데이터셋을 특징짓기 위해, 우리는 문헌에서 총 38개의 메타 특성을 구현했다. 이에는 데이터 포인트, 특성, 클래스의 수에 대한 통계, 데이터의 왜도 및 목표 변수의 엔트로피와 같은 단순한, 정보 이론적이고 통계적인 메타 특성[19, 20]이 포함된다. 모든 메타 특성은 부록의 표 1에 나열되어 있다. 눈에 띄게도, 유명하고 효과적인 랜드마킹 메타 특성[21] 카테고리(간단한 기본 학습 알고리즘의 성능을 측정하는 것)를 제외해야 했다. 왜냐하면 이것들은 온라인 평가 단계에서 도움이 되도록 계산하는데 너무 많은 비용이 들었기 때문이다. 이 메타러닝 접근법이 데이터셋 저장소의 가용성에서 그 힘을 얻는다는 점을 언급하는 것이 중요하며, 최근의 여러 이니셔티브(예: OpenML[18]) 때문에 시간이 지남에 따라 사용 가능한 데이터셋의 수가 계속 증가할 것으로 예상되며, 이로 인해 메타 학습의 중요성이 증가할 것이다.
Automated ensemble construction of models evaluated during optimization
베이지안 하이퍼파라미터 최적화는 최적의 하이퍼파라미터 설정을 찾는데 있어 데이터를 효율적으로 사용하지만, 좋은 예측을 만드는 것이 목표일 때는 매우 낭비적인 절차라는 것을 알 수 있다. 탐색 과정에서 훈련하는 모든 모델은 사라지며, 이 중 일부는 최적의 모델만큼 거의 효과적이다. 이러한 모델을 버리는 대신, 우리는 이들을 저장하고 효율적인 후처리 방법(실시간으로 두 번째 프로세스에서 실행할 수 있음)을 사용하여 이들로부터 앙상블을 구성하는 것을 제안한다. 이 자동 앙상블 구성은 단일 하이퍼파라미터 설정에 의존하지 않고, 따라서 표준 하이퍼파라미터 최적화가 제공하는 점 추정치를 사용하는 것보다 더 강건하며(과적합에 덜 취약)하다. 우리가 알기로, 우리는 이 간단한 관찰을 처음으로 제시하며, 이는 어떤 베이지안 하이퍼파라미터 최적화 방법을 개선하는 데 적용될 수 있다.
앙상블이 개별 모델들보다 종종 더 뛰어난 성능을 보이는 것은 잘 알려져 있으며, 모델 라이브러리로부터 효과적인 앙상블을 생성할 수 있다. 앙상블은 기반 모델들이 (1) 개별적으로 강하고 (2) 상관 없는 오류를 만들 때 특히 잘 수행된다. 개별 모델들이 성격이 다를 때 이것이 더 가능하기 때문에, 앙상블 구축은 유연한 ML 프레임워크의 강력한 구현을 결합하는 데 특히 적합하다.
그러나 베이지안 최적화로 찾은 모델들로 일정한 가중치를 가진 앙상블을 단순히 구축하는 것은 잘 작동하지 않는다. 대신, 우리는 개별 모델들의 예측을 사용하여 이러한 가중치를 조정하는 것이 중요하다고 발견했다. 우리는 이 가중치를 최적화하기 위해 다양한 접근법을 시도했습니다: 스태킹(stacking), 그래디언트가 없는 수치 최적화, 그리고 앙상블 선택(ensemble selection) 방법. 수치 최적화와 스태킹이 검증 세트에 과적합되는 경향이 있고 계산 비용이 많이 든다고 판단되는 반면, 앙상블 선택은 빠르고 강건했다. 간단히 말해서, 앙상블 선택(Caruana 등이 소개한)은 빈 앙상블에서 시작하여 반복적으로 앙상블 검증 성능을 최대화하는 모델을 추가하는 탐욕적인 절차이다(일정한 가중치로, 단 반복은 허용). 부록 자료의 절차 1에서 이를 자세히 설명하고 있다. 우리는 이 기술을 모든 실험에 사용했다 - 크기 50의 앙상블을 구축하는데 사용했다.
