Introduction
기존 연구의 한계점은
첫째, Instance level representation은 시계열 예측 및 이상 탐지와 같이 세분화된 표현이 필요한 작업에 적합하지 않을 수 있다. 이러한 종류의 작업에서는 특정 타임스탬프 또는 하위 시리즈에서 대상을 유추해야 하는 반면 전체 시계열의 coarse representation은 만족스러운 성능을 달성하기에 충분하지 않다.
둘째, 기존 방법 중 세분성이 다른 다중 스케일 상황 정보를 구별하는 방법은 거의 없다. 예를 들어, TNC(Tonekaboni, Eytan, Goldenberg 2021)는 길이가 일정한 세그먼트를 구별합니다. T-loss는 원래 시계열의 랜덤 하위 시리즈를 양의 표본으로 사용한다. 그러나 두 가지 모두 시계열 작업의 성공에 필수적인 스케일 불변 정보를 캡처하기 위해 서로 다른 척도로 시계열을 특징으로 하지 않는다. 직관적으로, 멀티 스케일 기능은 다양한 수준의 의미론을 제공하고 학습된 표현의 일반화 능력을 향상시킬 수 있다.
셋째, 대부분의 기존 비지도 시계열 표현 방법은 transformation-invariance및 cropping-invariance과 같은 강한 inductive bias를 갖는 CV 및 NLP 도메인의 경험에서 영감을 얻었다. 그러나 그러한 가정이 시계열 모델링에 항상 적용되는 것은 아니다. 예를 들어, 자르기(cropping)는 이미지에 자주 사용되는 확대 전략이다. 그러나 시계열의 분포와 의미론은 시간이 지남에 따라 변할 수 있으며 잘린 하위 시퀀스는 원래 시계열에 대해 뚜렷한 분포를 가질 가능성이 있다.
이러한 문제를 해결하기 위해, 본 논문은 TS2Vec이라는 보편적인 대조 학습 프레임워크를 제안하며, 이는 모든 의미론적 수준에서 시계열의 표현 학습을 가능하게 한다. 인스턴스별 및 시간적 차원에서 양 및 음의 샘플을 계층적으로 구별하며, 임의의 하위 시리즈의 경우 전체 표현은 해당 타임스탬프에 대한 최대 풀링으로 얻을 수 있다. 이를 통해 모델은 시간 데이터에 대한 여러 해상도에서 상황별 정보를 캡처하고 세분화된 표현을 생성할 수 있다. 더욱이, TS2Vec의 대조적인 목표는 확장된 컨텍스트 뷰를 기반으로 한다. 즉, 두 개의 증강 컨텍스트에서 동일한 하위 시리즈의 표현이 일관적이어야 한다. 이러한 방식으로, 우리는 변환 및 자르기 불변과 같은 인식되지 않은 유도 편향을 도입하지 않고 각 하위 시리즈에 대한 강력한 컨텍스트 표현을 얻는다.
Contribution
- 우리는 다양한 semantic 수준에서 임의의 하위 시리즈에 대한 문맥 표현을 학습하는 통합 프레임워크인 TS2Vec을 제안한다. 우리가 아는 한, 이것은 시계열 분류, 예측 및 이상 탐지를 포함하지만 이에 제한되지 않는 시계열 도메인의 모든 종류의 작업에 대해 유연하고 보편적인 representation 방법을 제공하는 첫 번째 작업이다.
- 위의 목표를 해결하기 위해, 우리는 constrictive 학습 프레임워크에서 두 가지 새로운 디자인을 활용한다. 첫째, 인스턴스별 및 시간적 차원 모두에서 계층적 대조 방법을 사용하여 다중 스케일 컨텍스트 정보를 캡처한다. 둘째, 긍정적인 쌍 선택을 위한 상황별 일관성을 제안한다. 기존 최첨단 기술과 달리 다양한 분포와 척도를 가진 시계열 데이터에 더 적합하다. 광범위한 분석은 결측값이 있는 시계열에 대한 TS2Vec의 견고성을 입증하며, 계층적 대조와 맥락적 일관성의 효과는 ablation 연구를 통해 검증된다.
- TS2Vec은 분류, 예측 및 이상 탐지를 포함한 세 가지 벤치마크 시계열 작업에서 기존 SOTA를 능가한다. 예를 들어, 우리의 방법은 분류 작업에 대한 최고의 비지도 표현 SOTA와 비교하여 125개의 UCR 데이터 세트에서 평균 2.4%, 29개의 UEA 데이터 세트에서 3.0%의 정확도를 향상시킨다.
Method
Time Series에 instance가 N개 있을때, 목표는 각 x_i 를 잘 나타낼 수 있는 nolinear embedding function f를 학습하는 것이다.
