Recurrent Neural Networks
one to many는 예를들어 개가 뭔가를 먹고 있는 이미지가 들어왔을 때 아웃풋으로 A dog eats something이라는 문장을 출력해내고 싶을때. (Image -> sequence of words)각 단어를 특정 벡터로 코딩한 다음에 벡터들을 Output으로 만든다.
input이 sequence모양일 수 있음. 이를 테면 video가 인풋. 비디오는 시간적으로 dependency있자넝. (Sequence of images->label) 하나의 아웃풋 예측
many to many는 input도 sequence이고 output도 sequence. 예를 들어 한국어 문장을 영어로 번역.
또 input이 들어오자마자 아웃풋이 나오는 방식도 있음.
Vanilla RNN
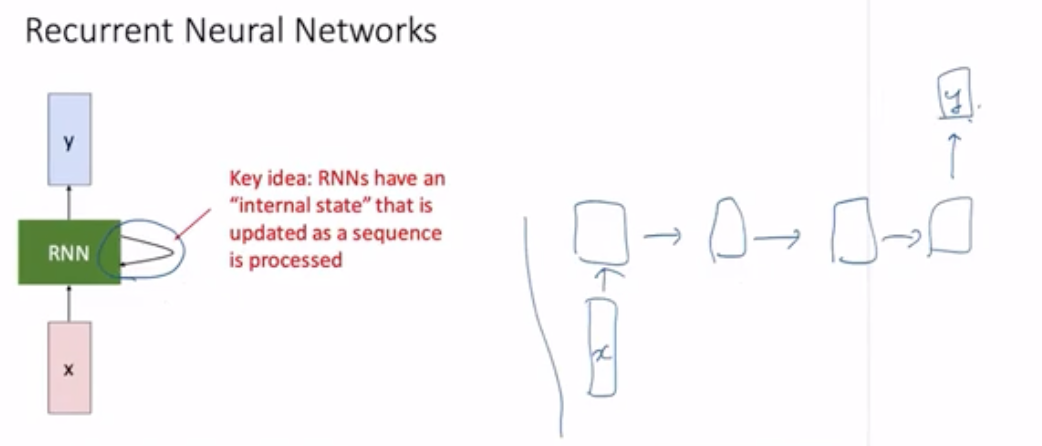
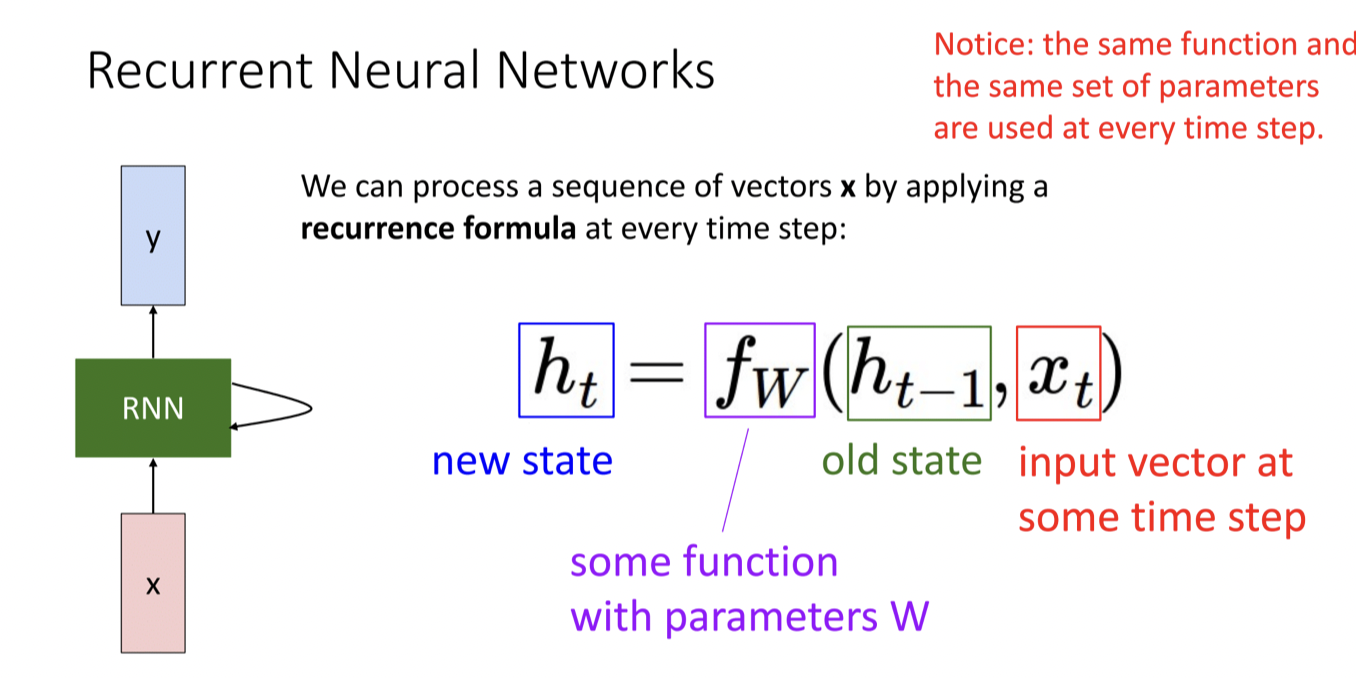
