Introduction
Discriminative 접근 방식은 지도 학습에 사용되는 것과 유사한 objective function 을 사용하여 표현을 학습하지만, 입력과 레이블이 모두 레이블이 없는 데이터 세트에서 파생되는 pretext 작업을 수행하도록 네트워크를 훈련시킨다. 그러한 많은 접근 방식은 학습된 표현의 일반성을 제한할 수 있는 pretext 작업을 설계하기 위해 휴리스틱에 의존해왔다. 잠재 공간에서 대조 학습을 기반으로 한 차별적 접근 방식은 최근 최첨단 결과를 달성하며 큰 가능성을 보여주고 있다.
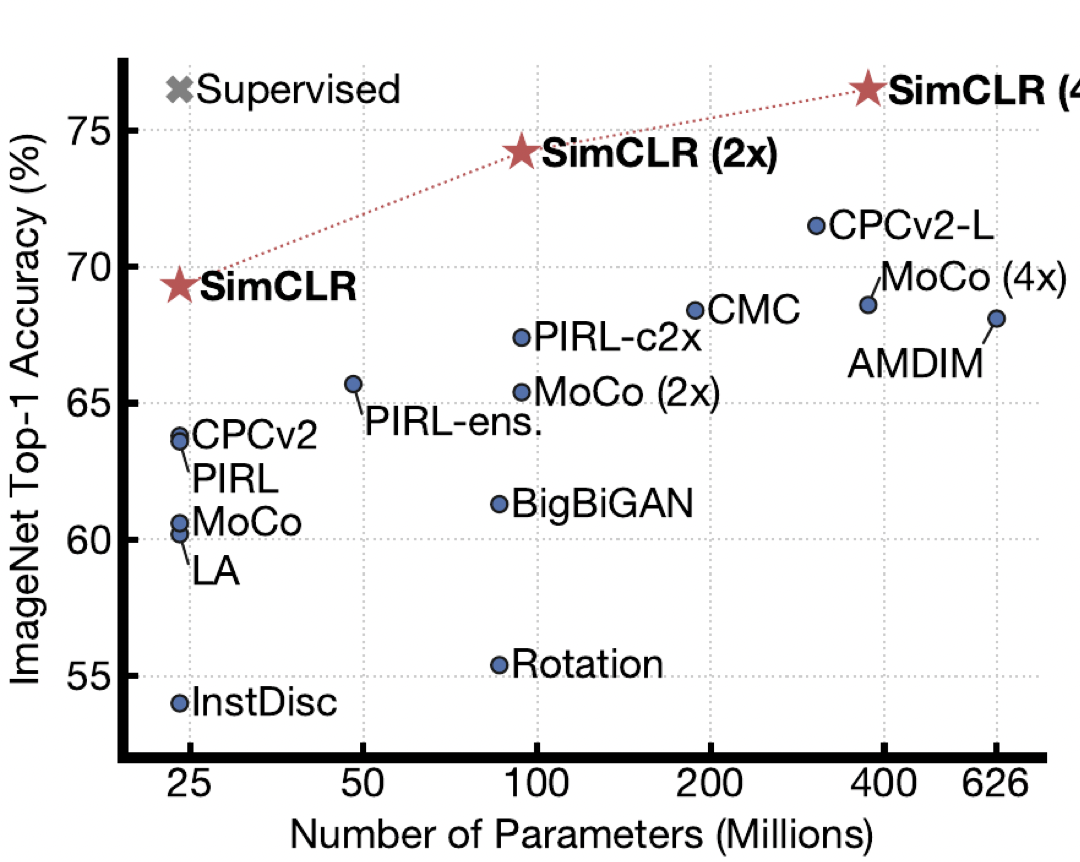
본 연구에서는 시각적 표현의 대조적 학습을 위한 간단한 프레임워크를 소개하는데, 이를 SimCLR이라고 한다. SimCLR은 이전 작업(그림 1)보다 성능이 뛰어날 뿐만 아니라, 전문 아키텍처도 메모리 뱅크도 필요하지 않아 더 간단하다.
무엇이 좋은 대조 표현 학습을 가능하게 하는지 이해하기 위해, 우리는 프레임워크의 주요 구성 요소를 체계적으로 연구하고 다음을 보여준다.
- 다중 데이터 augmentation operation의 구성은 효과적인 표현을 생성하는 대조적 예측 작업을 정의하는 데 중요하다. 또한, 비지도 대비 학습은 지도 학습보다 더 강력한 데이터 증강의 혜택을 받는다.
- 표현과 대조 손실 사이에 학습 가능한 비선형 변환을 도입하면 학습된 표현의 품질이 크게 향상된다.
- 대조적인 교차 엔트로피 손실로 표현 학습은 정규화된 임베딩과 적절하게 조정된 온도 매개 변수로부터 이익을 얻는다.
- 대조적인 학습은 Supervised Counterpart와 비교하여 더 큰 배치 크기와 더 긴 훈련으로부터 이점을 얻는다. 지도 학습과 마찬가지로, 대조 학습은 더 깊고 넓은 네트워크로부터 이익을 얻는다.
우리는 이러한 발견을 결합하여 Ima-geNet ILSVRC-2012에 대한 Self-supervised 및 semi-supervised 학습에서 새로운 SOTA를 달성한다. 선형 평가 프로토콜에서 SimCLR은 76.5%의 상위 1위 정확도를 달성하는데, 이는 이전의 최신 기술에 비해 7%의 상대적 향상이다. 1%의 ImageNet 레이블로 미세 조정하면 SimCLR은 상위 5개 정확도 85.8%를 달성하여 상대적으로 10% 향상된다. 다른 자연 이미지 분류 데이터 세트에서 미세 조정될 때 SimCLR은 12개의 데이터 세트 중 10개에서 강력한 감독 기준과 동등하거나 더 나은 성능을 보인다.
