논문 리뷰 : Taming Transformers for High-Resolution Image Synthesis(2021)
Introduction
CNN은 비전 작업에 사용할 수 있는 믿을수 있는(reliable)한 모델임. 왜냐면 kernel의 사용으로 인해서 CNN이 강한 locality bias와 shared weight의 사용을 통해 spatial invariance에 대한 편향을 보이기 때문임 .
CNN과 비교하여, Transformer는 로컬 상호 작용을 우선 처리하는 inductive bias를 포함하고 있지 않으므로 입력 간의 복잡한 관계를 학습할 수 있음. 즉, 표현력을 높임. 그러나, 이는 long sequence일 경우 계산 비용이 많이 듬.
Transformer의 표현력은 항상 2차식으로 증가하는 계산 비용을 수반함
생성모델
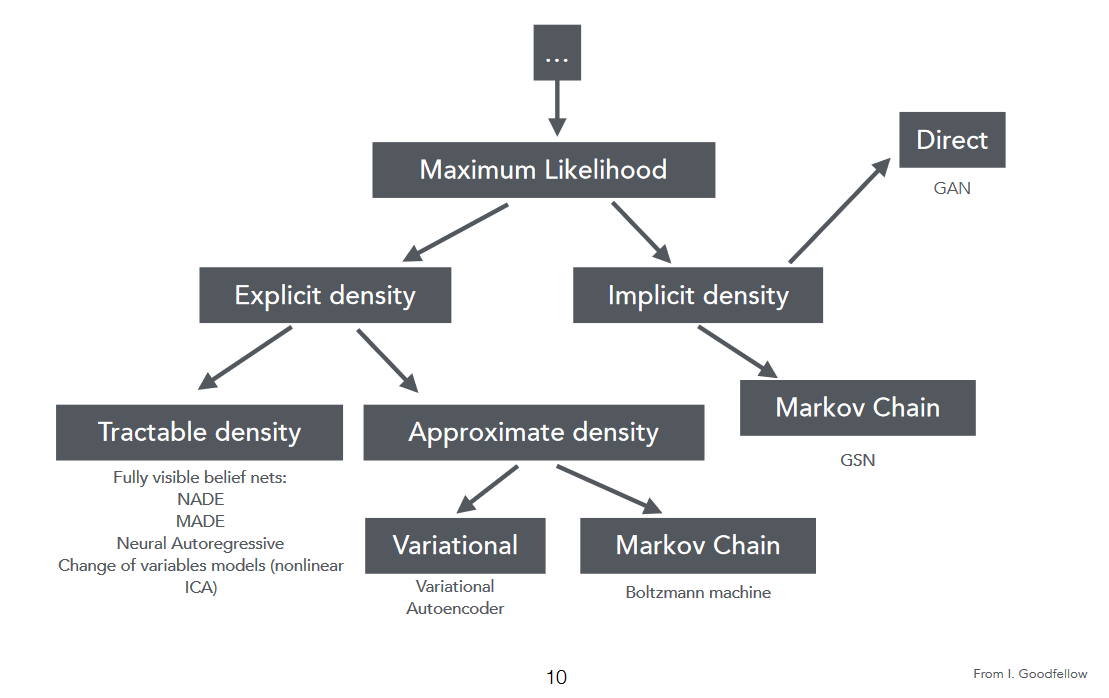
이 그림에서 생성모델의 두가지 주요 유형을 구별할 수 있음
- Likelihood based(explicit) models : 이러한 모델은 데이터 분포의 explicit한 parametric specification을 제공하며 다루기 쉬운 likelihood function을 갖추고 있음. 예를 들어 VAE와 Autoregressive model이 이에 해당함
- Implicit models : 데이터 자체의 분포를 지정하지는 않음. 그러나 대신 훈련 후 근본적인 데이터 분포에서 샘플 추출을 목적으로 하는 확률 과정 (stochastic process)를 정의함. 예를 들어 Generative Adversarial Modles (GAN)이 있음
이 논문의 핵심 아이디어는 다음과 같음
- GAN은 암묵적으로 평가하지 어려우며 일반적으로 데이터의 모든 mode를 커버할 수 없으므로 mode collapse에 더 취약함
- likelihood 기반 모델은 모델 비교를 용이하게 하고 처음 보는 데이터에 대한 일반화를 개선하는, 훈련 데이터의 negative log likelihood를 최소화함. 그러나 픽셀공간에서는 likelihood를 최적화하 하는것이 까다롭고 계산 비용이 많이 듬.