같은 트렌드가 재귀적으로 (recurrent) 적용된다. CNN에서는 hidden layer라는 말을 많이 쓰는데 RNN에서는 state 라는 말을 많이 사용. 이전 시각의 hidden variable은 old state, 새로운 hidden variable은 new state라고 함

fw 함수를 보면 위의 그림과 같다. learnable weight는 (Whh,Wxh,bias)의 세트임. Whh는 hidden variable을 hidden variable로 transform하는 W란 매트릭스. Wxh은 input을 hidden으로 바꿔주는 matrix
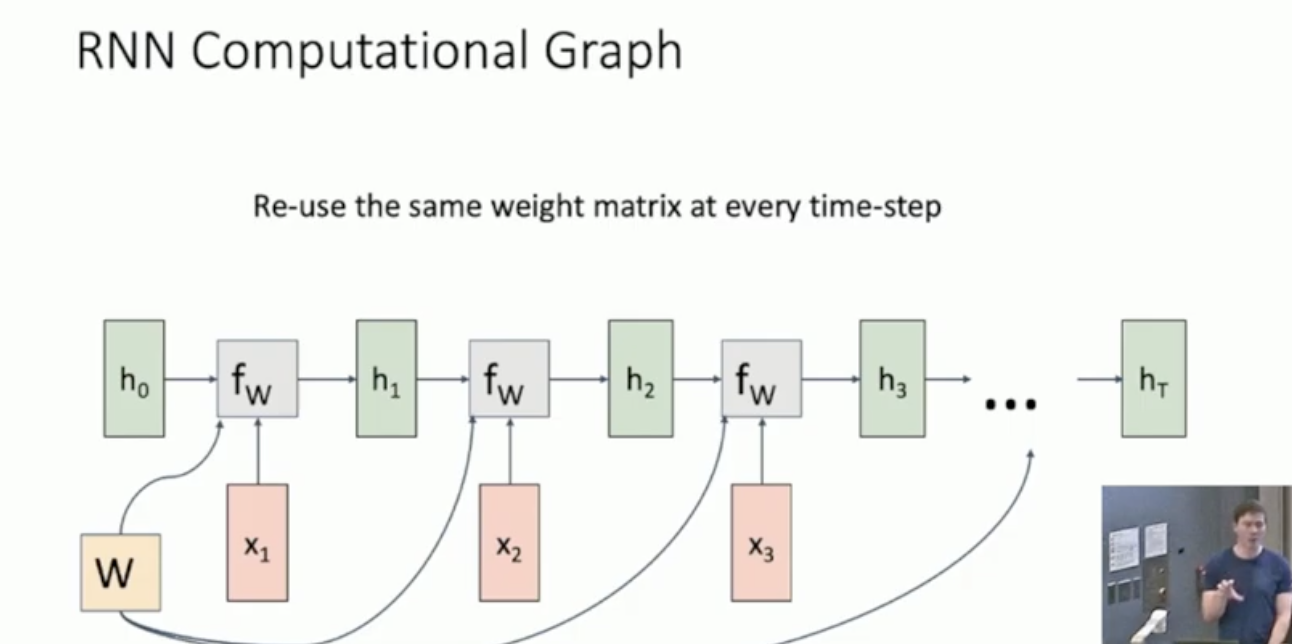
먼저 h0은 모두 0으로 initialize한다. 그리고 W는 length가 어떻든 모든 step마다 same하게 적용한다.
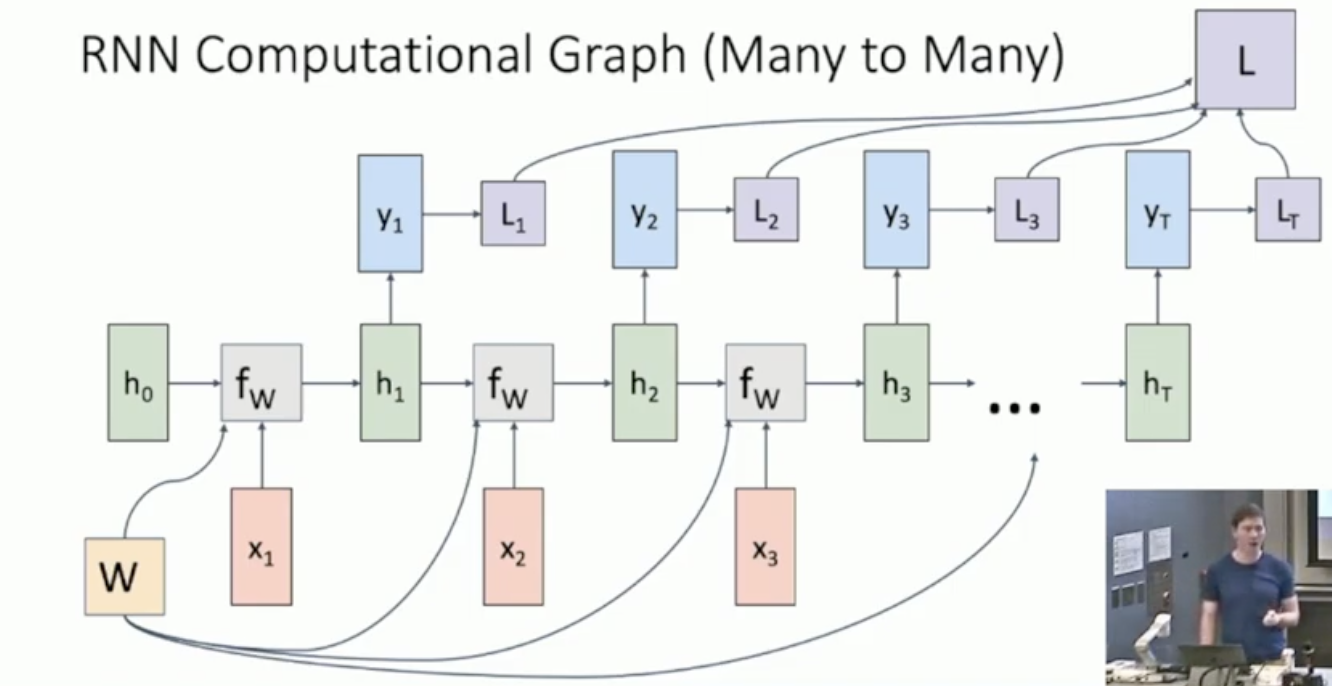
위의 그림은 Loss를 step마다 구하고 final에서 모두 더해준다. 그게 L. 위의 그림은 many to many 상황에서 computational graph임.