Method
The contrastive learning framework
SimCLR은 잠재 공간의 대조적 손실을 통해 동일한 데이터 예제의 서로 다른 augmented views간의 agreement를 극대화하여 표현을 학습한다. 그림 2에 나타난 바와 같이, 이 프레임워크는 다음의 4가지 주요 구성 요소로 구성된다.
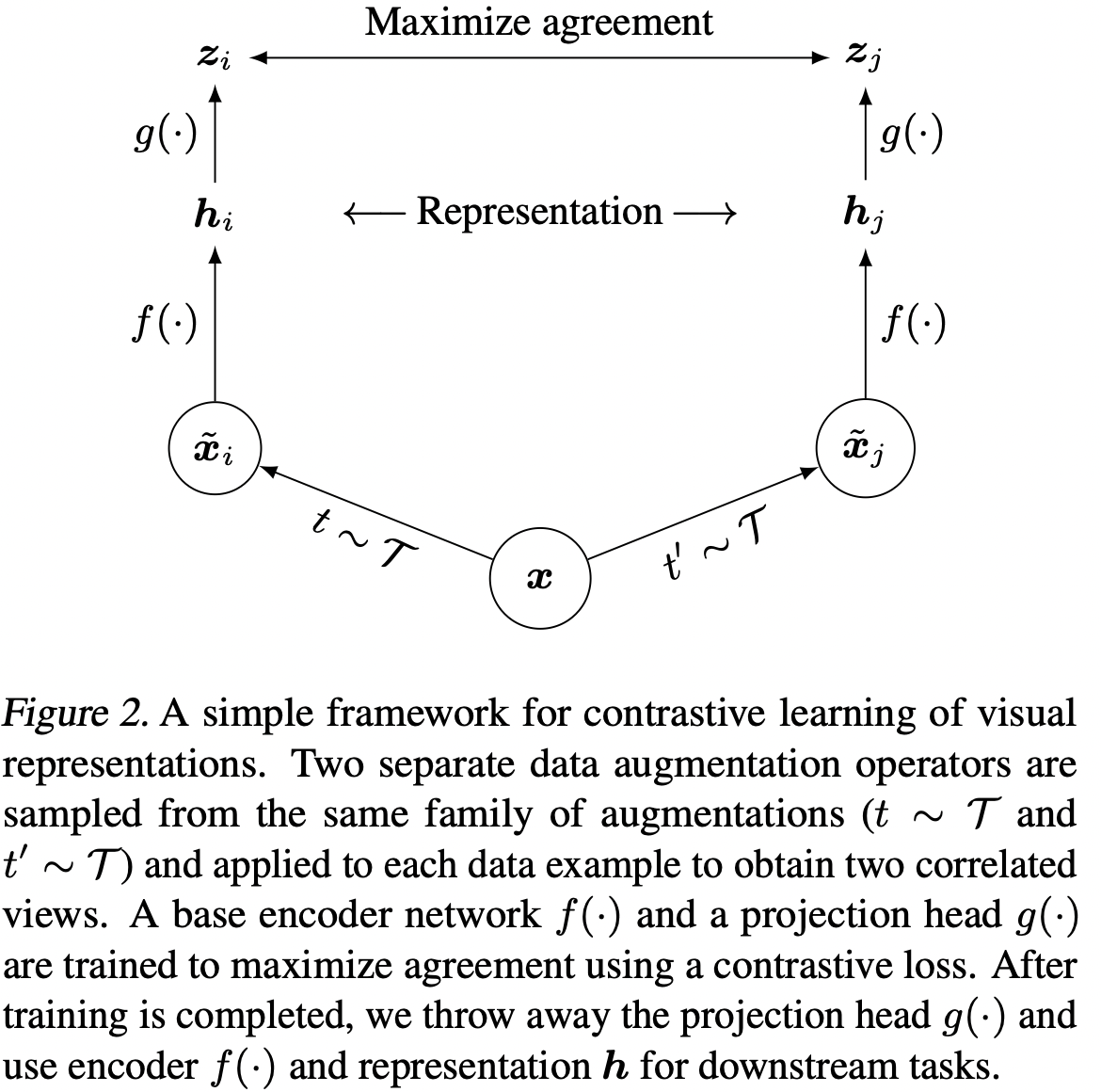
- 주어진 데이터 예제를 무작위로 변환하여 동일한 예제의 상관 관계가 있는 두 뷰를 생성하는 확률적 데이터 augmentation 모듈로서, x_i와 x_j로 표시되며, 우리는 이를 양의 쌍으로 간주한다. 이 연구에서 우리는 세 가지 간단한 증강을 순차적으로 적용한다. 즉, 무작위 자르기, 무작위 색 왜곡, 무작위 가우스 블러이다. 섹션 3에서 알 수 있듯이, 무작위 크롭과 색 왜곡의 조합은 좋은 성능을 얻기 위해 매우 중요합니다.
- Augmented 데이터 예제에서 표현 벡터를 추출하는 신경망 기반 인코더 f(·)입니다. 우리의 프레임워크는 어떠한 제약 없이 다양한 네트워크 아키텍처 선택을 가능하게 한다. 우리는 단순성을 선택하고 일반적으로 사용되는 ResNet(He 등, 2016)을 채택하여 hi = f(x_i) = ResNet(x_i)을 얻는다. 여기서 hi는 average 풀링 계층 이후의 출력이다.
- 대조 손실이 적용되는 공간에 표현을 매핑하는 작은 신경망 투영 헤드 g(·)입니다. 우리는 하나의 숨겨진 레이어가 있는 MLP를 사용하여 zi = g(hi) = W(2)θ(W(1)hi)를 얻는다. 여기서 θ는 ReLU 비선형성이다. 섹션 4에서 보듯이, 우리는 hi가 아닌 zi의 대조적인 손실을 정의하는 것이 유익하다는 것을 발견한다.