Model Architecture
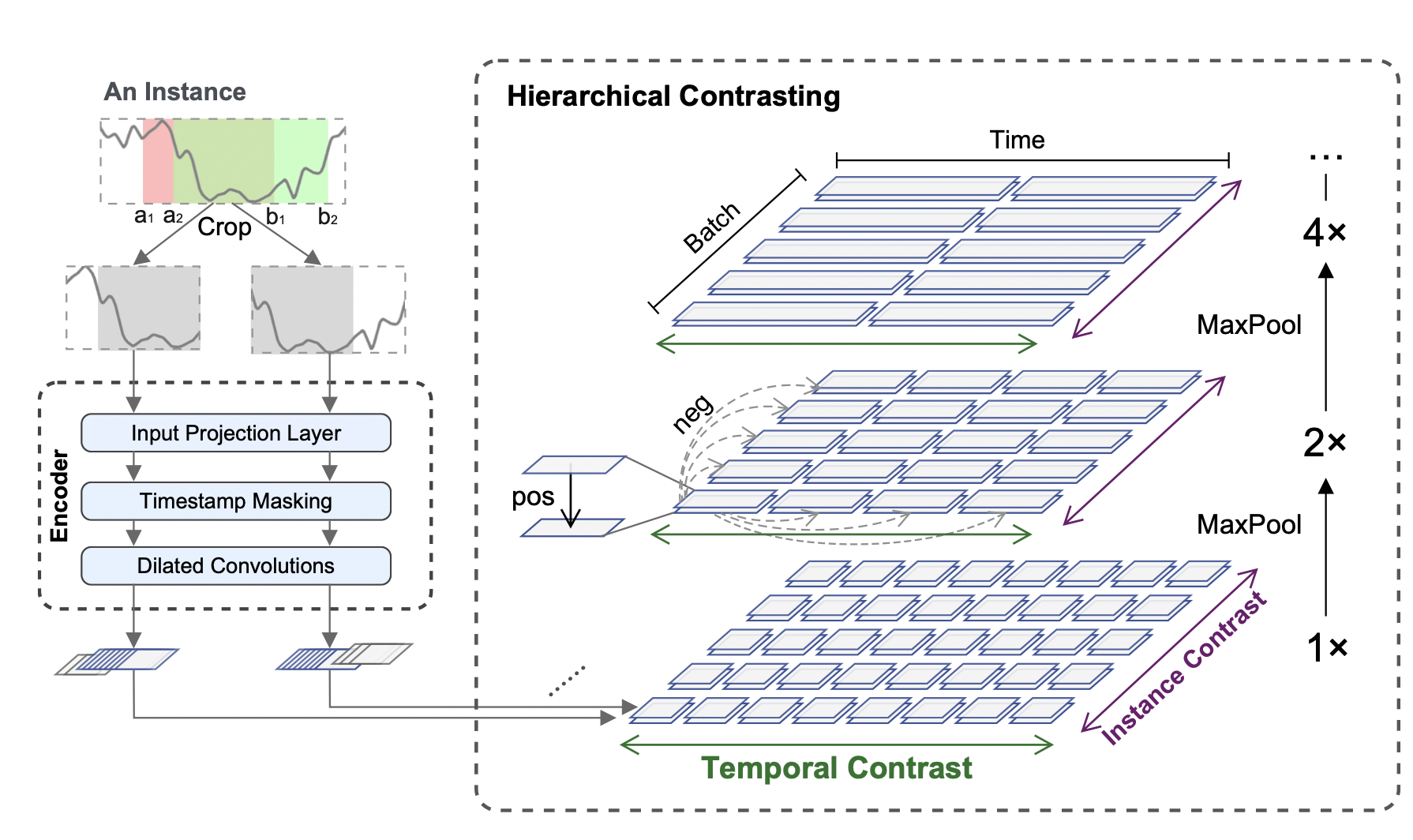
전체적인 구조는 위의 그림과 같다. 입력 시계열 x_i 에서 두 개의 겹치는 하위 시리즈를 무작위로 샘플링하고 공통 segment에서 컨텍스트 representation의 일관성을 권장한다. 원시 입력은 시간 대비 손실 및 인스턴스별 대비 손실과 함께 최적화된 인코더로 공급된다. 총 손실은 계층적 프레임워크에서 여러 척도에 걸쳐 합산된다.
인코더 f는 input projection 계층, 타임스탬프 마스킹 모듈 및 dialated CNN 모듈을 포함한 세 가지 구성 요소로 구성된다. 각 입력 x_i에 대해, input projection 레이어는 타임스탬프 t에서 관측 x_it 고차원 잠재 벡터 z_it에 매핑하는 fully connected layer이다. 타임스탬프 마스킹 모듈은 무작위로 선택된 타임스탬프에서 잠재 벡터를 마스킹하여 augmneted context view를 생성한다. 시계열에 대한 값 범위는 무한할 수 있고 원시 데이터에 대한 특수 토큰을 찾는 것이 불가능하기 때문에 원시 값보다는 잠재 벡터를 마스킹한다.
그런 다음 10개의 residual 블록이 있는 dialated CNN 모듈을 적용하여 각 타임스탬프에서 컨텍스트 representation을 추출한다. 각 블록에는 확장 매개 변수가 있는 두 개의 1-D 컨볼루션 레이어가 포함되어 있다. dialated 컨볼루션은 서로 다른 도메인에 대해 큰 receptive field를 가능하게 한다.
Contextual Consistency
이전 연구들은 아래 그림처럼 various selection strategy를 사용했다.