Sequence to Sequence (seq2seq)
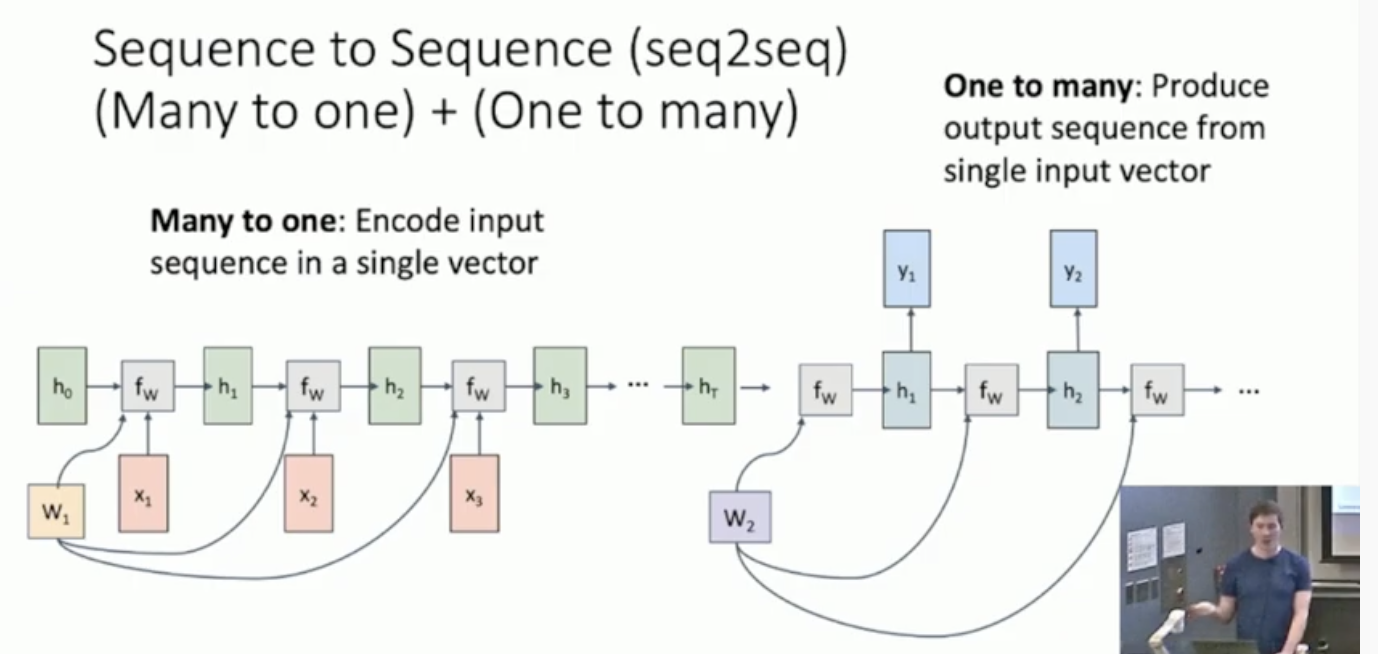
위의 모델은 보통 번역할때 사용한다. 이거는 basically taking a many-to-one recurrent neural network and feeding it deirectly into another one-to-many recurrent neural network. 근데 왜이렇게 나눠서 하냐? 왜냐면 number of input token이 number of output token과 다를 수 있기 때문에.

먼저 input layer는 one-hot encoding을 해준다. 그다음에는 아래 그림과 같이 계산된다.