우리는 N개의 예제의 미니 배치를 무작위로 샘플링하고 미니 배치에서 파생된 증강 예제의 쌍에서 대조 예측 작업을 정의하여 2N개의 데이터 포인트를 생성한다. 우리는 부정적인 예를 명시적으로 샘플링하지 않는다. 대신, 양의 쌍이 주어지면 미니 배치 내의 다른 2(N - 1) 증강 사례를 부정적인 예로 취급한다. 그렇다면 양의 예 (i, j)에 대한 손실 함수는 다음과 같이 정의된다.
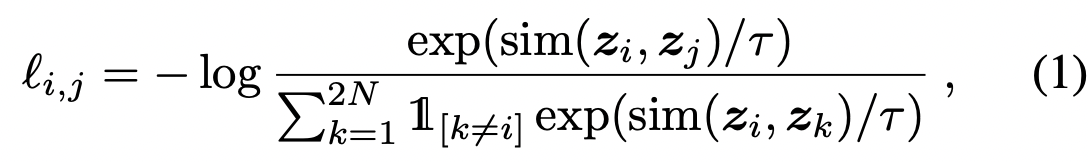
Evaluation Protocol
Dataset
Unsupervised pretraining(라벨 없이 인코더 네트워크 f 학습)에 대한 대부분의 연구는 ImageNet ILSVRC-2012 데이터 세트를 사용하여 수행된다. 우리는 또한 Transfer Learning 위해 광범위한 데이터 세트에서 사전 훈련된 결과를 테스트한다. 학습된 표현을 평가하기 위해, 우리는 널리 사용되는 선형 평가 프로토콜을 따르는데, 여기서 선형 분류기는 동결된 기본 네트워크 위에서 훈련되고, 테스트 정확도는 표현 품질을 위한 대용물로 사용된다. 선형 평가 외에도, 우리는 또한 semi-supervised 및 Transfer Learning 에 대한 최첨단 기술과 비교한다.
Data Augmentation for Contrastive Representation Learning
Composition of data augmentation operations is crucial for learning good representations
데이터 augmentation의 영향을 체계적으로 연구하기 위해 여기서는 몇 가지 일반적인 augmentation을 고려한다. 증강 유형 중 하나는 자르기 및 크기 조정(수평 플립 포함), 회전(Gidaris et al., 2018) 및 컷아웃(De-Vries & Taylor, 2017)과 같은 데이터의 공간/기하학적 변환을 포함한다. 다른 유형의 확대에는 색상 왜곡(색상 저하, 밝기, 대비, 채도, 색상 포함)과 같은 외관 변환(Howard, 2013; Szegedy 등, 2015), 가우스 블러 및 Sobel 필터링이 포함된다. 그림 4는 우리가 이 연구에서 연구한 증강을 시각화한다.

개별 데이터 증강의 효과와 증강 구성의 중요성을 이해하기 위해 개별적으로 또는 쌍으로 증강을 적용할 때 프레임워크의 성능을 조사한다. ImageNet 이미지는 크기가 다르기 때문에 항상 크롭 및 크기 조정 이미지를 적용하므로 크롭이 없는 경우 다른 증강을 연구하기가 어렵다(Krizhevsky et al., 2012; Szegedy et al., 2015) 이러한 혼동을 제거하기 위해, 우리는 이 ablation에 대한 비대칭 데이터 변환 설정을 고려한다. 구체적으로, 우리는 항상 이미지를 무작위로 자르고 동일한 해상도로 크기를 조정한 다음, 다른 브랜치는 아이덴티티(즉, t(xi) = xi)로 남겨두고 그림 2의 프레임워크의 한 브랜치에만 대상 변환을 적용한다.
그림 5는 변환의 개별 구성 및 구성에 따른 선형 평가 결과를 보여줍니다. 모델이 대조 작업에서 거의 완벽하게 양의 쌍을 식별할 수 있더라도 좋은 표현을 학습하기에 충분한 단일 변환은 없다는 것을 관찰한다. 증강을 구성할 때 대조 예측 작업은 더 어려워지지만 표현 품질은 크게 향상된다.