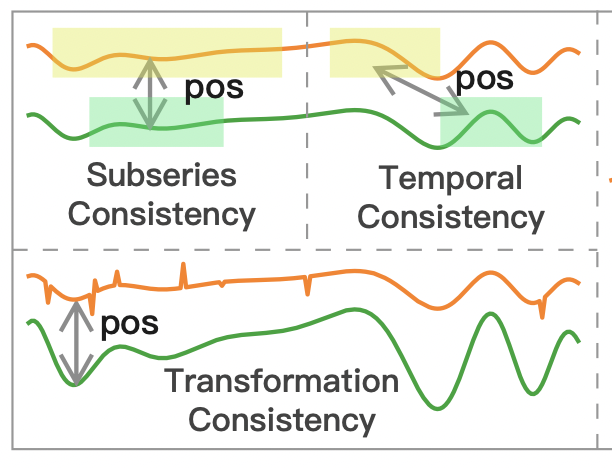
이전 연구 방법들을 요약해보자면
- Subseries consistency(Franceschi, Dieuleveut, Jaggi 2019) 는 시계열의 표현이 샘플링된 하위 시리즈에 더 가깝도록 장려한다.
- Temporal consistency(Tonekaboni, Eytan, Golden-berg 2021)는 인접한 세그먼트를 positive 샘플로 선택하여 표현의 국소적 smoothness을 강화한다.
- Transformation consistency(Eldle et al. 2021)은 스케일링, permutation 등과 같은 다양한 변환에 의해 input time series을 augment시켜 모델이 변환 불변 표현을 학습하도록 장려한다.
그러나 위의 전략은 데이터 분포에 대한 강력한 가정을 기반으로 하기 때문에 시계열 데이터에 적합하지 않을 수 있다.
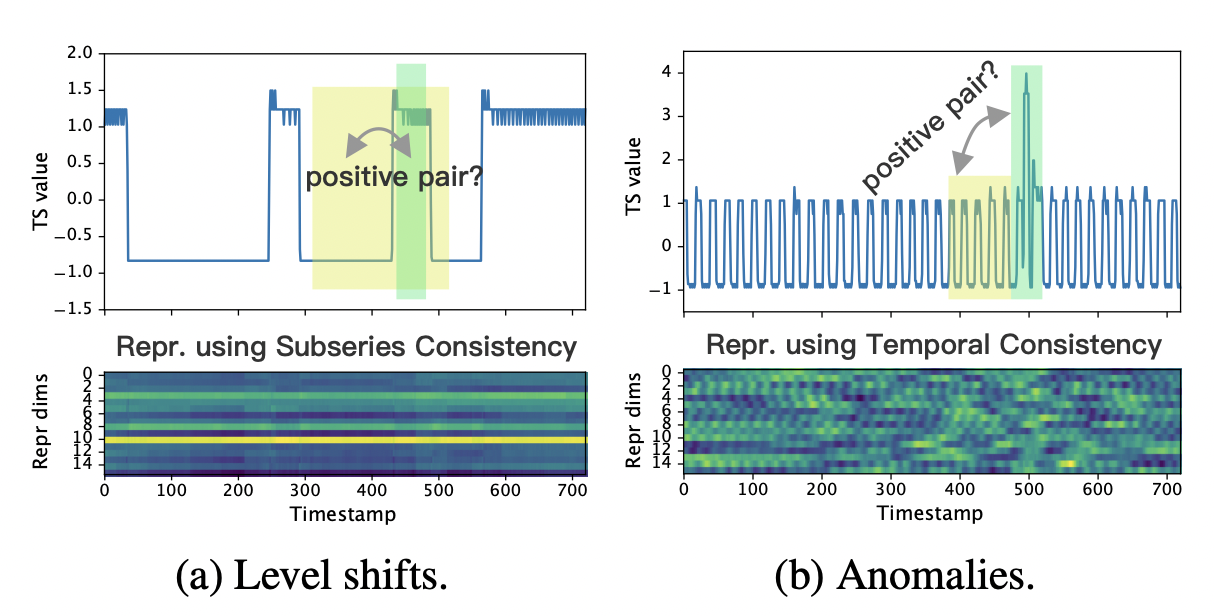
예를 들어, subseries 일관성은 level shift가 있을 때 취약하며(그림 3a), 시간 일관성은 이상이 발생할 때 잘못된 양의 쌍을 발생시킬 수 있다(그림 3b). 이 두 그림에서 녹색과 노란색 부분은 서로 다른 패턴을 보이지만 이전 전략에서는 비슷한 패턴으로 간주한다. 이 문제를 극복하기 위해, 우리는 두 개의 augmented 컨텍스트에서 동일한 타임스탬프의 표현을 긍정적인 쌍으로 처리하는 새로운 전략인 contextual consistency을 제안한다. 입력 시계열에 타임스탬프 마스킹 및 랜덤 자르기 기능을 적용하여 컨텍스트가 생성된다. 이점은 두 가지입니다. 첫째, 마스크와 자르는 것은 시계열에 중요한 시계열의 크기를 바꾸지 않는다. 둘째, 그들은 또한 각 타임스탬프가 별개의 컨텍스트에서 자신을 재구성하도록 강요함으로써 학습된 표현의 견고성을 향상시킨다.
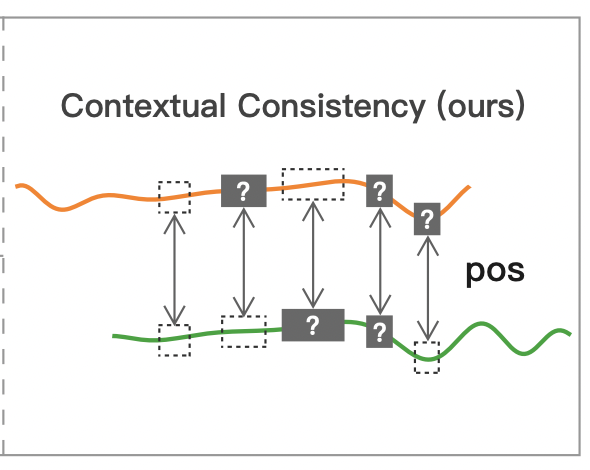
- Timestamp Masking
- 인스턴스의 타임스탬프를 무작위로 마스킹하여 새로운 컨텍스트 뷰를 생성한다.