A paractical automated machine learning system
로버스트한 AutoML 시스템을 설계하기 위해, 기본 ML 프레임워크로는 scikit-learn [7]을 선택했다. scikit-learn은 가장 잘 알려지고 널리 사용되는 머신 러닝 라이브러리 중 하나로, 잘 정립되고 효율적으로 구현된 머신 러닝 알고리즘을 다양하게 제공하며, 전문가와 초보자 모두에게 사용하기 쉽다. 우리의 AutoML 시스템은 AUTO-WEKA와 매우 유사하지만, HYPEROPT-SKLEARN과 같이 scikit-learn 기반으로 작동하므로, 이를 AUTO-SKLEARN이라고 부른다. 그림 2는 AUTO-SKLEARN의 전체 구성 요소를 보여줍니다. 이 시스템은 15개의 분류 알고리즘, 14개의 전처리 방법, 그리고 4개의 데이터 전처리 방법을 포함한다. 각각을 매개변수화하여 총 110개의 하이퍼파라미터 공간을 생성했다. 이 중 대부분은 조건부 하이퍼파라미터로, 해당 구성 요소가 선택될 때만 활성화된다. SMAC [9]은 이러한 조건성을 기본적으로 처리할 수 있다.
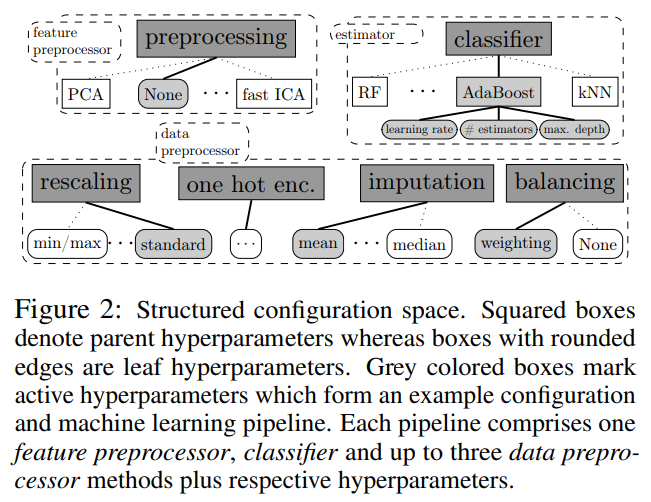
AUTO-SKLEARN에 있는 모든 15개의 분류 알고리즘은 Table 1a에 나열되어 있으며 (부록의 Section A.1에서 자세히 설명됨), 일반 선형 모델(2개의 알고리즘), 서포트 벡터 머신(2개), 판별 분석(2개), 최근접 이웃(1개), 나이브 베이즈(3개), 의사결정 나무(1개) 및 앙상블(4개)과 같은 다양한 카테고리에 속한다. AUTO-WEKA[2]와는 달리, 우리는 구성 공간을 기본 분류기에 초점을 맞추고, 하나 이상의 기본 분류기에 의해 매개변수화된 메타 모델과 앙상블을 제외했다. 이러한 앙상블은 AUTO-WEKA의 하이퍼파라미터 수를 거의 5배(786개로) 늘렸지만, AUTO-SKLEARN은 “단지” 110개의 하이퍼파라미터를 갖는다. 대신, Section 3.2의 사후 방법을 사용하여 복잡한 앙상블을 구성한다. AUTO-WEKA에 비해 이는 훨씬 더 데이터 효율적이다: AUTO-WEKA에서는 5개의 구성 요소가 있는 앙상블의 성능을 평가하는 데 5개의 모델을 구성하고 평가해야한다. 반면, AUTO-SKLEARN에서는 앙상블이 대부분 무료로 제공되며, 최적화하는 동안 임의의 시간에 평가된 모델을 혼합하고 매치하는 것이 가능하다.