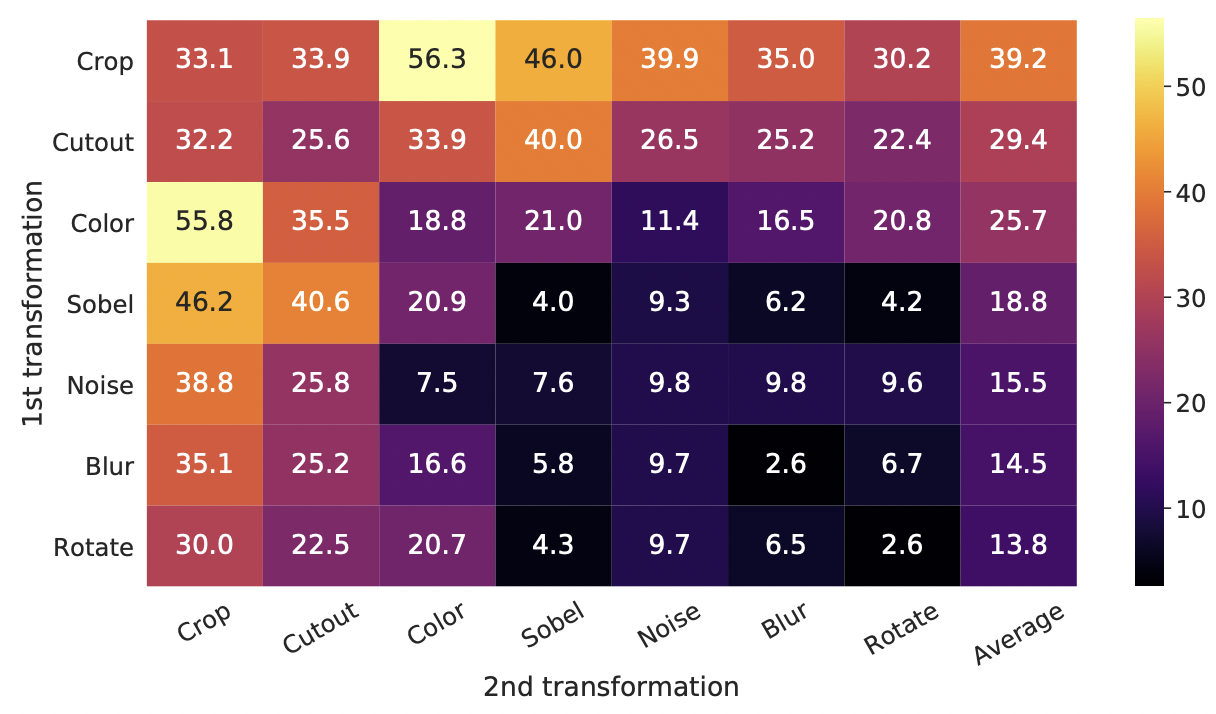
증강의 한 가지 구성은 무작위 자르기 및 무작위 색 왜곡이다. 데이터 증강으로 무작위 자르기만 사용할 때 심각한 문제 중 하나는 이미지의 대부분의 패치가 유사한 색상 분포를 공유한다는 것이라고 추측한다. 그림 6은 색상 히스토그램만으로도 이미지를 구별하기에 충분하다는 것을 보여준다. 신경망은 예측 작업을 해결하기 위해 이 shortcut를 이용할 수 있다. 따라서 일반화할 수 있는 특징을 학습하기 위해서는 색상 왜곡이 있는 자르기 작업을 구성하는 것이 중요하다.
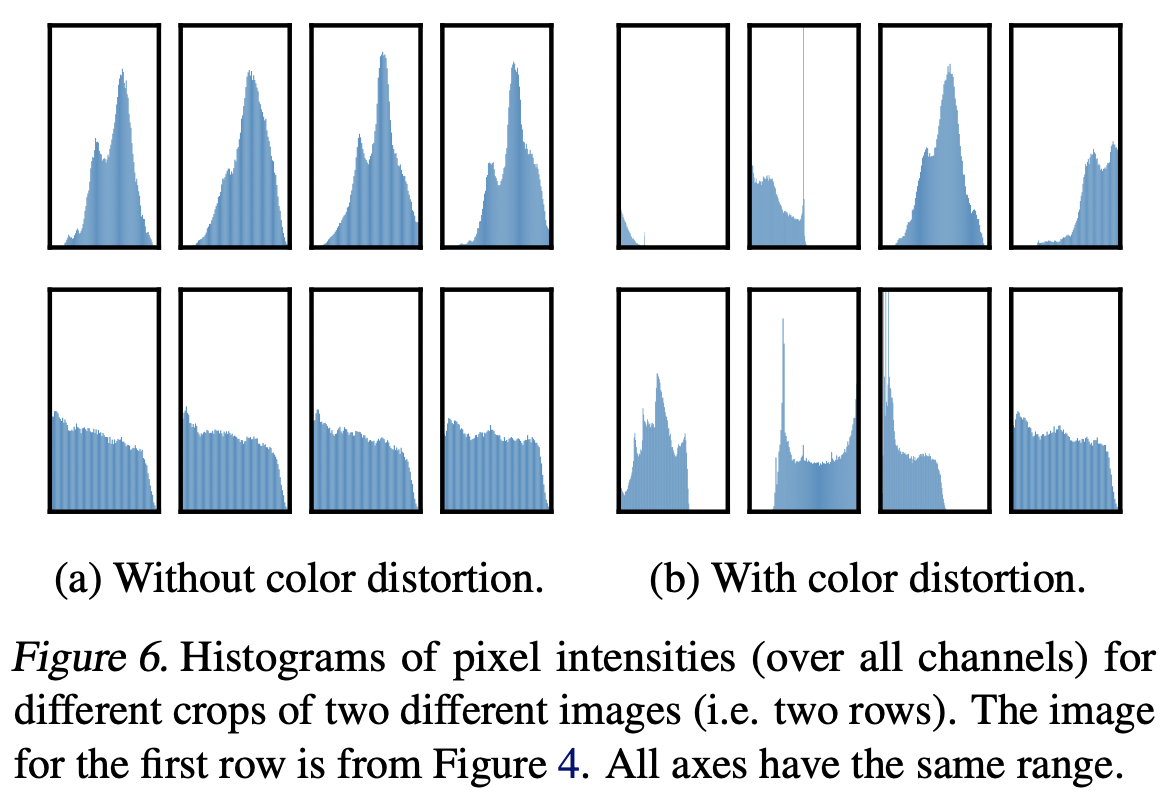
동일한 증강 세트를 사용하여 감독 모델을 교육할 때, 우리는 더 강한 색 증강이 개선되지 않거나 심지어 성능을 해친다는 것을 관찰한다. 따라서, 우리의 실험은 감독되지 않은 대조 학습이 감독된 학습보다 더 강력한 (색상) 데이터 증강으로부터 이익을 얻는다는 것을 보여준다. 이전 연구에서 데이터 확대가 자체 지도 학습에 유용하다고 보고했지만, 우리는 지도 학습에 대한 정확도 이점을 산출하지 않는 데이터 확대가 여전히 대조 학습에 상당한 도움이 될 수 있음을 보여준다.
