Introduction
Motivation
Supervised Anomaly detection은 클래스 불균형 문제로 model의 일반화를 보장하지 못하고 레이블 작업은 비용과 노력이 ㅁ낳이 소요된다. 그에 대한 대안으로 one-class classification 알고리즘은 normal 데이터로만 학습시켜서 비정상 패턴을 식별한다. 그러나 해당 모델은 anomaly에 대한 해석력을 제공하지 못한다.
앞서 언급한 discriminative 모델에 비해 generative model은 데이터를 재구성한 다음 실제 데이터를 재구성된(예상) 데이터와 비교하여 이상 영역을 탐지한다. 따라서 생성모델은 discriminative 모델보다 해석하기 쉽다. 널리 쓰이는 생성모델은 predictive model과 reconstructed model이다.
AE의 확장 모델인 RAE는 순차적 데이터를 처리한다. RAE는 두개의 RNN으로 구성되어있는데 뛰어난 성능을 보여주지만 두가지 단점이 있다.
- RAE는 교육 단계에서 user-defined window size에 과적합된 출력 시퀀스를 생성한다.
- 큰 window size는 컨텍스트 벡터가 입력 시퀀스의 모든 정보를 인코딩하는 것을 어렵게 만든다. 또한 창 크기가 크면 그레디언트 문제가 사라지거나 폭발하는 등 장기적인 의존성 문제가 발생하여 RAE의 정확도가 저하된다.
이러한 문제를 해결하기 위해 RRN을 제안한다.
Contribution
RRN의 streaming data에 대한 이상 탐지를 위한 3가지 기능 1) self attention mechanism : long-term dependency 문제 해결하기 위해 고안. 고안된 attention mechanism은 entire input sequence에 대한 고려 없이 output sequence를 생성한다. 2) hidden state forcing : decoding hidden state가 encoding hidden state를 따르도록 강제한다. 입력 시퀀스의 모든 부분 정보가 윈도우 크기에 관계없이 디코딩 상태의 마지막 상태로 전파되도록 한다. 3) skip transition : 기존의 recurrent unit은 노드 간의 제한된 연결을 포함하여 정보 경로를 제한한다. 연속적인 시간 단계 사이의 피드백 전환 또는 건너뛰기 전환이 있는 recurrent unit은 recurrent unit 간의 연결 패턴을 더 조밀하게 만든다. 피드백 및 건너뛰기 전환을 모두 포함하는 반복 단위는 정보의 흐름에서 서로 간섭할 수 있다. 스킵 전환만 사용하여 recurent unit을 조밀하고 효율적으로 연결함으로써 RRN의 이상 감지 성능이 향상된다.
Related Work
Encoder-Decoder Model
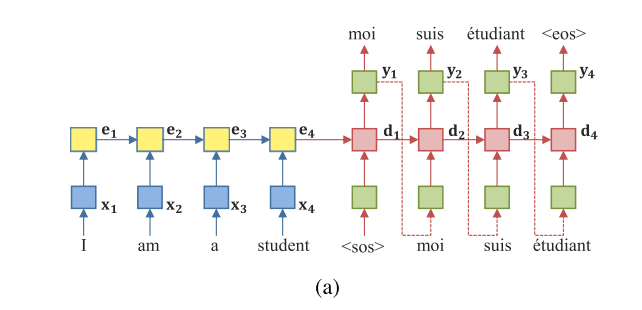
위의 그림은 일반적인 encoder-decoder 모델 구조이다. encoder에서는 variable-length 만큼 feature를 추출한다. 추출된 feature는 고정된 길이의 벡터로 표현된다. (a)에서의 변수들은 아래 식 (1) (2a) (2b)에서 확인할 수 있다.