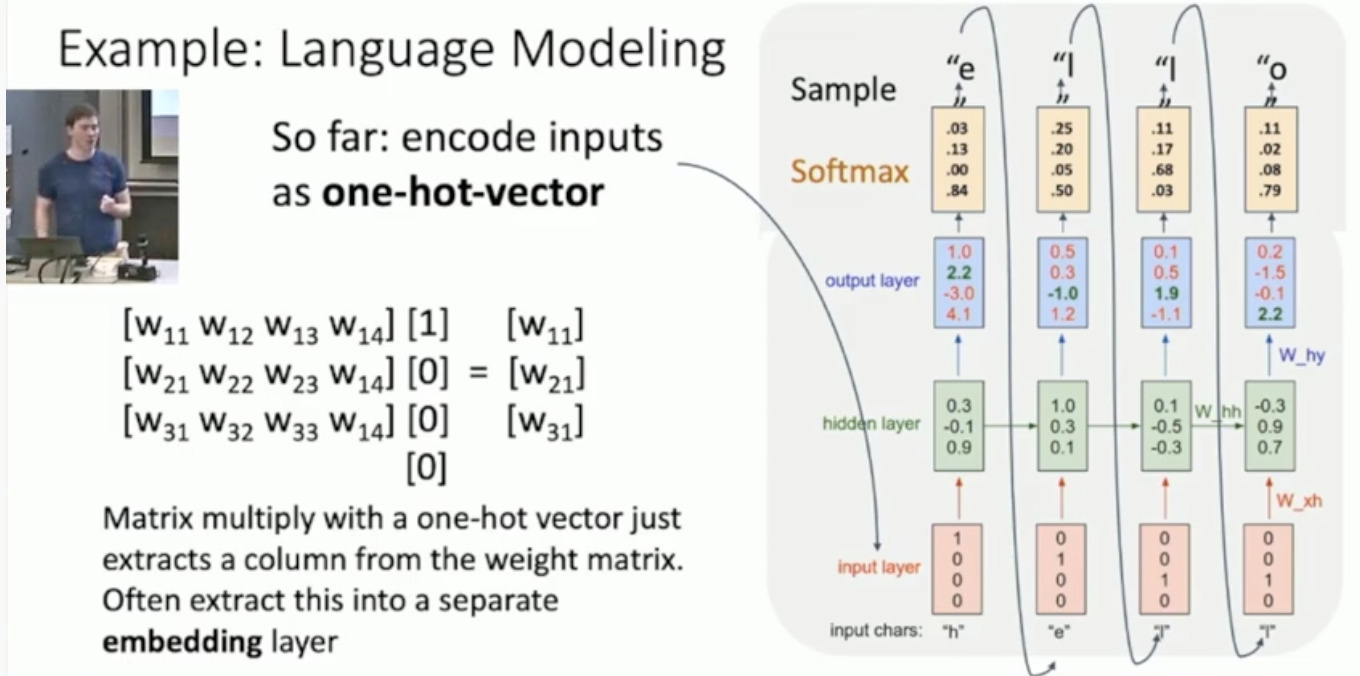
- “h” 입력 —> “e”를 출력하도록 학습
- “h”, “e”를 입력 —> “l”을 출력하도록 학습
- “h”, “e”, “l”을 입력 —> “l”을 출력하도록 학습
- “h”, “e”, “l”, “l”을 입력 —> “o”를 출력하도록 학습
그런데 hidden state 계산에서 입력 (one-hot vector)이 가중치 행렬 W와 곱해지는 경우를 생각해보면 이 곱셈 연산ㅇ느 아주 sparse하다. 위의 슬라이드에서 알 수 있듯이, W에서 한개의 column만을 추출하면 되기 때문에 단순히 열을 추출하는 방식으로 구현하는 것이 더 효율적이다. 이러한 이유로 일반적으로 아래 그림과 같이 입력과 RNN사이에 Embedding layer(노란색 박스)라는 것을 추가해준다.
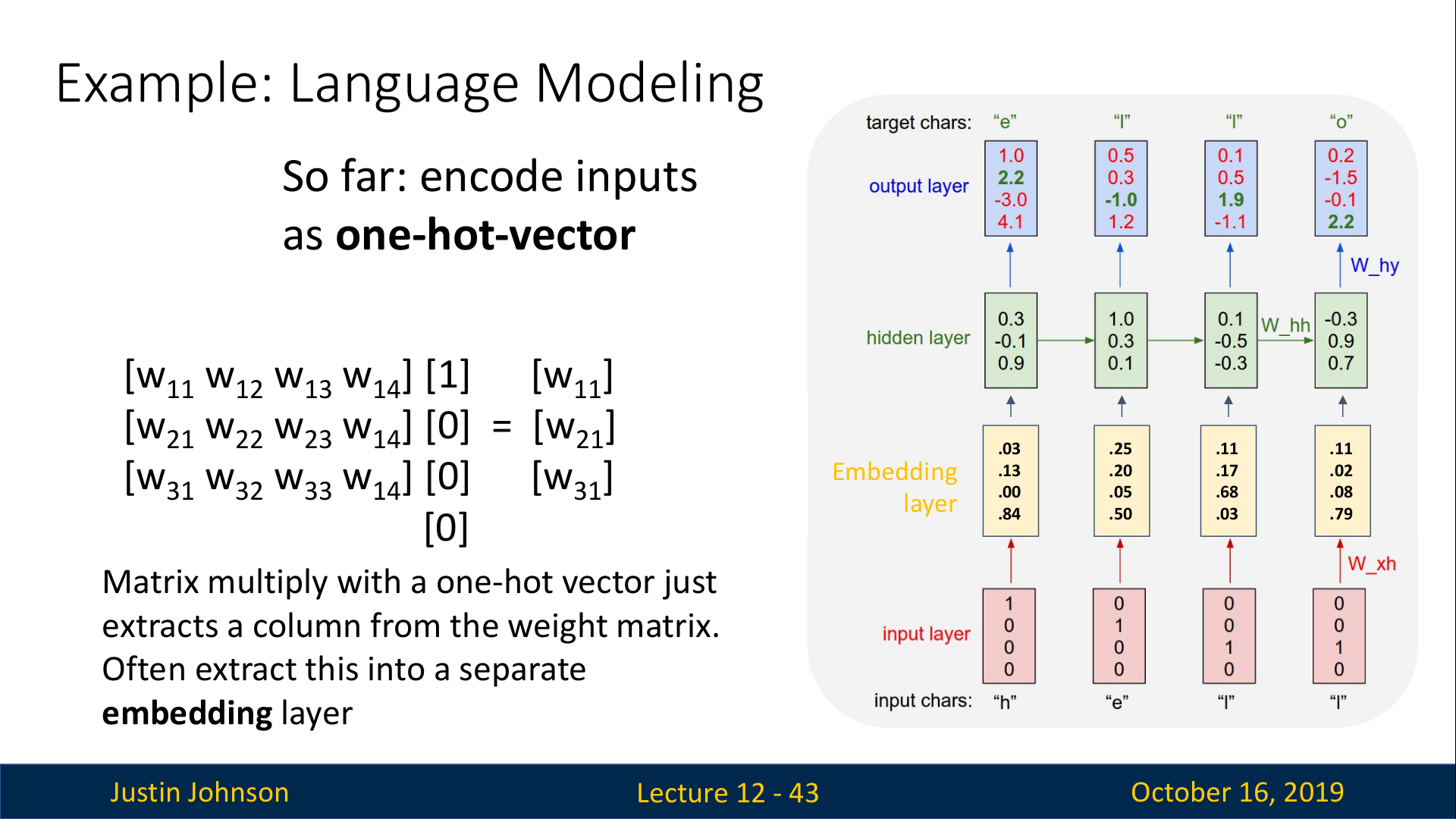
Embedding layer는 one-hot vector가 W의 어떤 column에 해당하는지를 학습하게 된다. 이는 단어를 sparse한 one-hot vector가 아닌 dense vector로 만들어주어 저차원에서 더 많은 단어를 표현할 수 있게 된다.