Architectures for Encoder and Head
A nonlinear projection head improves the representation quality of the layer before it
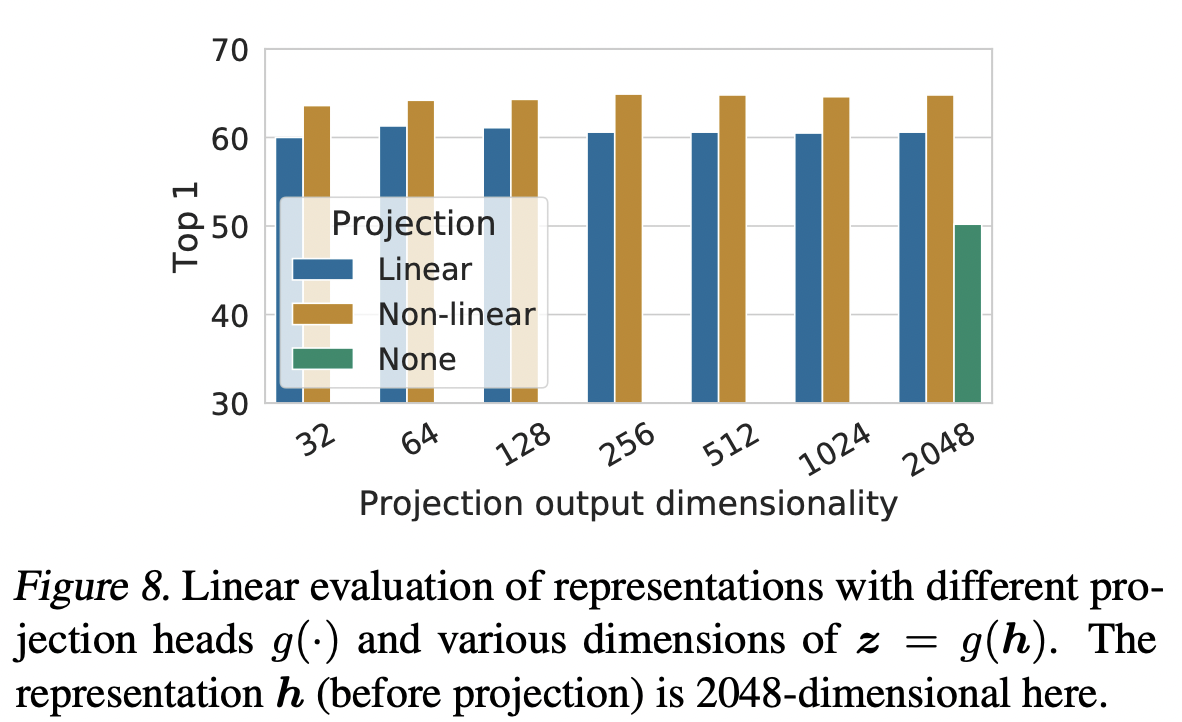
그런 다음 projection 헤드(예: g(h)를 포함하는 것의 중요성을 연구한다. 그림 8은 (1) 아이덴티티 매핑, (2) 이전 여러 접근 방식에서 사용한 선형 투영, (3) Bachman 등(2019)과 유사한 하나의 추가 숨겨진 레이어가 있는 기본 비선형 투영(및 ReLU 활성화)의 세 가지 다른 아키텍처를 사용한 선형 평가 결과를 보여준다. 우리는 비선형 투영이 선형 투사(+3%)보다 낫고 투영이 없는(>10%)보다 훨씬 낫다는 것을 관찰한다.
Loss Functions and Batch Size
Normalized cross entropy loss with adjustable temperature works better than alternatives
NT-Xent 손실을 로지스틱 손실(Mikolov et al., 2013) 및 마진 손실(Schroff et al., 2015)과 같이 일반적으로 사용되는 다른 대조적 손실 함수와 비교한다. 표 2는 목적 함수와 손실 함수의 입력에 대한 기울기를 보여준다. 그라데이션에서 우리는 1) l2 정규화(즉, 코사인 유사성)를 온도와 함께 효과적으로 다른 예를 가중시키고, 적절한 온도는 모델이 하드 네거티브로부터 학습하는 데 도움이 될 수 있다. 그리고 2) 교차 엔트로피와 달리 다른 객관적 함수는 상대적 경도에 의해 네거티브를 가중시키지 않는다. 결과적으로, 이러한 손실 함수에 대해 세미 하드 마이너스 마이닝(Semi-hard negative mining, Schroff et al., 2015)을 적용해야 한다. 모든 손실 조건에 대한 그레이디언트를 계산하는 대신 세미 하드 마이너스 용어(즉, loss margin 내에 있고 거리가 가장 가깝지만 긍정적인 예보다 먼 용어)를 사용하여 그레이디언트를 계산할 수 있다.

비교를 공정하게 하기 위해 모든 손실 함수에 대해 동일한 l2 정규화를 사용하고 하이퍼 파라미터를 조정하고 최상의 결과를 보고한다. 표 4는 (준-하드) 네거티브 마이닝이 도움이 되지만 최상의 결과는 여전히 기본 NT-Xent 손실보다 훨씬 심각하다는 것을 보여줍니다.

다음으로 기본 NT-Xent 손실에서 l2 정규화(즉, cosine simility vs dot product)와 온도 θ의 중요성을 테스트한다. 표 5는 정규화 및 적절한 온도 스케일링이 없으면 성능이 크게 저하된다는 것을 보여줍니다. l2 정규화를 수행하지 않으면 대조 작업 정확도가 더 높지만 선형 평가에서는 결과 표현이 더 나쁘다.