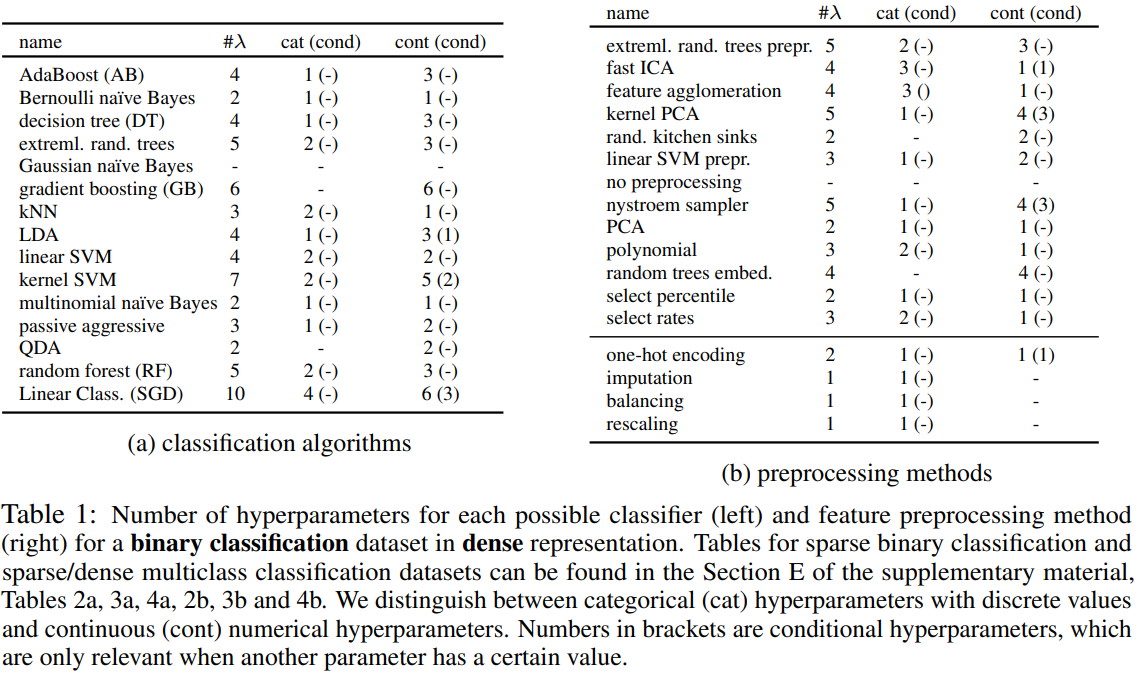
AUTO-SKLEARN에서 밀집 표현의 데이터셋에 대한 전처리 방법은 Table 1b에 나열되어 있으며(부록의 Section A.2에서 자세히 설명됨), 데이터 전처리기(특성 값을 변경하며 적용 가능할 때 항상 사용됨)와 특성 전처리기(실제 특성 집합을 변경하며 하나 또는 없음이 사용됨)를 포함한다. 데이터 전처리에는 입력의 재조정, 누락된 값의 대체, 원-핫 인코딩 및 대상 클래스의 균형 조정이 포함된다. 14개의 가능한 특성 전처리 방법은 특성 선택(2), 커널 근사(2), 행렬 분해(3), 임베딩(1), 특성 클러스터링(1), 다항 특성 확장(1) 및 분류기를 사용하는 방법(2)으로 나눌 수 있다. 예를 들어, 데이터에 적합한 L1-정규화 선형 SVM을 사용하여 0값 모델 계수에 해당하는 특성을 제거하여 특성 선택을 수행할 수 있다.
Comparing AUTO-SKLEARN to AUTO-WEKA and HYPEROPT-SKLEARN
기본 실험으로, AUTO-SKLEARN의 기본 버전(개선 사항 없음)의 성능을 AUTO-WEKA 및 HYPEROPT-SKLEARN과 비교하여, AUTO-WEKA를 소개하는 논문 [2]의 21개 데이터셋을 사용한 실험 설정을 재현했다. 이 설정에 대한 자세한 설명은 부록의 Section G에서 확인할 수 있다.
Table 2에 따르면 AUTO-SKLEARN은 6/21 경우에서 통계적으로 유의하게 AUTO-WEKA보다 나은 성능을 보였고, 12개 경우에서 비슷한 성능을 보이며, 3개 경우에서 떨어진 성능을 보였다. AUTO-WEKA가 가장 잘 수행된 세 개의 데이터셋에서, AUTO-WEKA가 선택한 최상의 분류기가 scikit-learn에 구현되지 않은 경우(가지치기 컴포넌트가 있는 트리) 50% 이상의 실행에서 확인되었다. HYPEROPT-SKLEARN은 지금까지 사용자가 구성 공간을 자신의 필요에 맞게 적응시키도록 초대하는 개념 증명 수준이며, 완전한 AutoML 시스템은 아니다. 현재 버전은 희소 데이터와 누락된 값이 제시될 때 충돌한다. 또한, 공정한 비교를 가능하게 하기 위해 모든 최적화 도구에 설정한 메모리 제한 때문에 Cifar-10에서도 충돌한다. 16개 데이터셋에서 실행된 HYPEROPT-SKLEARN은 9개 경우에서 최고의 최적화 도구와 통계적으로 비슷한 성능을 보이고 7개 경우에서 떨어진 성능을 보였다.