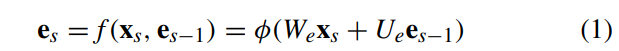
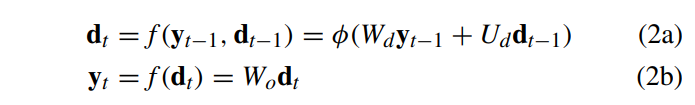
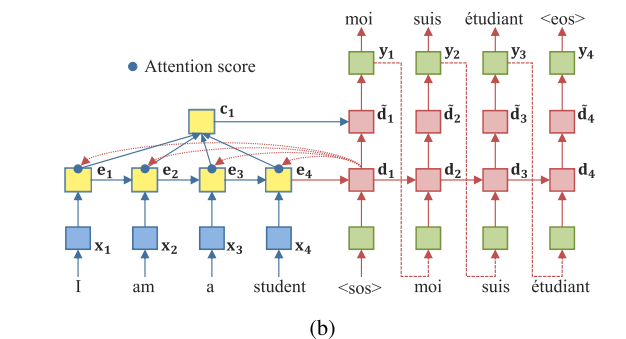
위의 그림은 attention mechanism이다. attention 메커니즘은 디코더에 추가정보를 제공하고 모델이 출력을 생성할때 source sequence에서 어디에 초점을 두어야 하는지 학습할 수 있도록 한다. 위 그림에서의 context vector c_t는 아래 식과 같이 표현된다.
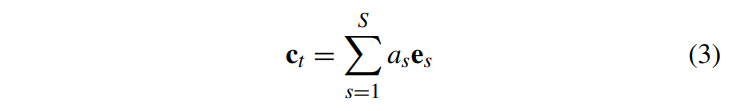
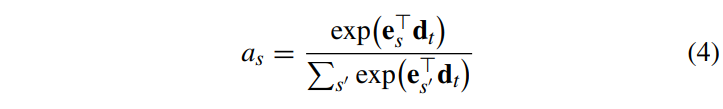
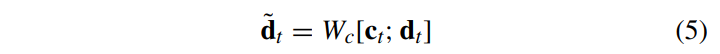
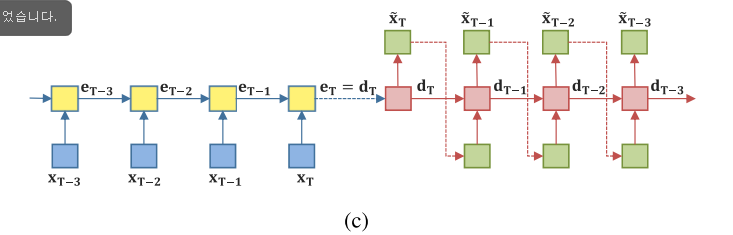
위의 그림 (c)는 RAE 모델이다. RAE는 입력 시퀀스를 단일 컨텍스트 벡터로 인코딩한 다음 컨텍스트 벡터로부터 원래 입력 시퀀스를 재구성한다. 따라서 RAE는 입력 시퀀스의 특징을 추출하거나 원래 입력 시퀀스에서 노이즈를 제거하는데 사용된다.
Proposed RRN Model
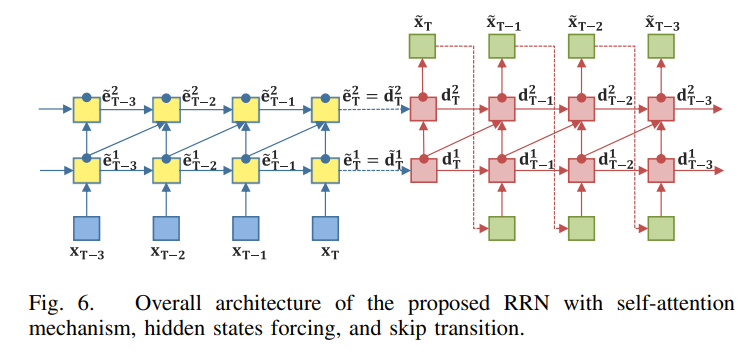
RAE를 베이스로 하고 있는 전체적인 RRN 구조는 다음과 같다. 세가지 기능으로 이루어져있는데 앞서 언급했듯 1) self-attention mechanism; 2)hidden state forcing; 3) skip transition이다.