Backpropagation
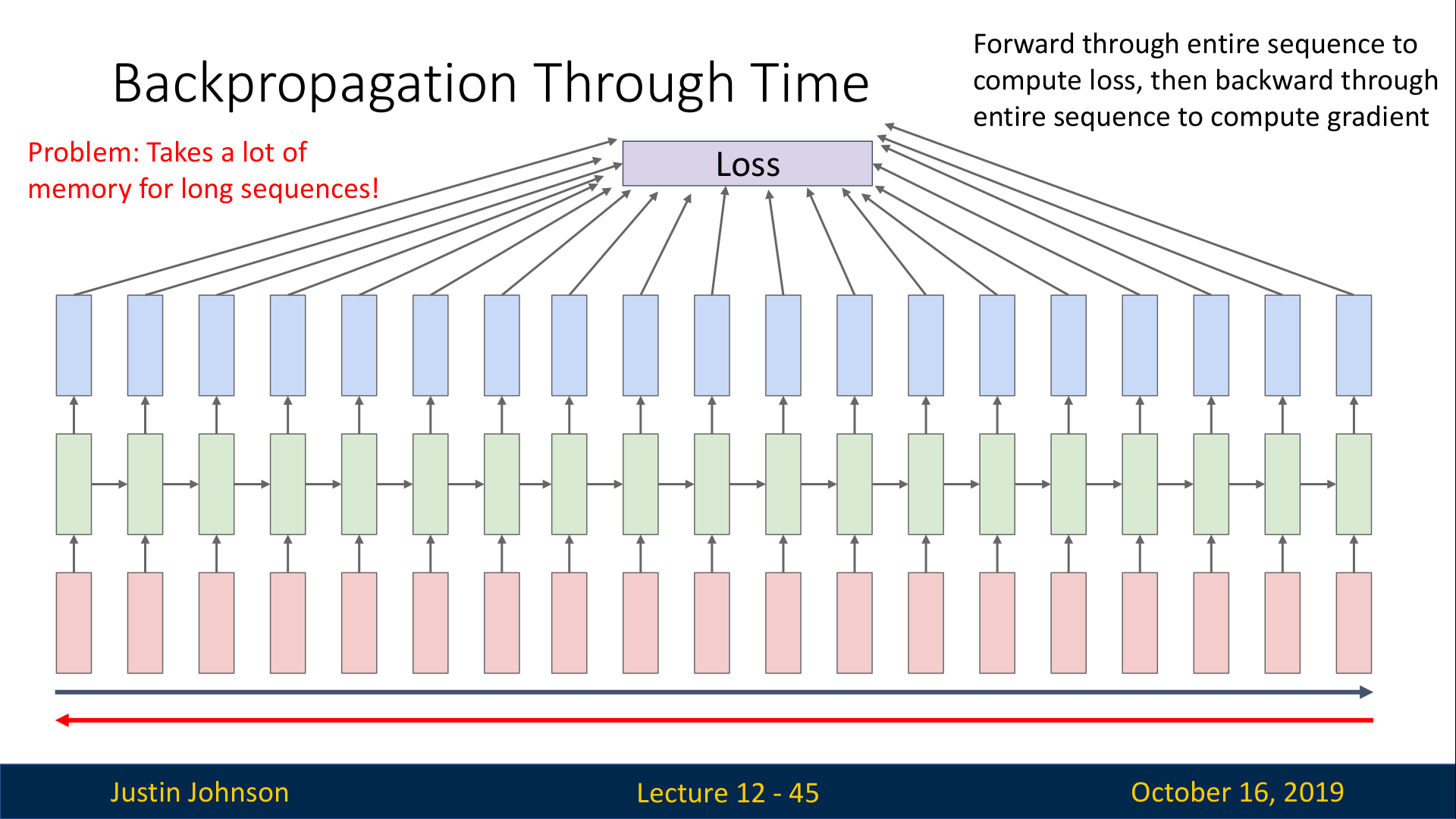
RNN에서의 역전파는 위 슬라이드와 같이 아주 긴 시퀀스를 학습하려고 할 때, 엄청난 양의 메모리가 필요하다는 문제가 있다.