Contrastive learning benefits (more) from larger batch sizes and longer training
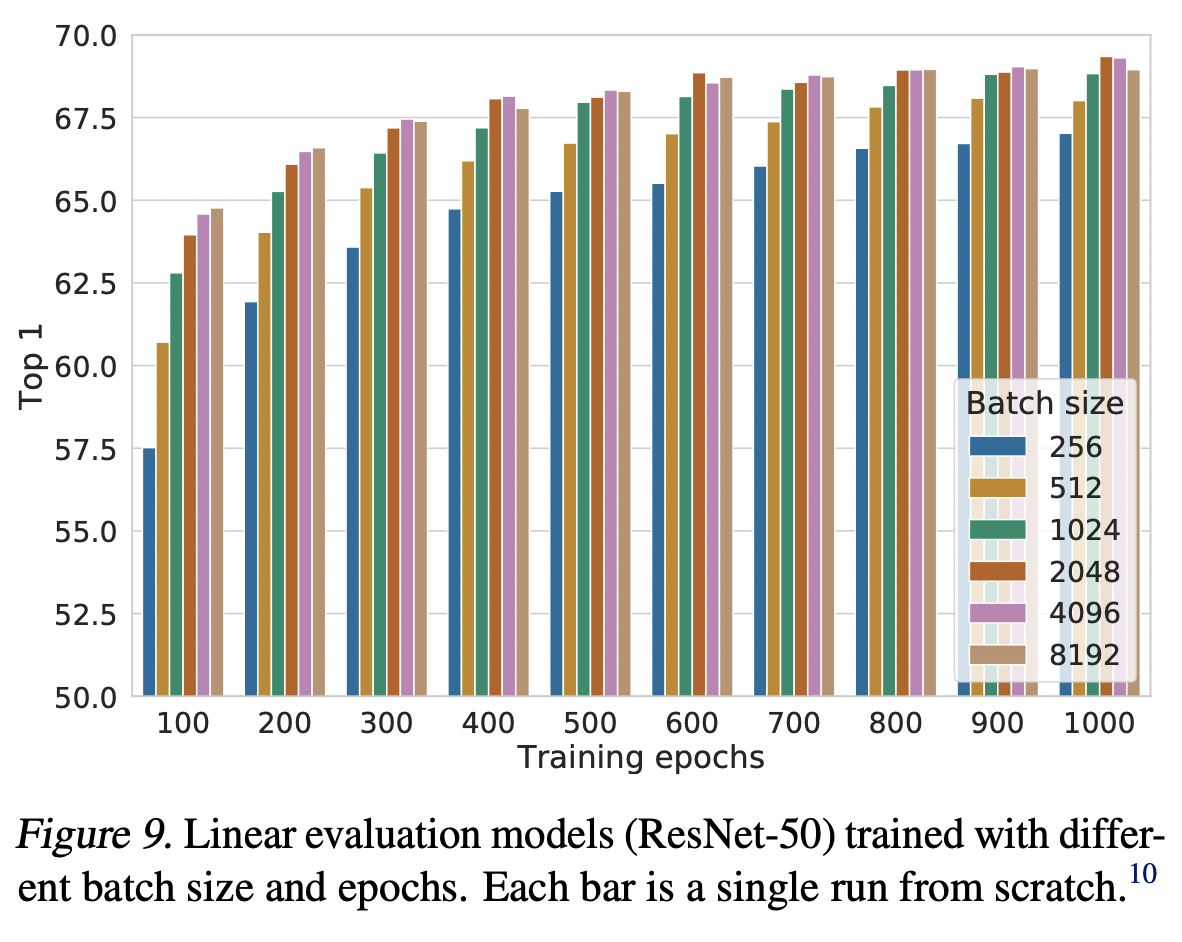
그림 9는 모델이 서로 다른 수의 에폭에 대해 훈련될 때 배치 크기의 영향을 보여준다. 우리는 훈련 에폭의 수가 적을 때(예: 100 에폭) 더 큰 배치 크기가 더 작은 배치에 비해 상당한 이점이 있다는 것을 발견했다. 더 많은 교육 단계/에포치(epoch)를 통해, 배치가 무작위로 재샘플링될 경우, 서로 다른 배치 크기 간의 격차가 감소하거나 사라진다.