Self-Attention Mechanism
단일 context vector 가 모든 정보를 포함하는 것은 성능 저하로 이루어질 수 있다. 따라서 attention을 통해 문제를 해결하고자 한다. e_t에서 d_t로 가는 connection에만 attention을 적용한다. Hidden stae encoding 후에 attention을 적용해서 e_T를 구한다. 모델의 complexity가 낮고 input sequence 길이에 상관없이 long-term dependency를 효과적으로 관리할 수 있다.
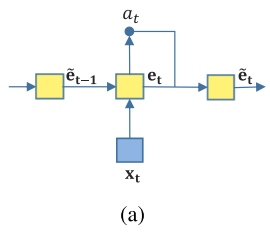
(a)는 attention gate나타낸 그림으로 a_t가 encoding hidden state에 적용되고 e_t는 encoding hidden sateㅇ다.
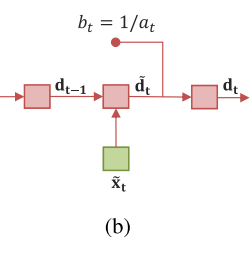
(b)는 Decoding hidden state 나타낸 것으로 d_t는 attention gate의 효과로 얻어진다. attention gate에서의 a_t가 다시 decoding에 사용된다.
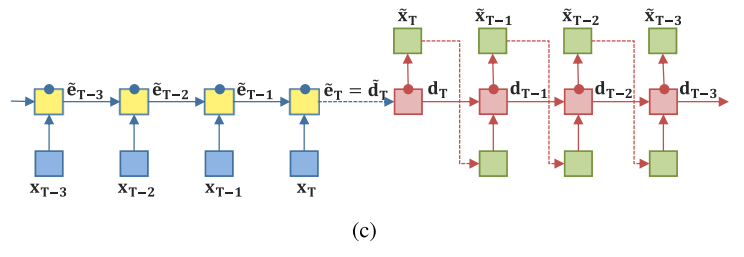
(c)는 RAE에 attention gate가 순차적으로 적용된 것이다.
Hidden State Forcing
Input window 사이즈가 다를 경우 동일 시점의 decoding output 값이 모델 별로 다르다. Input window size에 상관없이 같은 시점의 동일한 output을 갖기 위해서는 해당 시점에 모델별 decoding hidden sate 값이 같아야 한다. 따라서 hidden state forcing 관련 error term을 전체 loss function에 추가하여 window 사이즈에 상관없이 동일한 output을 갖게 해준다.
제안하는 모델은 재구성 오차를 아래 (13)번 식과 같이 설정했다.
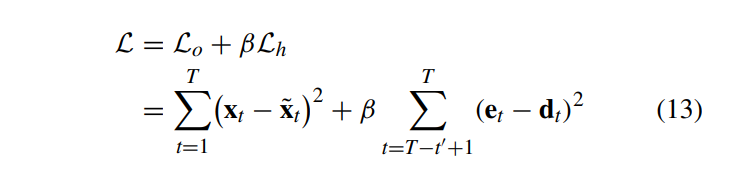
L_0는 reconstruction error function이고 두번째 L_h는 제안하는 hidden state forcing 테크닉이다. 이렇게 하면 output이 window size의 변환에 강건하게 해준다.