- Random Cropping
- 랜덤 크롭은 또한 새로운 컨텍스트를 생성하기 위해 채택된다. overlapped segemnt [a2,b1]의 상황별 표현은 두 가지 상황별 검토에 대해 일관성이 있어야 한다. 타임스탬프 마스킹 및 랜덤 자르기 기능은 교육 단계에서만 적용된다.
Hierarchical Contrasting
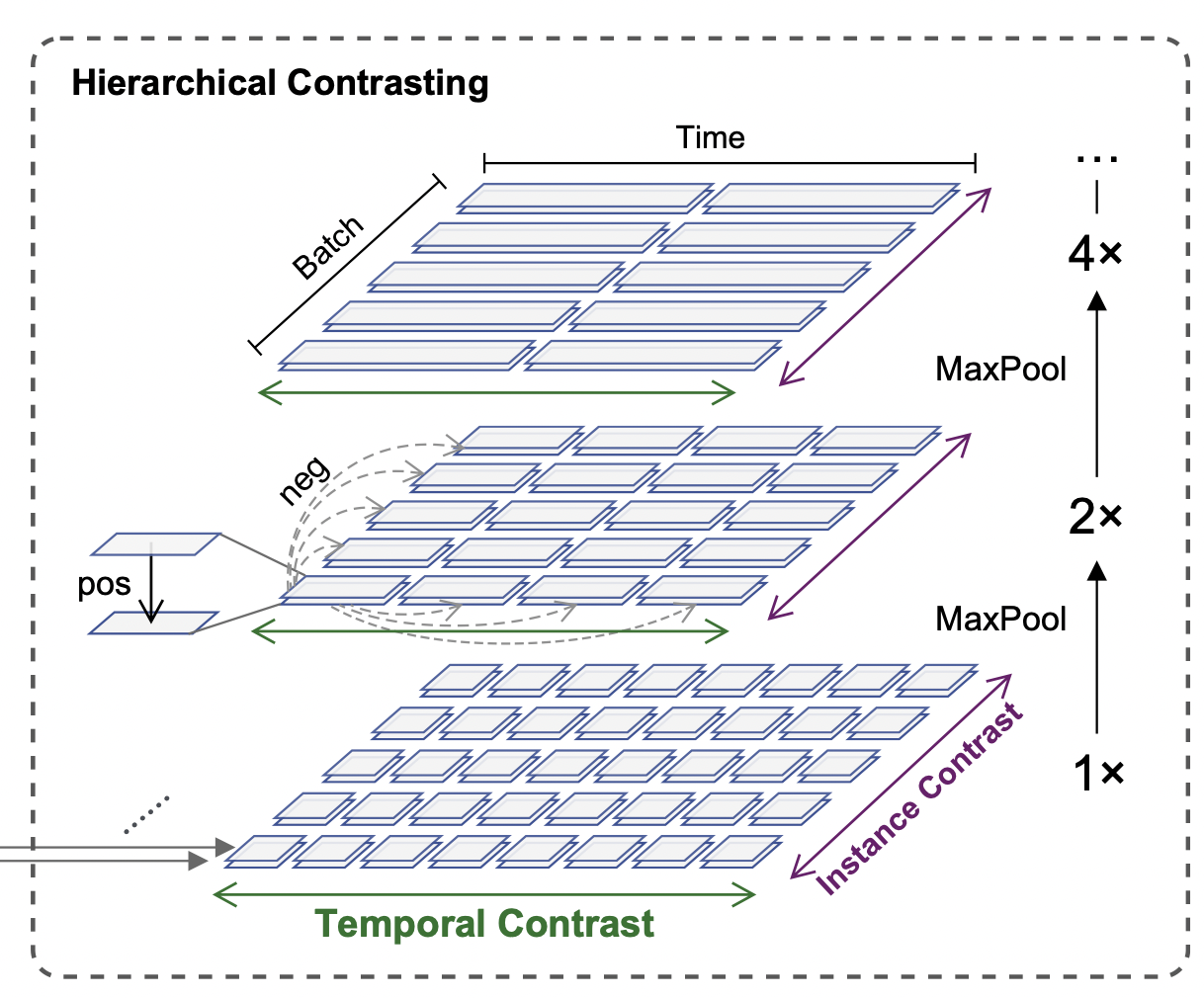
이 섹션에서는 인코더가 다양한 척도로 표현을 학습하도록 하는 계층적 contrastive loss을 제안한다. 타임스탬프 level 표현을 기반으로, 우리는 시간축을 따라 학습된 표현에 대해 maxpooling을 적용하고 방정식 3을 재귀적으로 계산한다. 특히 상위 의미 수준에서의 대조를 통해 모델은 인스턴스 수준 표현을 학습할 수 있다.
시계열의 문맥적 표현을 포착하기 위해 instance-wise 및 temporal 대조 손실을 공동으로 활용하여 시계열 분포를 인코딩한다. 손실 함수는 계층적 대조 모델의 모든 세분화 수준에 적용된다.