Comparison with State-of-the-art
Linear Evaluation
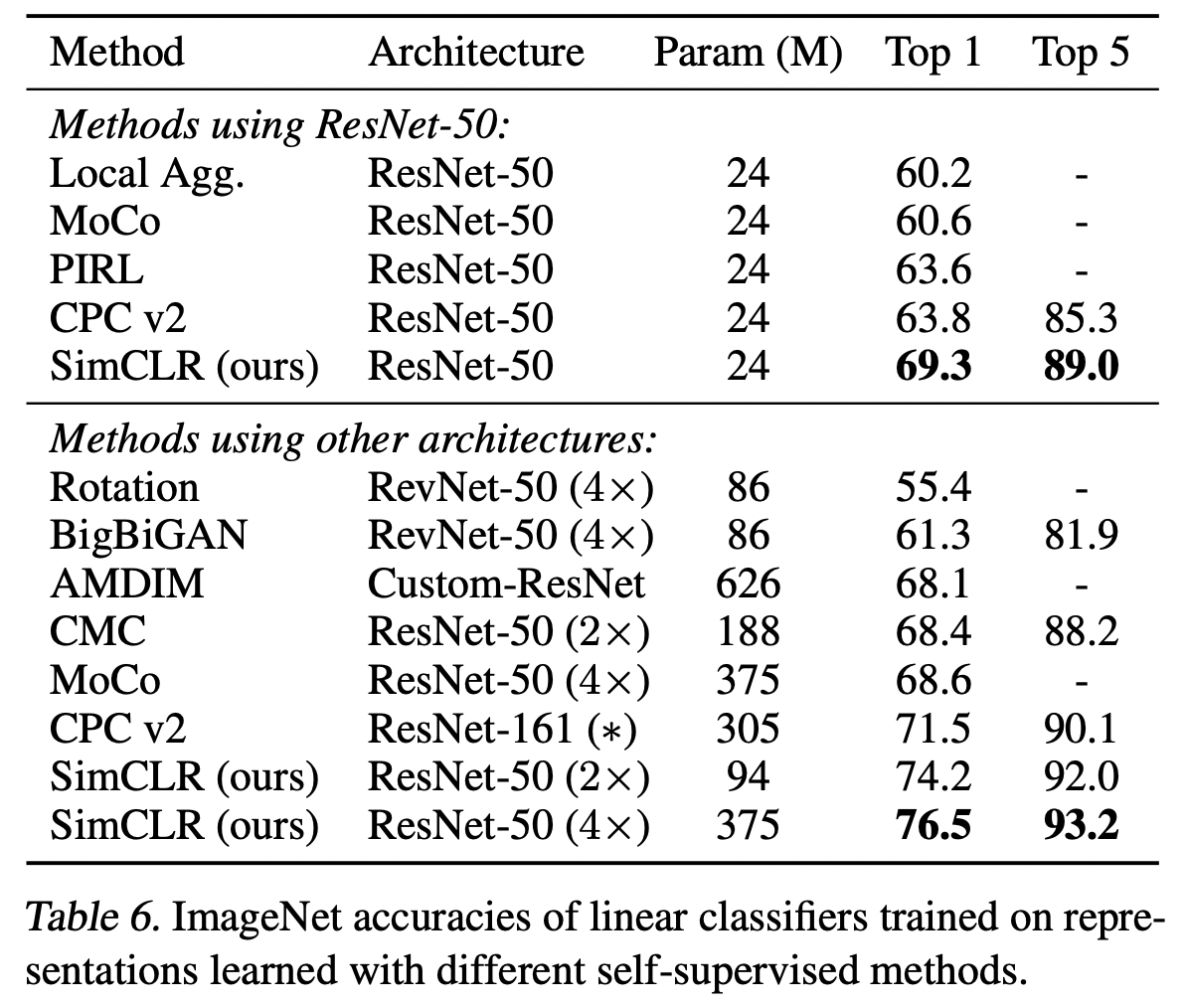
표 6은 우리의 결과를 선형 평가 설정의 이전 접근법과 비교한다(부록 B.6 참조). 표 1은 다른 방법들 사이의 더 많은 수치 비교를 보여준다. 우리는 표준 네트워크를 사용하여 특별히 설계된 아키텍처를 필요로 하는 이전 방법에 비해 훨씬 나은 결과를 얻을 수 있다. ResNet-50(4×)으로 얻은 최상의 결과는 감독된 사전 훈련된 ResNet-50과 일치할 수 있다.
Semi-supervised Learning
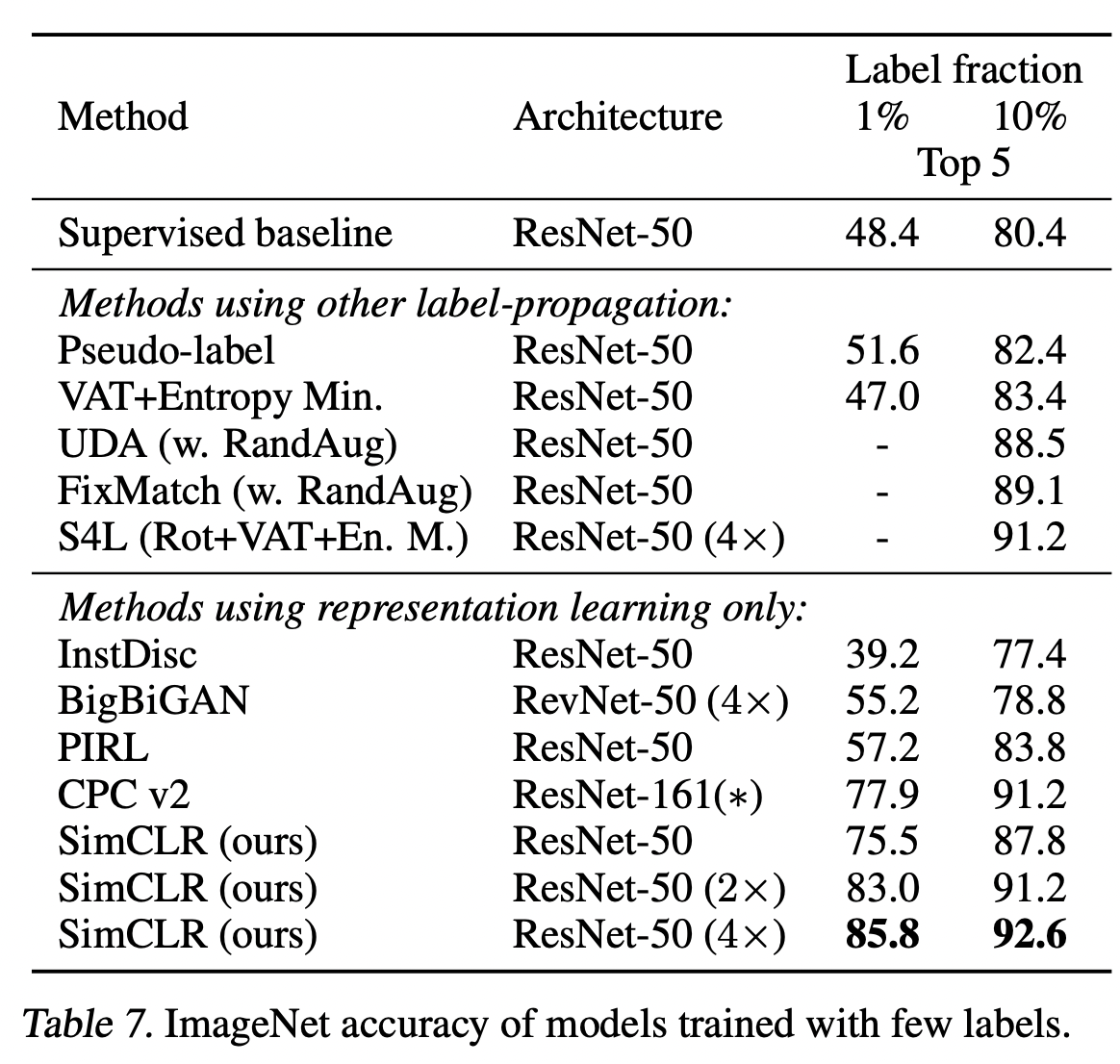
우리는 Zhail et al.(2019)를 따르고 레이블이 지정된 ILSVRC-12 훈련 데이터 세트의 1% 또는 10%를 클래스 균형 잡힌 방식으로 샘플링한다(각각 클래스당 ~12.8 및 ~128개의 이미지). 정규화 없이 레이블링된 데이터에서 전체 기본 네트워크를 미세 조정할 수 있습니다. 표 7은 최근 방법과의 결과를 비교한 것입니다. (Zhai et al., 2019)의 감독 기준선은 (증강 포함) 하이퍼 파라미터의 집중적인 검색으로 인해 강력하다. 다시 말하지만, 우리의 접근 방식은 1%와 10%의 레이블을 모두 사용하여 최첨단보다 크게 개선된다. 흥미롭게도, 전체 ImageNet에서 사전 훈련된 ResNet-50(2×, 4×)을 미세 조정하는 것도 처음부터 훈련하는 것보다 훨씬 낫다(최대 2%는 부록 B.2 참조).