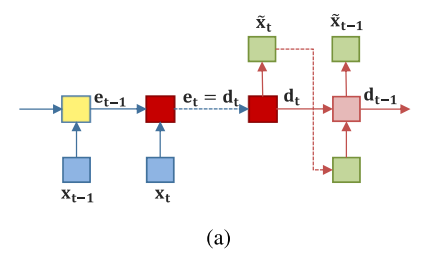
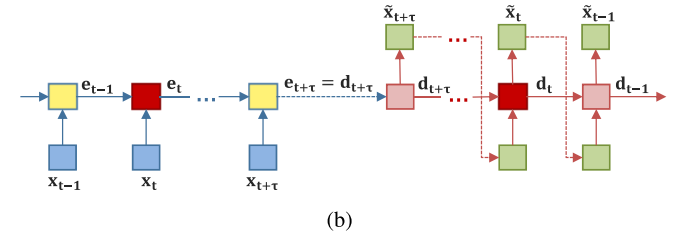
(a)와 (b)를 보면 encoding state와 decoding state를 지나는 노드의 수는 사전에 정의된 window size에 달려있다.
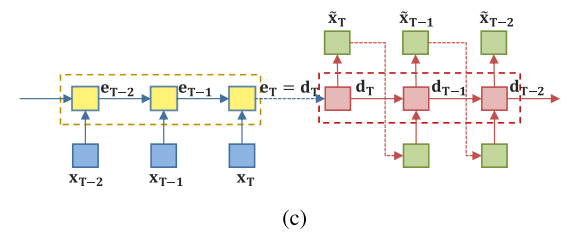
decoding hidden state가 encoding hidden state를 따르도록 강제함으로써 (점선으로 나타나있음) 모델이 사전에 정의된 window 사이즈에 상관없이 일정한 output을 생성할 수 있다.
Skip Transition with Attention Gate
Sequential data의 복잡한 패턴을 모델링하기 위해 RNN은 다양한 구조를 가진다. Feedback transition과 skip transition이 있다.
1) Feedback Transition : upper layer에서 lower layer로 가는 우회로로 input과 output 사이 경로가 길어진다.
2) Skip Transition : lower layer에서 upper layer로 가는 recurrent connection으로 input과 output 사이 경로가 짧아진다.
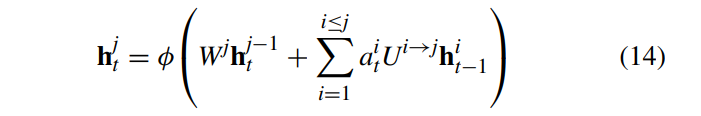
수식은 위와 같다.
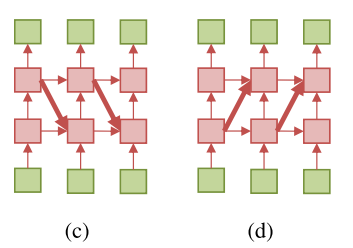
(c)는 feedback transition이고 (d)는 skip transition이다.
Sequential Anomaly Detection
Anomaly detection 프로세스는 다음과 같이 세가지 phases로 구성된다. 1) Training 2) Validation 3) test
Training과 Validation dataset은 normal로만 구성되어 있고 Test dataset은 normal과 abnormal이 섞여있다.
훈련단계에서 RRN은 정상 데이터의 기본 구성 요소를 추출한 다음 구성 요소에서 정상 데이터를 재구성하도록 훈련된다.
테스트 단계에서 anomaly probability는 다음 식과 같이 정의된다.
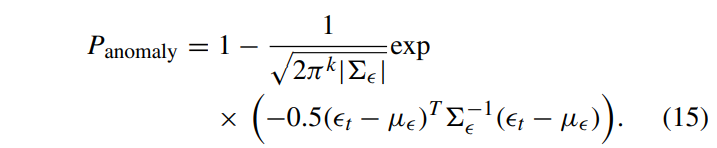
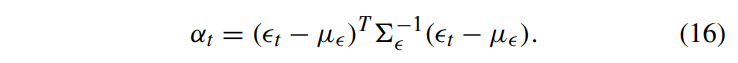
위의 a_t는 anomaly score이다.
Experiment
사용된 데이터셋은 아래와 같다.