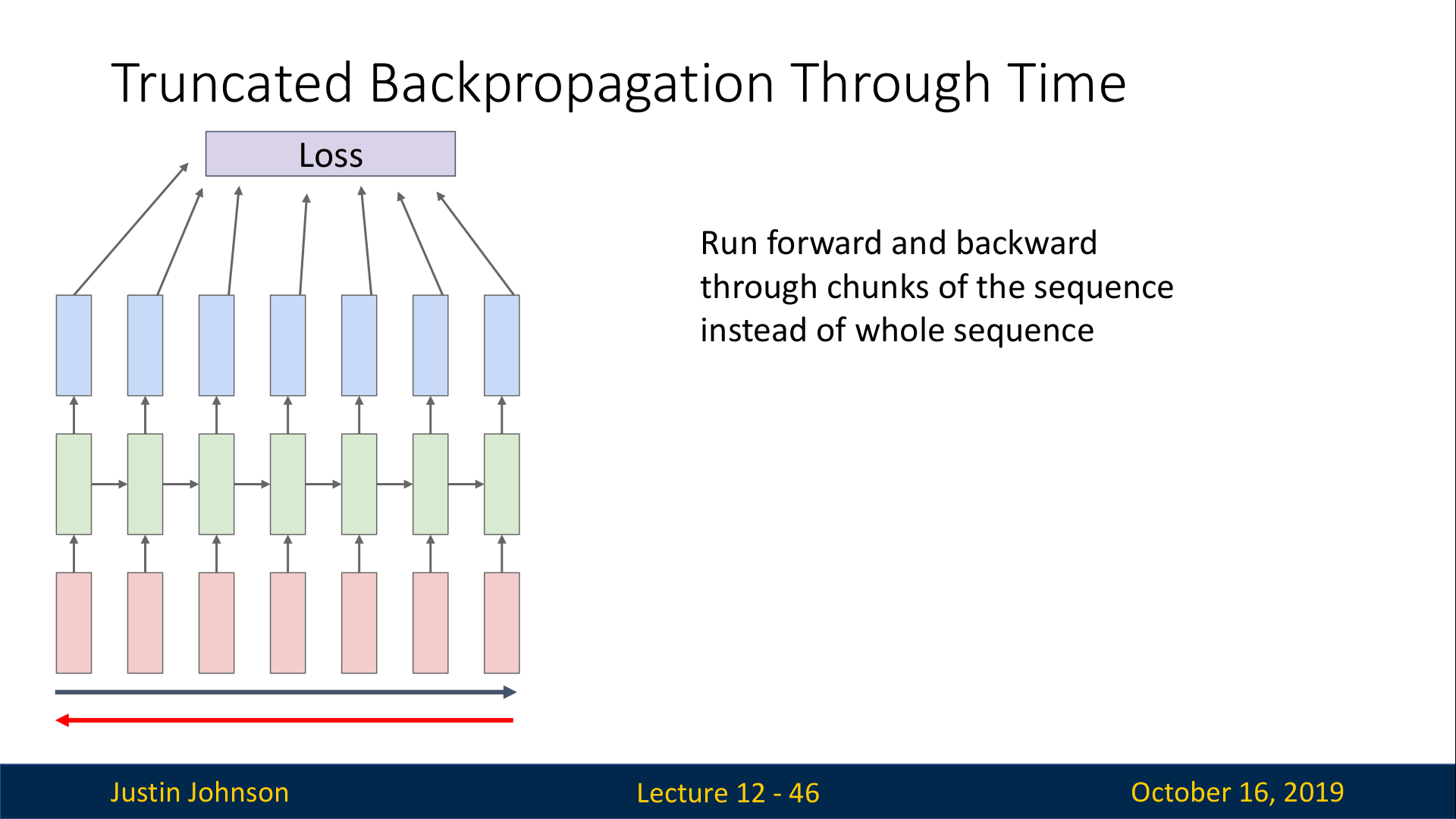
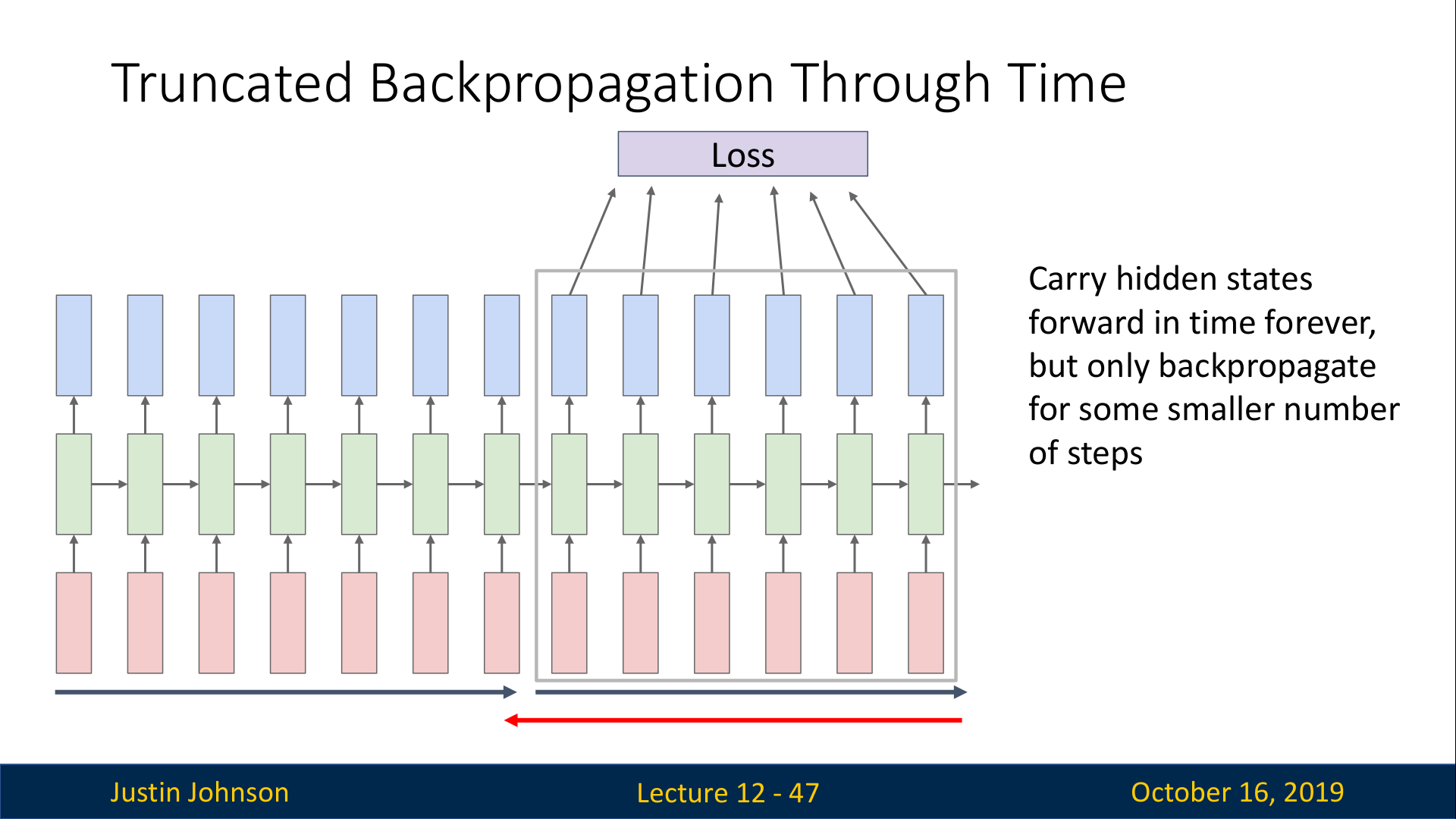
따라서, 아주 긴 시퀀스를 RNN으로 처리하는 경우에는 대체 근사 알고리즘(alternative approxtimate algorithm)을 사용한다.