Evaluation of the proposed AutoML improvements
제안된 AutoML 시스템의 강건성과 다양한 데이터셋에 대한 일반 적용성을 평가하기 위해, OpenML 저장소 [18]에서 140개의 이진 및 다중 클래스 분류 데이터셋을 수집했다. 안정적인 성능 평가를 가능하게 하기 위해 최소 1000개의 데이터 포인트가 있는 데이터셋만 선택했다. 이 데이터셋들은 텍스트 분류, 숫자 및 문자 인식, 유전자 시퀀스 및 RNA 분류, 광고, 망원경 데이터를 위한 입자 분류, 조직 샘플에서의 암 감지와 같은 다양한 분야를 다룬다. 부록의 Table 7과 8에 모든 데이터셋을 나열하고 재현 가능성을 위해 OpenML의 고유 식별자를 제공한다.
많은 데이터셋에서 클래스 분포가 매우 불균형하기 때문에, 균형 분류 오류율(BER)이라는 측정 방법을 사용하여 모든 AutoML 방법을 평가했다. 균형 오류율을 각 클래스에서 잘못 분류된 비율의 평균으로 정의한다. 표준 분류 오류(전체 오류의 평균)와 비교하여, 이 측정 방법(클래스별 오류의 평균)은 모든 클래스에 동일한 가중치를 부여한다. 기계 학습 경쟁에서 종종 균형잡힌 오류 또는 정확도 측정 방법이 사용된다는 점을 언급한다(예: AutoML 챌린지 [1]는 균형잡힌 정확도를 사용한다).
각 데이터셋에서 메타러닝 사용 및 미사용, 앙상블 예측 사용 및 미사용과 함께 AUTO-SKLEARN을 10회 실행했다. 엄격한 시간 제한 하에서의 성능을 연구하고 계산 자원 제한 때문에 각 실행에 대한 CPU 시간을 1시간으로 제한했다. 또한 단일 모델의 런타임을 이 중 1/10(6분)로 제한했다. 메타러닝에 이미 사용된 데이터셋에서 성능을 평가하지 않기 위해 하나의 데이터셋을 제외한 검증을 수행했다: 데이터셋 D에서 평가할 때, 139개의 다른 데이터셋에서만 메타 정보를 사용했다.
그림 3은 테스트한 네 가지 AUTO-SKLEARN 버전의 평균 순위를 시간에 따라 보여준다. 우리의 두 가지 새로운 방법이 기본 AUTO-SKLEARN에 비해 상당한 개선을 가져왔음을 알 수 있다. 가장 눈에 띄는 결과는 메타러닝이 선택한 첫 번째 구성부터 실험이 끝날 때까지 큰 개선을 보였다는 것이다. 개선이 가장 두드러지게 나타났던 것은 시작 부분이며, 시간이 지남에 따라 기본 AUTO-SKLEARN도 메타러닝 없이 좋은 해결책을 찾아 일부 데이터셋에서 따라잡았음을 알린다(이로써 전체 순위가 향상됨).