Experimental Results
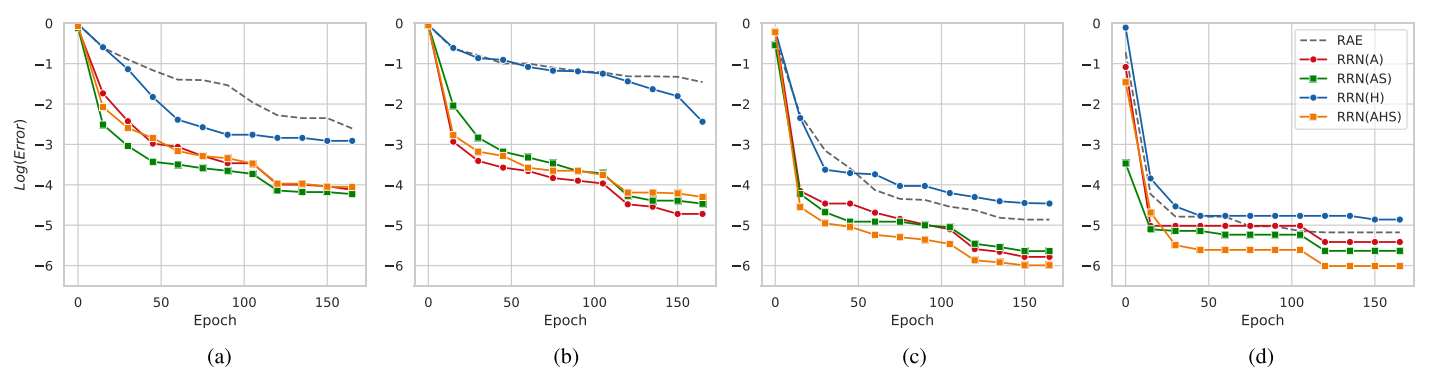
위의 그림을 보면 RRN 계열들이 RAE보다 수렴속도가 빠르다는 것을 알 수 있다. Attention gate의 효과가 모델이 짧은 시간 내에 validation error를 줄이는 데 큰 도움이 되었다.
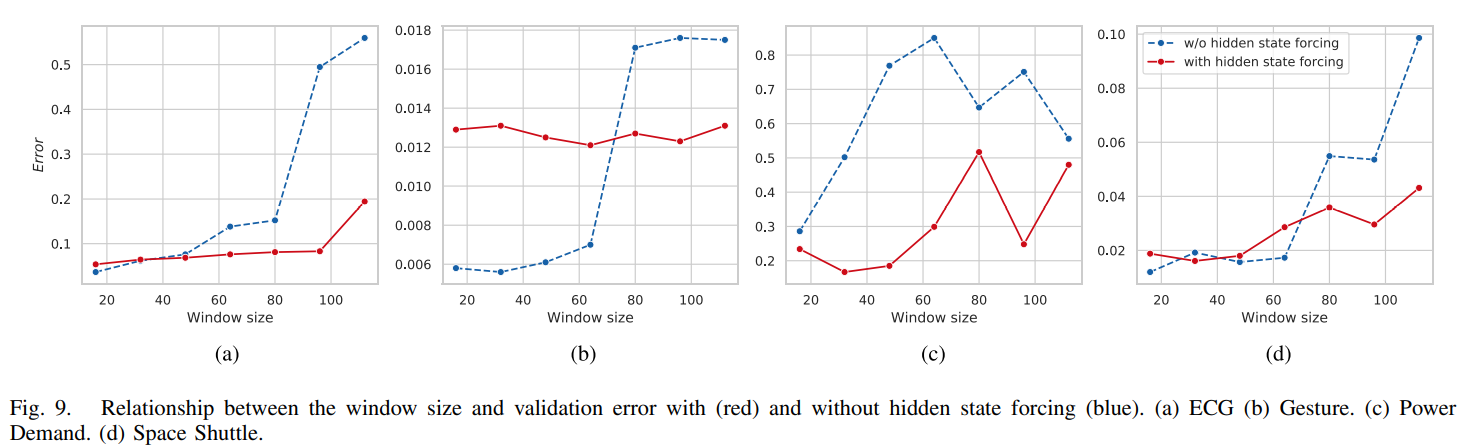
그림 9는 window size에 따른 validation error를 보여준다. Hidden state forcing 기술을 통해 모델이 인코딩 부분의 정보를 디코딩 부분의 hidden state로 잘 전달할 수 있다. 따라서 창 크기의 변화에 대해 모델이 견고해진다.