Propsed Method
이미지 생성에 transformer를 적용한 이전의 작업은 최대 크기 64x64의 이미지의 경우에는 좋은 결과를 보여주었으나 시퀀스 길이와 함께 2차식으로 증가하는 비용으로 인해 더 높은 해상도로는 확장할 수 없었음. 따라서 더 높은 해상도의 이미지를 합성하기 위해 transformer를 사용하려면 이미지의 semantics를 명확학 표현해야함. 픽셀 해상도의 2배 증가와 함께 픽셀의 수를 2차식으로 증가하기 때문에 픽셀 표현 사용은 가능하지 않음
벡터 양자화 (Variational Autoencoder (VQ-VAE))
해당 논문은 VQ-VAE(벡터 양자화 변분 오토인코더)에서 영감을 얻었음.
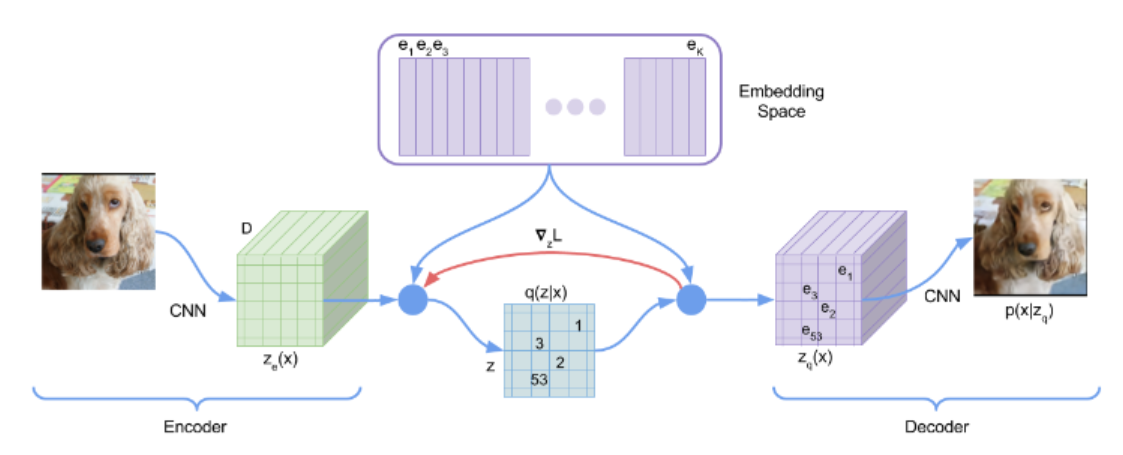
VQ-VAE는 관측 결과(이미지)를 이상 잠재 변수(discrete latent variables)에 매핑하는 인코더와 이러한 이산 변수로부터의 관측 결과를 재 구축하는 디코더로 구성됨. 이들은 공유된 코드북을 사용함.