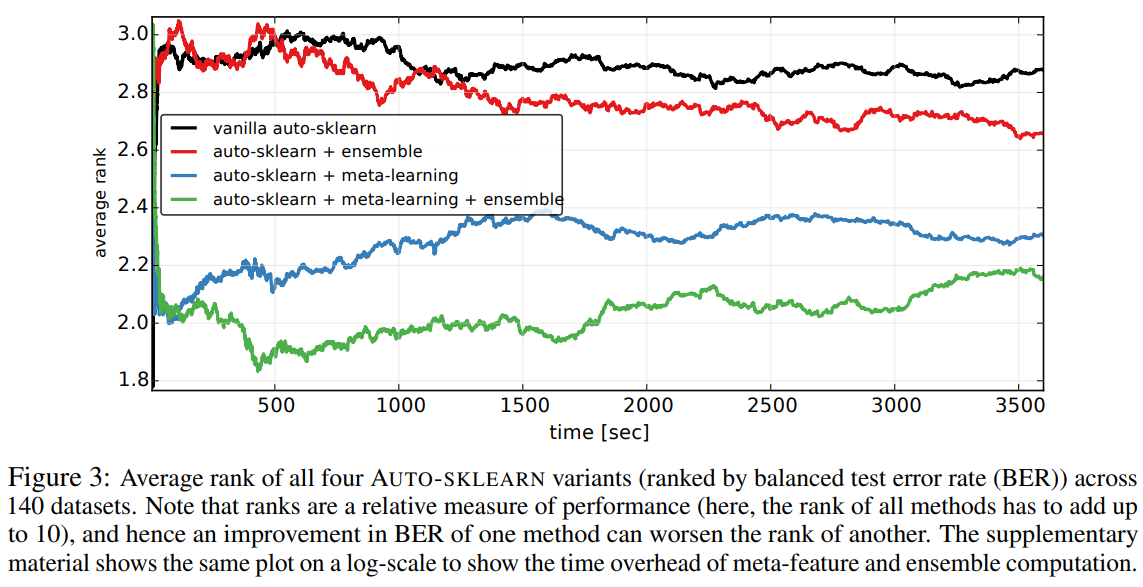
게다가, 우리의 두 가지 방법은 서로를 보완한다: 자동 앙상블 구성은 기본 AUTO-SKLEARN과 메타러닝이 있는 AUTO-SKLEARN 모두를 개선했다. 흥미롭게도, 앙상블의 성능에 미치는 영향은 메타러닝 버전에서 더 일찍 시작됐다. 이는 메타러닝이 더 일찍 더 나은 기계 학습 모델을 생성하기 때문이라고 생각하는데, 이를 바로 강력한 앙상블로 결합할 수 있다. 하지만 더 긴 시간 동안 실행되면, 메타러닝이 없는 기본 AUTO-SKLEARN도 자동 앙상블 구성의 혜택을 누린다.
Detailed analysis of AUTO-SKLEARN components
이제 AUTO-SKLEARN의 개별 분류기와 전처리기를 공동으로 최적화하는 방법과 비교하여 그들의 최고 성능과 안정성에 대한 인사이트를 얻기 위해 연구한다. 이상적으로, 우리는 단일 분류기와 단일 전처리기의 모든 조합을 개별적으로 연구하고 싶었지만, 15개의 분류기와 14개의 전처리기가 있어서 이는 실행할 수 없었다. 대신에 단일 분류기의 성능을 연구할 때, 우리는 여전히 모든 전처리기를 최적화했고, 그 반대도 마찬가지였다. 좀 더 상세한 분석을 위해, 우리는 데이터셋의 부분집합에 초점을 맞추었지만, 모든 방법을 최적화하기 위한 구성 예산을 한 시간에서 하루로, AUTO-SKLEARN에 대해서는 두 일로 확장했다. 구체적으로, 우리는 데이터셋 메타특성을 기반으로 140개의 데이터셋을 g-means [27]로 클러스터링하고, 결과로 나온 13개의 클러스터 각각에서 하나의 데이터셋을 사용했다(데이터셋 목록을 위해 부록 테이블 6을 참조하시오). 총 10.7 CPU년이 필요한 이번 방대한 실험을 알려드린다.
표 3은 다양한 분류 방법들의 결과를 AUTO-SKLEARN과 비교한다. 전반적으로, 예상대로 랜덤 포레스트, 극단적으로 랜덤화된 트리, AdaBoost, 그리고 그래디언트 부스팅이 가장 안정적인 성능을 보였으며, SVMs는 일부 데이터셋에 대해 강력한 최고 성능을 보였다. 강력한 분류기들의 다양함 외에도, 경쟁력을 가질 수 없는 여러 모델이 있었다. 결정 트리, 패시브 어그레시브, kNN, 가우시안 NB, LDA 그리고 QDA는 대부분의 데이터셋에서 최고의 분류기보다 통계적으로 유의하게 열등했다. 마지막으로, 표는 어떠한 단일 방법도 모든 데이터셋에 대해 최선의 선택이었다는 것을 나타내지 않았다. 표에서 보여지고 그림 4의 두 예제 데이터셋에서 시각화된 것처럼, AUTO-SKLEARN의 공동 구성 공간을 최적화하는 것이 가장 안정적인 성능을 이끌어냈다. 시간에 따른 순위의 그래프(부록에서 그림 2와 3)는 13개의 데이터셋 전반에 걸쳐 이를 정량화하며, AUTO-SKLEARN이 합리적이지만 최적이 아닌 성능으로 시작하여 시간이 지남에 따라 더 일반적인 구성 공간을 효과적으로 검색하여 최고의 전반적인 성능으로 수렴한다는 것을 보여준다.