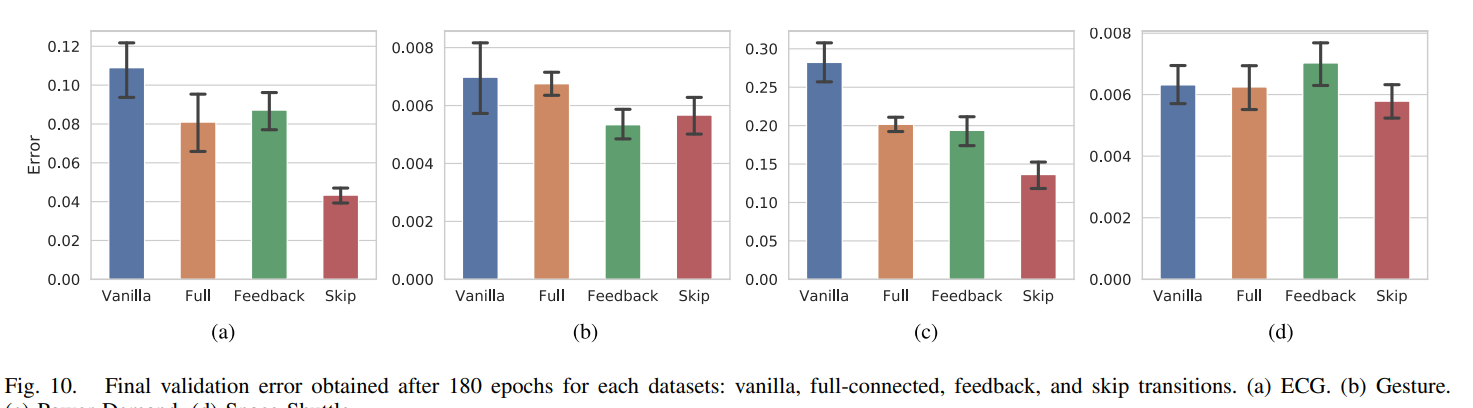
그림 10에는 그림 5에 나타난 4종류의 recurrent connection과 최종 검증 오류의 관계가 나타나 있다. 그림 10에서 막대의 높이는 모델별로 10회 실험한 검증오차의 평균을 나타내고 선의 길이는 모델별 검증오차의 95% 신뢰구간을 나타낸다. Shortcut path가 소스와 출력 시퀀스 간에 정보를 효율적으로 전송하므로 shortcut path를 추가하면 모델이 출력 시퀀스를 정확하게 생성할 수 있다.