이는 전체 시퀀스를 나누어서 학습하는 방법으로, 다음과 같이 동작한다.(위의 두 슬라이드 참고)
1번째 chunk의 시퀀스에서 모든 hidden state를 계산해 loss를 구하고, 1번째 chunk의 시퀀스에 대해서만 backprop을 통해 W를 학습시킨다.그리고 1번째 chunk의 마지막 hidden state 값을 기록해뒀다가 2번째 chunk로 전달한다.
hidden state값을 전달받은 2번째 chunk는, 다시 2번째 chunk의 시퀀스에 대해서 모든 hidden state와 loss를 계산하고 2번째 chunk의 시퀀스에 대해서만 backprop을 수행한다.
그리고 2번째 chunk의 마지막 hidden state 값을 기록해뒀다가 3번째 chunk로 전달한다.
이러한 과정을 끝까지 반복해서 수행한다.
위와 같이, 각 chunk에 대해서만 backprop을 수행하면서 학습하기 때문에 이 방법을 Truncated Backpropagation이라고 부르며, 각 chunk에 대한 정보만 저장하면 되므로 한정된 자원의 GPU에서도 학습을 수행할 수 있게 된다.
Image Captioning
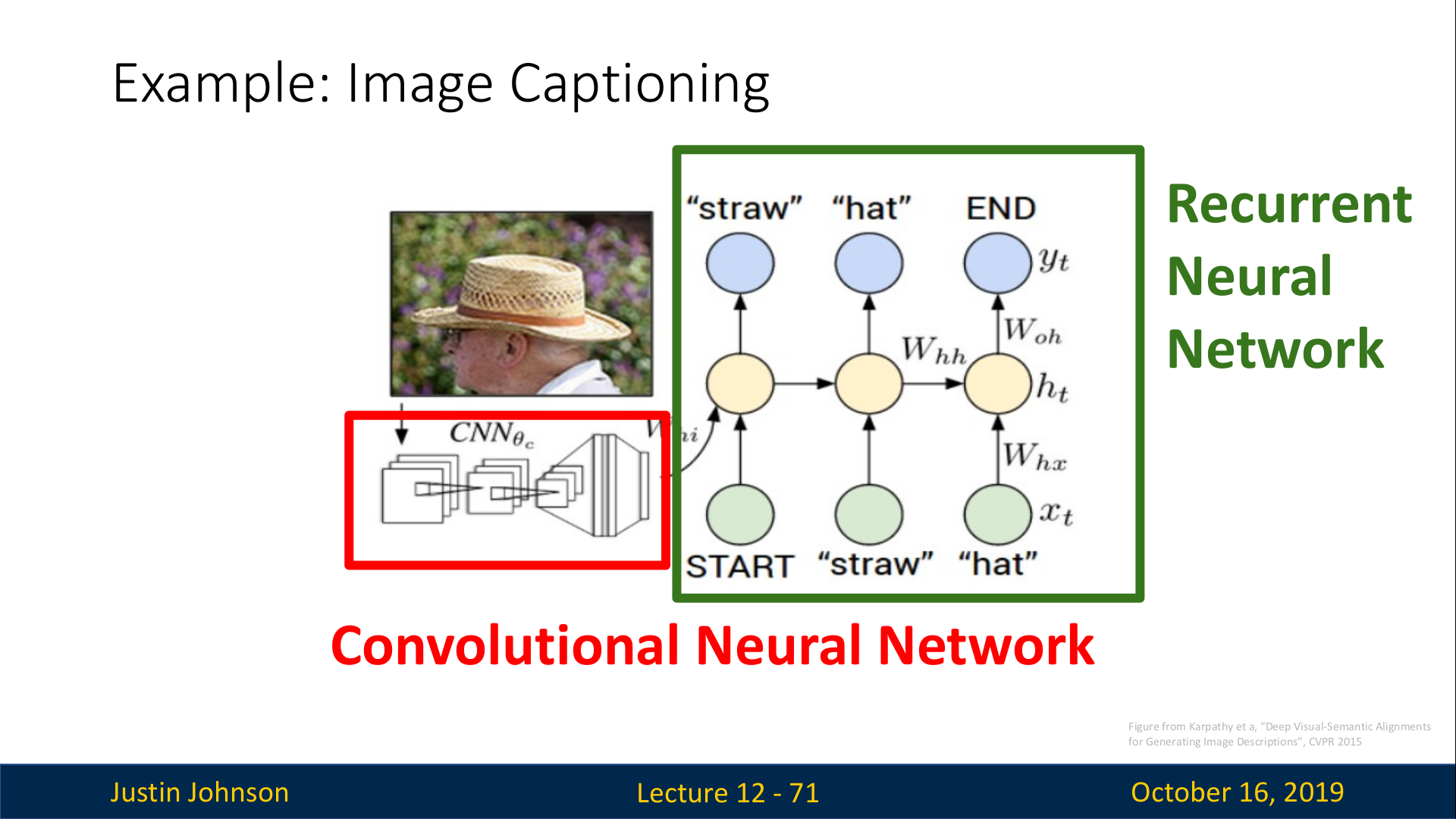
RNN Language Model을 컴퓨터 비전에 적용한 예로는 Image Captioning이 있다. 동작 방법은 다음과 같다. CNN에 이미지를 입력으로 넣어서 feature를 추출한다. 추출한 feature를 RNN Language Model에 입력으로 넣어서 이미지를 설명하는 단어를 하나씩 생성하도록 한다.

