Adversarial Discriminative Domain Adaptation (2017)
Introduction
Dataset의 분포 차이에 의한 Domainshift로 인해 모델의 성능 하락과 이에 따른 모델 재학습의 필요하다는 문제가 발생함. Domain shift를 해결하기 위해서는 추가적인 데이터의 수집을 진행해야 하는데 해당 과정에서 어려움이 존재함
적대적 adaptation 방법은 도메인 discriminator와 관련하여 적대적 목표를 통해 도메인 불일치 거리를 최소화하려는 이러한 유형의 접근 방식이 인기있음.
이러한 방법은 생성기와 판별기라는 두 개의 네트워크를 서로 경쟁시키는 생성적 적대 학습과 밀접한 관련이 있음.
생성기는 판별기를 혼동하는 방식으로 이미지를 생성하도록 훈련되며, 이는 다시 실제 이미지 예제와 구별하려고 함. 도메인 적응에서 이 원칙은 네트워크가 훈련과 테스트 도메인 예제의 분포를 구별할 수 없도록 하기 위해 사용됨.
그러나 각 알고리즘은 generator를 사용할지, 어떤 손실 함수를 사용할지 또는 도메인 간에 가중치를 공유할지와 같은 다른 설계 선택을 함
Proposd Method
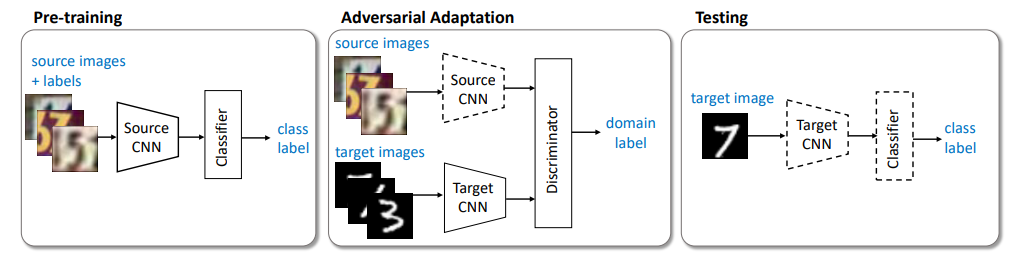
Pre=training
Pre-training을 활용한 Feature extraction과 함께 Source domain과 Target domain에서
추출된 Feature를 구별하도록 훈련하는 Discriminator를 사용함.
Pre-training과정에서는 Source domain의 Label을 활용하여 Classification을 잘하도록 Crossen tropyloss를 활용함
loss function은 아래와 같음
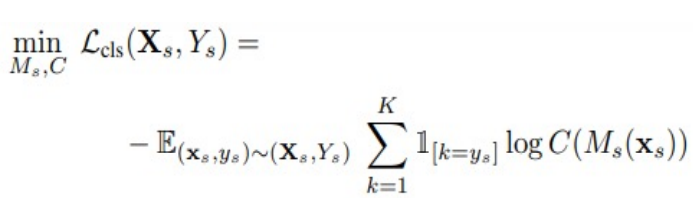
Adversarial Adaptation
- Source domain과 Targetd omain을 잘 구별하도록 하는 Discriminator를 Adversarial loss를 활용하여 학습함
Target domain Mapping에서 추출된 sample이 들어오면 0을 return하고,Source domain Mapping에서 추출된 sample이 들어오면 1을 return하도록 학습을 진행함.
이때의 loss function은 아래와 같음
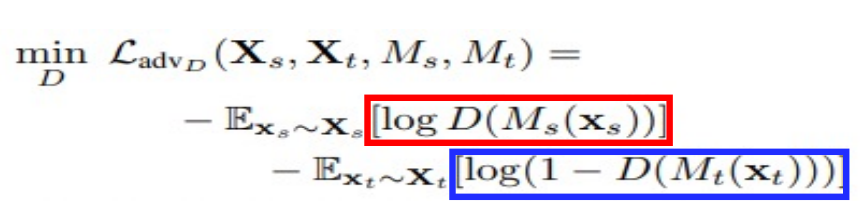
일반적으로 GAN의 loss function은 아래와 같은데,
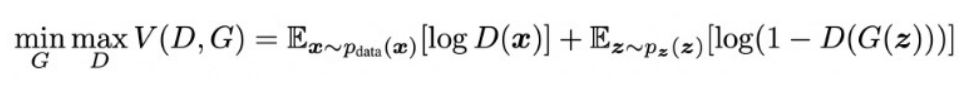
여기서 D(x)는 최대한 1에 가깝게 만들고, D(G(z))는 최대한 0에 가깝게 만듬.
Adversarial Adaptation에서는 Discriminator가 일단 source와 target이 각 class를 잘 구분하도록 학습을 진행하기 때문에 앞에 모두 음수(-)가 붙었음.
- Target Domain 신경망 학습
Sourcedomain신경망은 학습을 진행하지 않고 Target domain image를 넣어서 나오는 feature
map을 Discriminator가 1이라고 잘못 예측하게 만드는 Targetdomain신경망만 학습을 진행함.
이에 대한 loss 함수는 아래와 같음
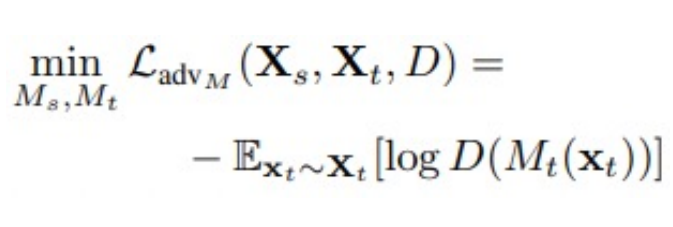
Experiment
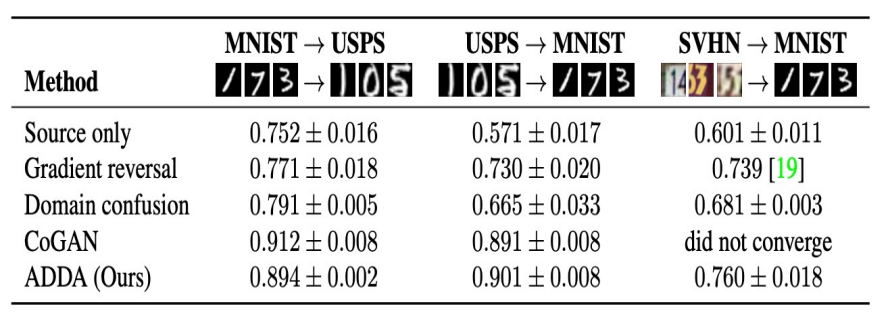
MNIST와 USPS사이의 Domain adaptation에서 ADDA는 단순한 모델임에도 CoGAN과 비슷한 성능을 달성함에 따라 Domain adaptation에서 Generator를 사용하지 않아도 됨을 입증함.