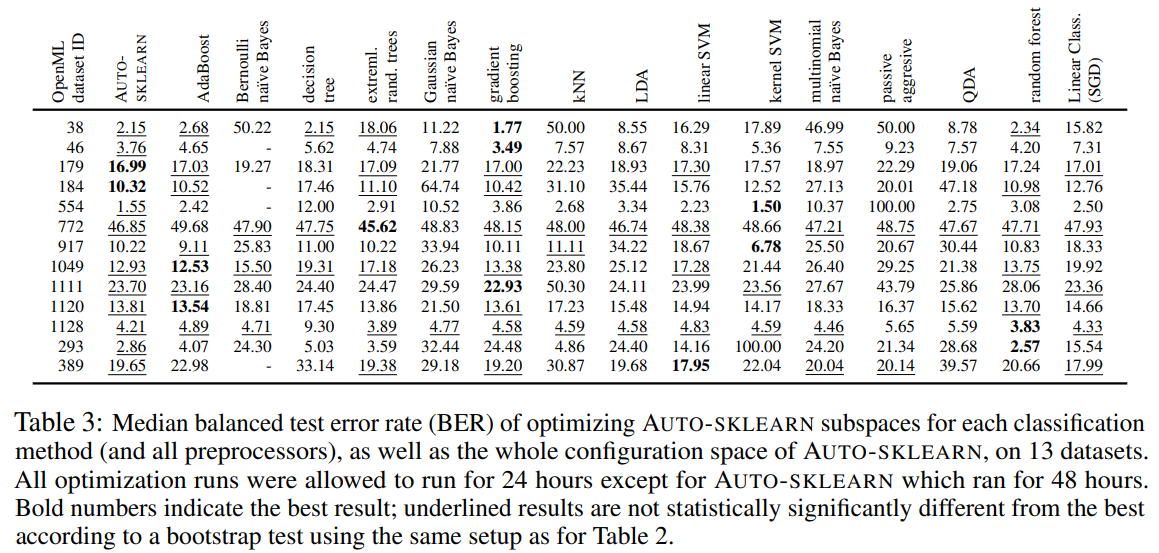
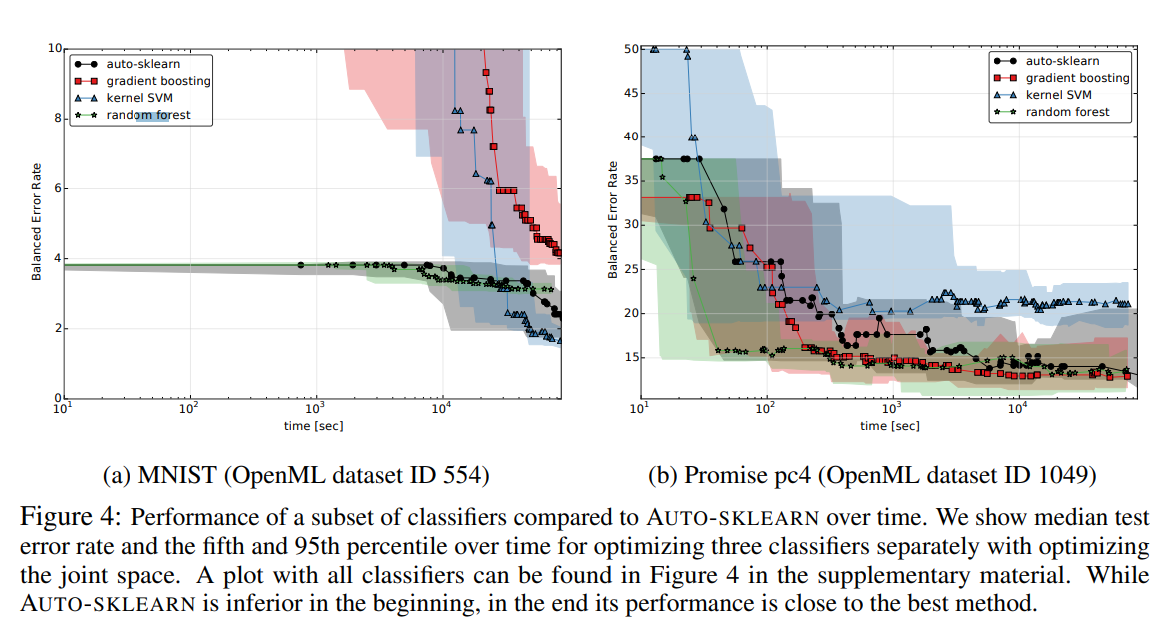
- 궁금한 점
- 점 찍혀있는거를 보면 random forest와 autosklearn gradient boosting 이런게 time 길이가 다른거 같다. 그리고 auto-sklearn 방법은 meta learning을 적용해서 초기 balanced error rate가 낮아야 하는거 아닌가?