» Temporal Constrastive Loss
시간에 따른 차별적 표현을 학습하기 위해 TS2Vec은 입력 시계열의 두 가지 뷰에서 동일한 타임스탬프의 표현을 긍정으로 취하는 반면 동일한 시계열의 다른 타임스탬프에 있는 표현을 부정으로 사용한다. i를 입력 시계열 샘플의 인덱스로 하고 t를 타임스탬프로 할때 r_it와,r’는 x_i의 두 개의 증대에서 나온 동일한 타임스탬프 ti,t에 대한 표현을 나타낸다. 타임스탬프 t에서 i번째 시계열에 대한 시간 대비 손실은 다음과 같이 공식화될 수 있다.
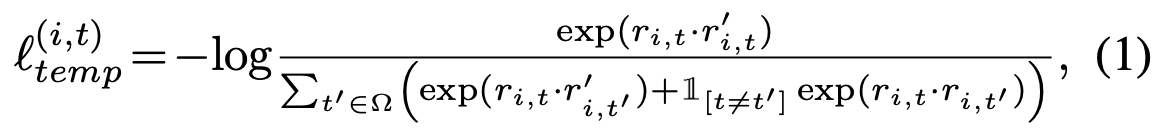
» Instance-wise Contrastive Loss
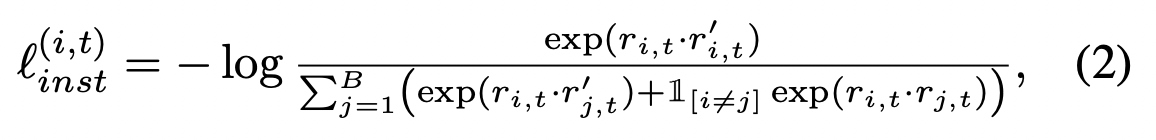
Instance-wise Contrastive loss는 위와같이 공식화 될 수 있다.
두그 두 손실은 서로 보완적이다. 예를 들어 여러 사용자의 전기 소비 데이터 세트가 주어지면 인스턴스 대비는 사용자별 특성을 학습하는 반면 시간 대비는 시간에 따른 동적 추세를 채굴하는 것을 목표로 한다. 전체 손실은 다음과 같이 정의된다.
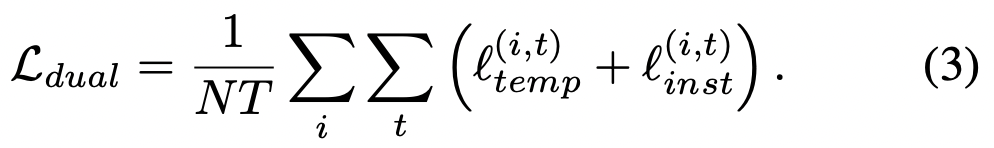
Experiment
Time Series Classification
분류 작업의 경우 클래스는 전체 시계열(인스턴스)에 레이블이 지정됩니다. 따라서 모든 타임스탬프에 대한 최대 풀링으로 얻을 수 있는 인스턴스 수준 표현이 요구된다.
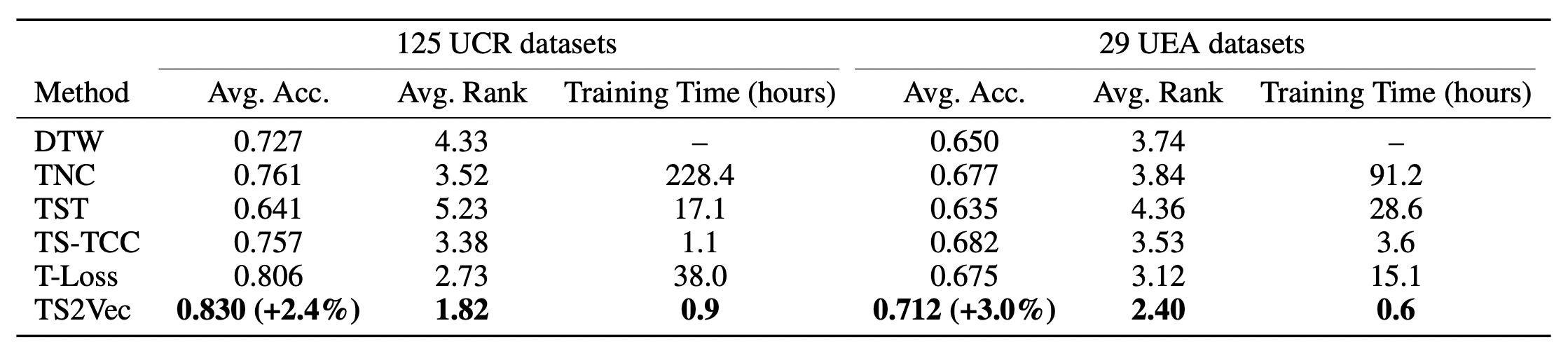
평가 결과는 위의 테이블이다. S2Vec은 UCR 및 UEA 데이터 세트 모두에서 다른 표현 학습 방법에 비해 상당한 개선을 달성한다. 특히 TS2Vec은 125개의 UCR 데이터 세트에서 평균 2.4%, 29개의 UEA 데이터 세트에서 3.0%의 분류 정확도를 향상시킨다.