Transfer Learning
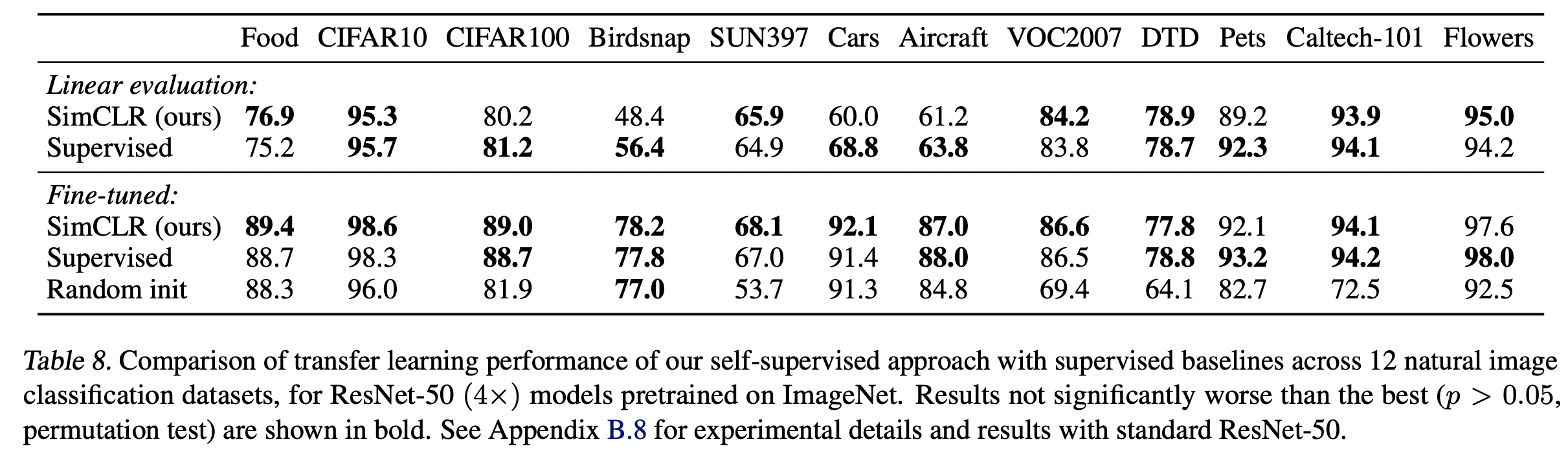
선형 평가(고정 특징 추출기)와 미세 조정 설정 모두에서 12개의 자연 이미지 데이터 세트에 걸친 전송 학습 성능을 평가한다. Kornblith 외(2019)에 이어 각 모델-데이터 세트 조합에 대해 하이퍼 파라미터 조정을 수행하고 검증 세트에서 최상의 하이퍼 파라미터를 선택한다. 표 8은 ResNet-50(4x) 모델의 결과를 보여줍니다. 미세 조정 시 자체 감독 모델은 5개의 데이터 세트에서 감독 기준선을 크게 능가하는 반면, 감독 기준선은 2개에서만 우수하다.
Conclusion
본 연구에서는 대조적인 시각적 표현 학습을 위한 간단한 프레임워크와 그 인스턴스를 제시한다. 우리는 그것의 구성 요소를 주의 깊게 연구하고, 다양한 디자인 선택의 효과를 보여준다. 우리의 연구 결과를 결합함으로써, 우리는 자가 지도, 준 지도 및 전이 학습을 위한 이전의 방법보다 상당히 개선된다.
제안하는접근 방식은 데이터 확대, 네트워크 끝에서의 비선형 헤드의 사용 및 손실 함수 선택에서만 ImageNet의 표준 지도 학습과 다르다. 이 간단한 프레임워크의 강점은 최근 관심이 급증했음에도 불구하고 자체 지도 학습이 여전히 저평가되어 있음을 시사한다.