위의 그림에서 나타난 바와 같이 이미지 x가 인코더를 거쳐 E(x)를 생성하고 그런 다음 각 벡터가 코드북에서 가장 가까운 코드 벡터의 인덱스로 대체되도록 코드 벡터 ei 까지의 거리를 기반으로 양자화됨
Taming Transformer
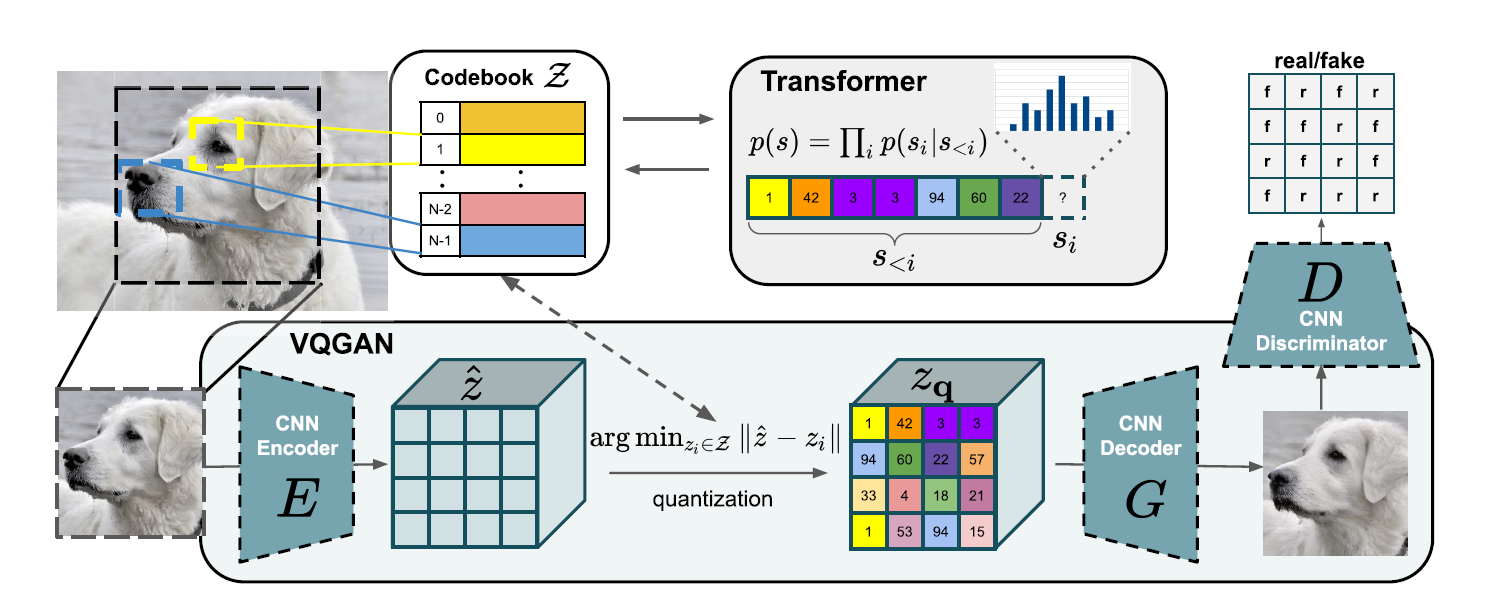
시퀀스 길이를 짧게 유지하고 transformer의 표현성을 활용하기 위해 저자는 학습된 표현(VQ-VAE에서 영감 받은) 이산 코드북을 사용하며 이미지는 코드북 엔트리의 공간 모음(spatial collection)에 의해 표현될 수 있음.
위의 그림에서 나타난 바와 같이 저자들은 VQ-VAE의 변형인 VQ-GAN을 사용했음.
vQ-GAN 훈련
VQ-GAN은 adversarial training을 통해 훈련됨. 최적 압축 모델 Q*은 아래와 같이 구해질 수 있음 .
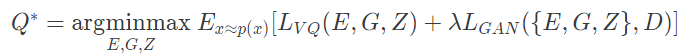
Transformer 훈련
인덱스가 주어지면 트랜스포머는 가능한 다음 인덱스의 분포를 예측하도록 학습하며 loss function은 아래와 같다.
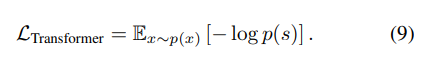
초해상도 이미지 생성
시퀀스 길이의 증가와 더불어 transformer 훈련 비용의 2차적인 증가는 시퀀스 길이를 제한함. 따라서 메가 픽셀 영역에서 이미지를 생성하기 위해, 저자는 패치별로 작업하고 s의 길이를 훈련 중 최대로 실현 가능한 크기로 제한하기 위해 이미지를 crop함
이미지를 샘플링하기 위해 아래 그림처럼 슬라이딩 윈도우 방식으로 transformer가 사용됨

Reference
https://wandb.ai/wandb_fc/korean/reports/-Transformer-Taming—Vmlldzo1MDA5NTA