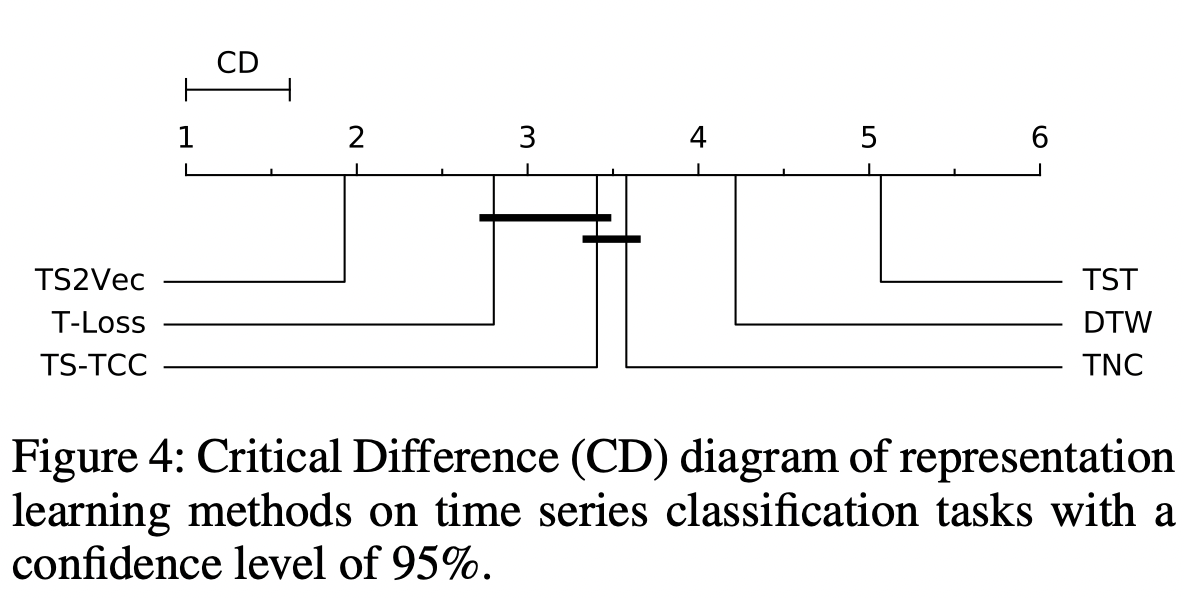
위의 그림에는 모든 데이터 세트(125개의 UCR 및 29개의 UEA 데이터 세트 포함)에 대한 Ne-menyi 테스트의 Critical Difference 다이어그램이 제시되어 있으며, 굵은 선으로 연결되지 않은 분류기는 평균 순위가 크게 다르다. 이는 TS2Vec이 평균 순위에서 다른 방법보다 월등히 우수한 성능을 발휘한다는 것을 검증한다.
Time Series Forecasting
구체적으로, 우리는 미래 값 xˆ를 직접 예측하기 위해 입력으로 r_t를 취하는 L2 Norm 패널티를 가진 선형 회귀 모델을 훈련한다. x가 단변량 시계열일 때, xθ는 차원 H를 갖는다. x가 F 형상이 있는 다변량 시계열인 경우 xθ의 치수는 FH여야 합니다.
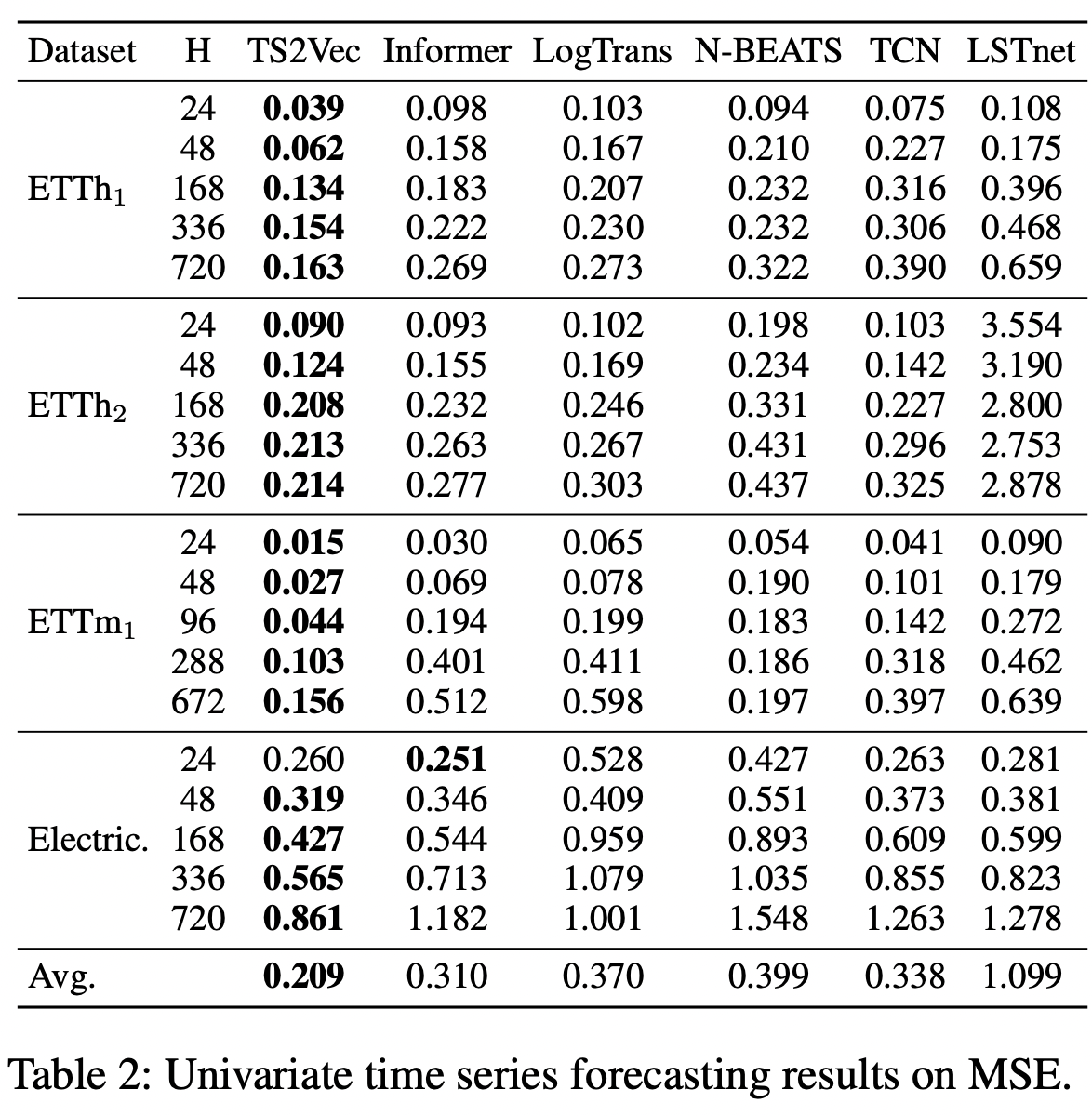
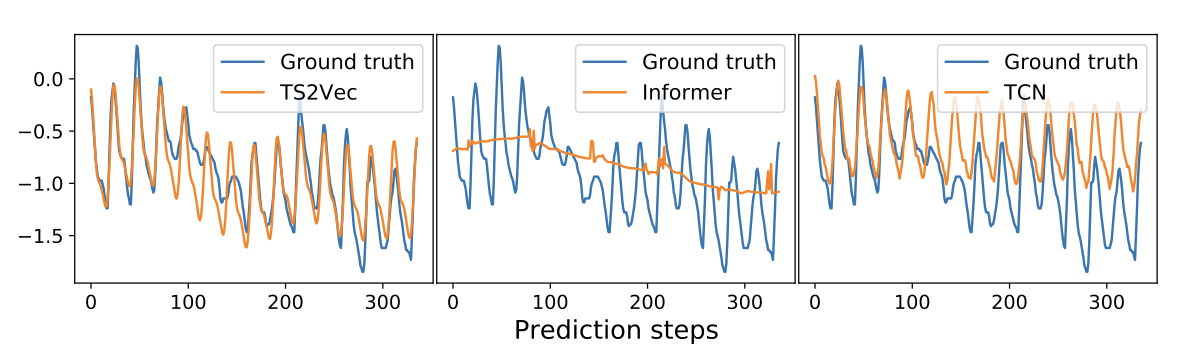
일반적으로 TS2Vec은 대부분의 경우 새로운 SOTA를 설정하는데, 여기서 TS2Vec은 일변량 설정에서 평균 MSE의 32.6%, 다변량 설정에서 28.2% 감소를 달성한다. 또한, representation 각 데이터 세트에 대해 한 번만 학습하면 되며, 학습된 표현의 보편성을 보여주는 선형 회귀를 가진 다양한 수평선(Hs)에 직접 적용될 수 있다. 