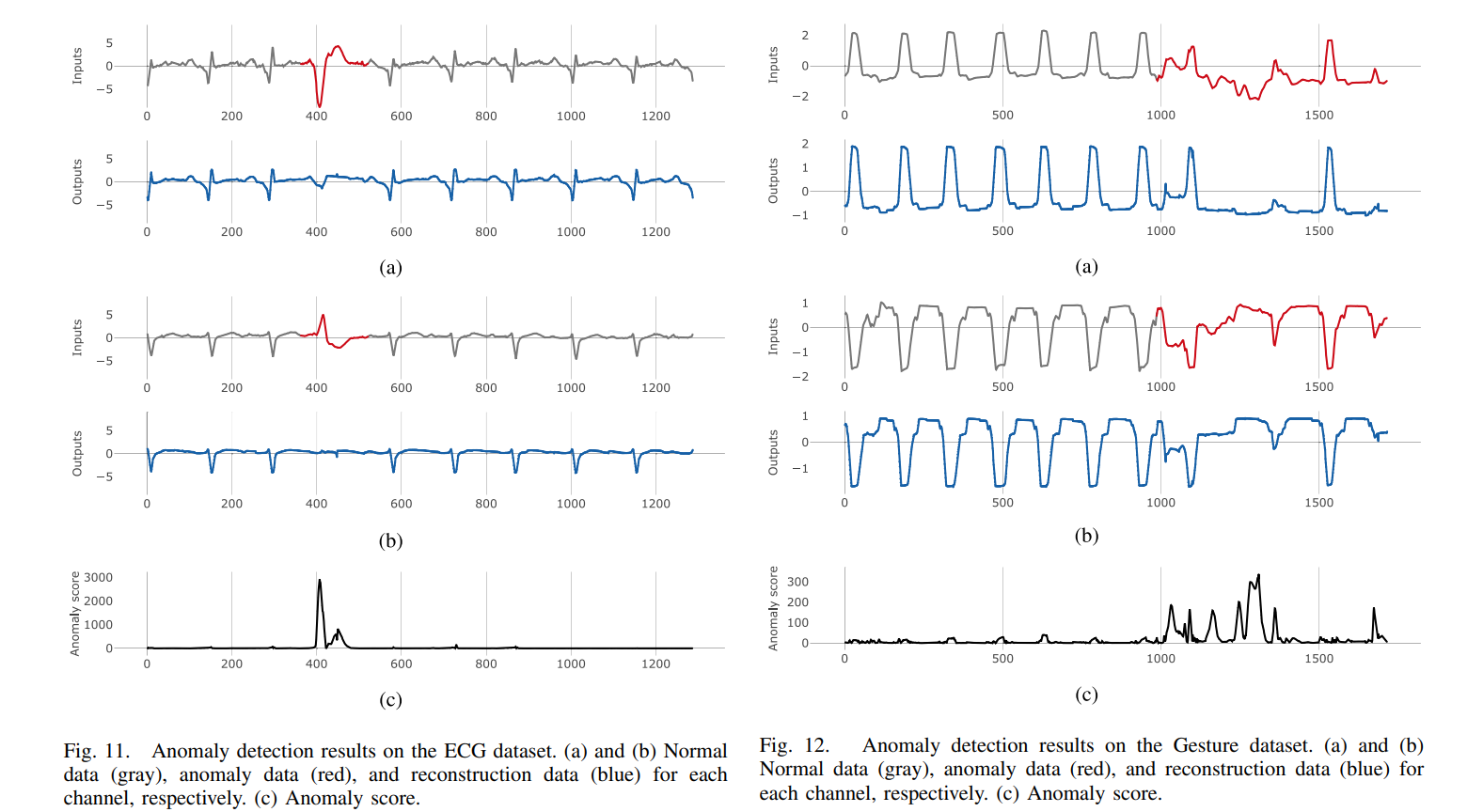
그림을 보면 (a)에서 회색은 정상 빨간색은 비정상을 나타낸다. 그리고 (c)는 anomaly score이다.
Conclusion
RRN은 decoder의 hidden state를 encoder의 hidden state와 연결하는 self-attention mechanism을 가진다. 또한 hidden state forcing 기법을 사용하여 window size와 더 긴 sequence의 변화에 robust하도록 하였다. 추가적으로 skip transition을 사용하여 input에서 output까지의 거리를 줄였다. RRN은 window size에 강건하고 복잡한 데이터도 잘 다룰 수 있으며 훈련 시간 또한 줄인 모델이라고 할 수 있다.