- 단일 모델들은 전처리 어떻게 수행된건지? 궁금하다
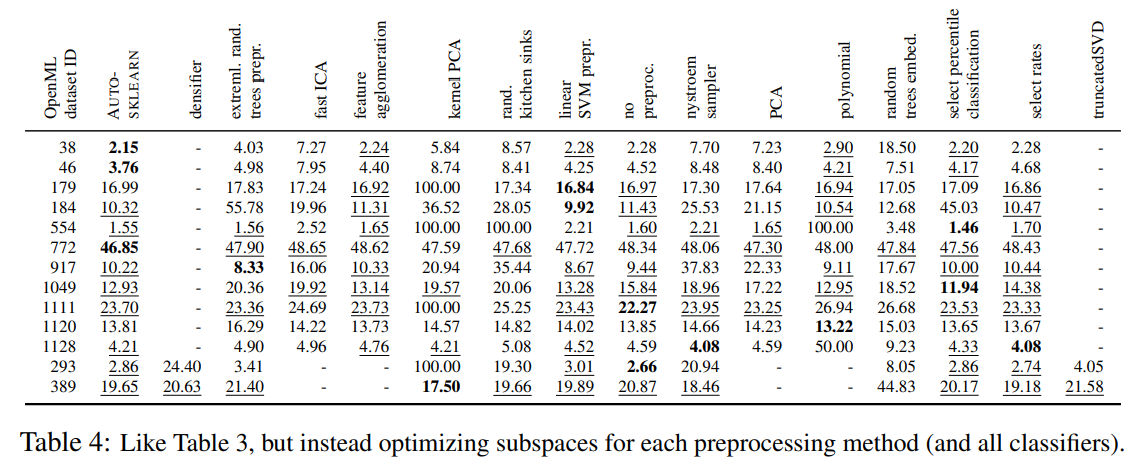
표 4는 다양한 전처리기와 AUTO-SKLEARN과의 결과를 비교한다. 위의 분류기 비교와 마찬가지로, AUTO-SKLEARN은 가장 안정적인 성능을 보였다: 이는 3개의 데이터셋에서 최고로 수행되었고, 다른 13개 중 8개에서 최고의 전처리기보다 통계적으로 유의하게 나쁘지 않았다.
Discussion and Conclusion
이 연구에서는 새로운 AutoML 시스템인 AUTO-SKLEARN이 AutoML의 이전 기술에 비해 우수한 성능을 보이며, 메타러닝과 앙상블 기법을 통해 AutoML의 효율성과 안정성을 더욱 향상시킨다는 것을 보여줬다. 이러한 결과는 AUTO-SKLEARN이 ChaLearn의 진행 중인 AutoML 챌린지 첫 단계의 auto-track에서 우승한 사실로 뒷받침된다. 이 논문에서는 전문가와 협업하여 몇 주 동안 CPU를 사용하는 대화형 머신러닝에 AUTO-SKLEARN을 사용하는 것은 평가하지 않았지만, 같은 챌린지의 인간 트랙에서 3위를 차지했다는 것을 언급한다. 따라서 AUTO-SKLEARN은 머신러닝 초보자와 전문가 모두에게 유용한 시스템이라고 생각한다. AUTO-SKLEARN의 소스 코드는 오픈 소스 라이센스로 https://github.com/automl/auto-sklearn 에서 사용할 수 있다.
그러나 우리 시스템은 일부 단점이 있으며, 향후 이를 해소하려 한다. 예를 들어, 회귀 또는 준지도학습 문제를 아직 다루지 않았다. 무엇보다도, scikit-learn에 초점을 맞춤으로써 소규모에서 중규모 데이터셋에 집중하게 되었고, 향후 큰 데이터셋에서 최신 성능을 제공하는 현대 딥러닝 시스템에 메서드를 적용하는 것이 미래의 연구 방향이 될 것이다. 특히 이 분야에서 자동 앙상블 구성이 베이지안 최적화를 통한 성능 향상을 가져올 것으로 기대한다.