그림 5는 일변량 예측에서 가장 잘 수행되는 상위 3가지 방법들을 비교하여 장기적인 추세와 주기적인 패턴을 가진 전형적인 예측 슬라이스를 보여준다. 이 경우 Informer는 장기적인 추세를 포착할 수 있는 능력을 보여주지만 주기적인 패턴을 포착하지 못한다. TCN은 주기적인 패턴을 성공적으로 포착하지만 장기적인 추세는 포착하지 못한다. TS2Vec은 두 가지 특성을 모두 포착하여 다른 방법보다 더 나은 예측 결과를 보여준다.
Time Series Anomaly Detection
시계열 슬라이스 x1, x2, …, xt가 주어지면 시계열 이상 검출 작업은 마지막 점 x_t가 이상인지 확인하는 것이다. 학습된 표현에서, 이상점은 정상점과 분명한 차이를 보일 수 있다(그림 7c).
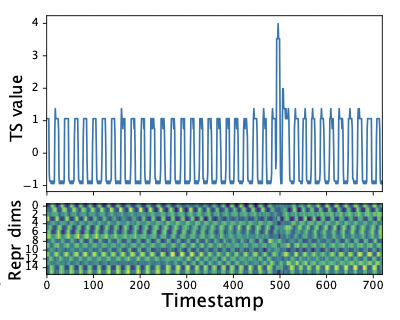
또한 TS2Vec은 인스턴스의 동일한 타임스탬프에 대한 상황별 일관성을 권장한다. 이를 고려하여 이상 점수를 마스킹된 입력과 마스킹되지 않은 입력에서 계산된 표현의 차이로 정의할 것을 제안한다. 특히, 추론 단계에서 훈련된 TS2Vec는 입력을 위해 두 번 전진한다. 첫 번째는 마지막 관찰 x_t만 마스크하고 두 번째는 마스크가 적용되지 않는다. 이 두 가지 전달에 대한 마지막 타임스탬프의 표현을 각각 r_tu와 r_tm으로 나타낸다. L1 거리는 이상 점수를 측정하는 데 사용된다.
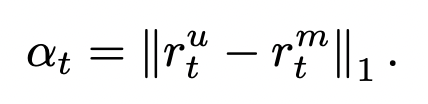
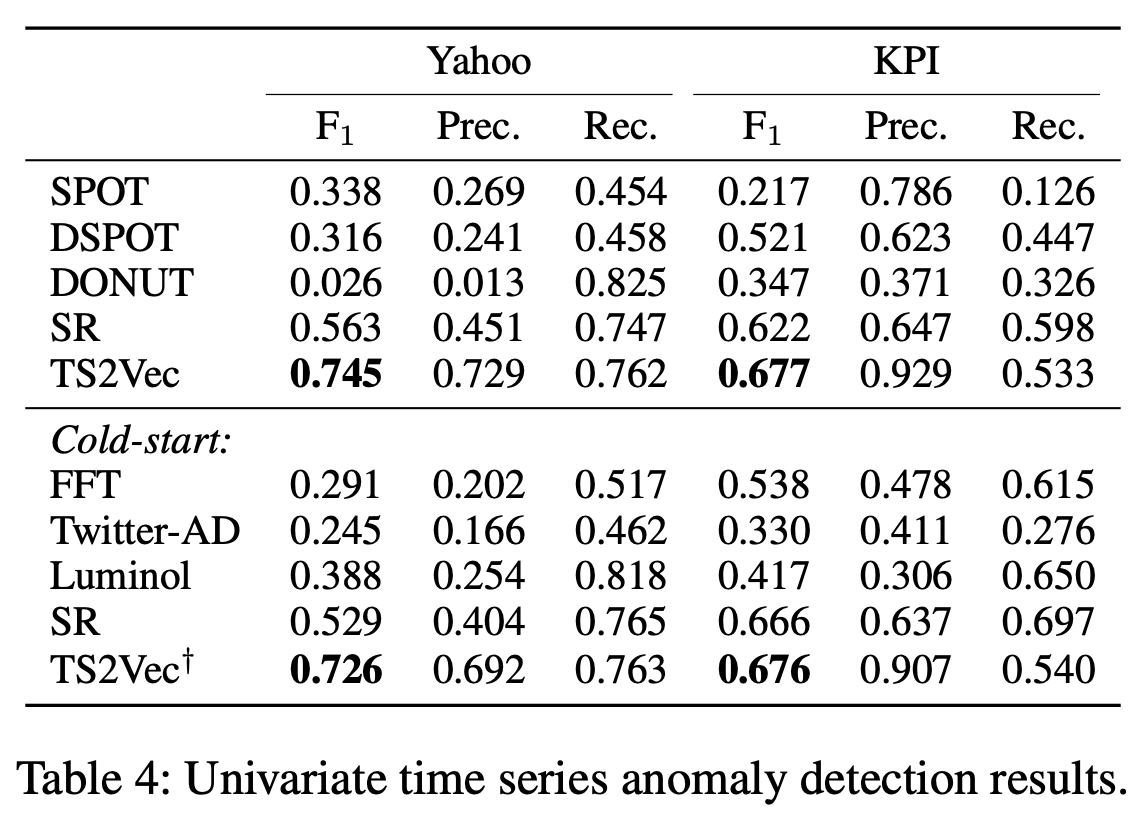
표 4는 F1 점수, 정밀도 및 리콜에 대한 다양한 방법의 성능 비교를 보여준다. 정상 설정에서 TS2Vec은 기준 방법의 최상의 결과와 비교하여 Ya-hoo 데이터 세트에서 F 점수를 18.2%, KPI 데이터 세트에서 5.5% 향상시킨다. 콜드 스타트 설정에서 F1 점수는 최상의 SOTA 결과보다 야후 데이터 세트에서 19.7%, KPI 데이터 세트에서 1.0% 향상된다. 우리의 방법은 이 두 가지 설정에서 유사한 점수를 획득하여 한 데이터 세트에서 다른 데이터 세트로 TS2Vec의 전송 가능성을 보여준다.
Conclusion
본 논문은 시계열을 위한 보편적인 표현 학습 프레임워크인 TS2Vec을 제안하는데, 이는 증강 컨텍스트 뷰 내에서 스케일 불변 표현을 학습하기 위해 계층적 대비를 적용한다. 세 가지 시계열 관련 작업(시계열 분류, 예측 및 이상 감지 포함)에 대한 학습된 표현의 평가는 TS2Vec의 보편성과 효과를 보여준다. 우리는 또한 TS2Vec이 불완전한 데이터를 제공할 때 꾸준한 성능을 제공한다는 것을 보여주는데, 이 경우 계층적 대조 손실과 타임스탬프 마스킹이 중요한 역할을 한다. 또한 학습된 표현의 시각화는 시계열의 역학을 포착하는 TS2Vec의 기능을 검증한다. 절제 연구는 제안된 구성 요소의 효과를 입증한다. TS2Vec의 프레임워크는 일반적이며 향후 작업에서 다른 도메인에 적용될 가능성이 있다.