먼저 Pre-trained CNN에서 마지막 layer를 제거한다.
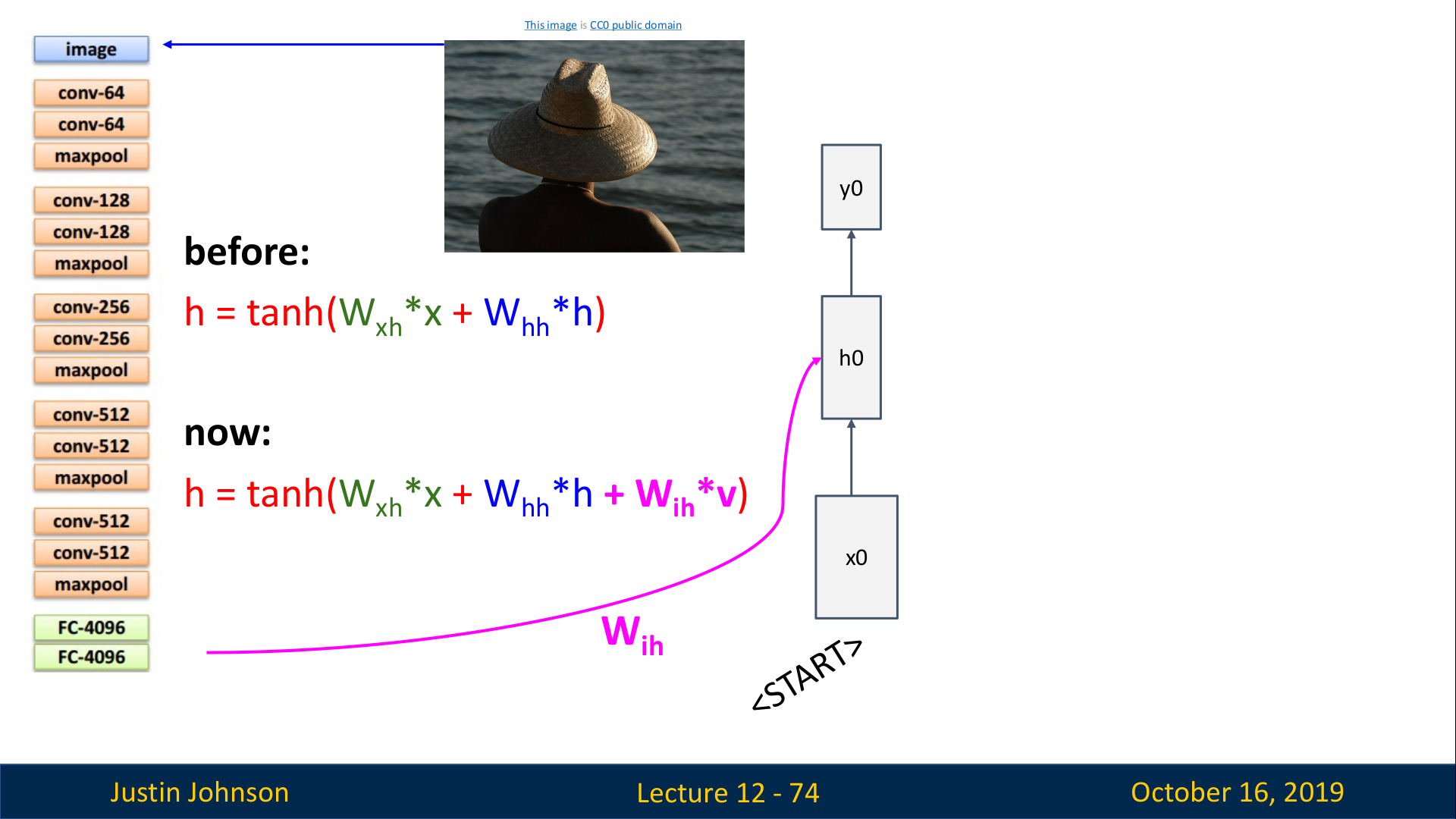
그리고 CNN을 RNN과 연결하기 위해서, recurrent formula(RNN에서 hidden state를 생성하는데 사용한 함수식)을 약간 수정한다.
CNN의 출력으로 나온 feature vector와 곱해지는 가중치 행렬
Wih가 추가됨 (위 슬라이드의 now 식에 추가된 핑크색 W)
즉, 수정된 RNN은 다음의 3가지 input에서 가중치 합을 모두 더하고 tanh로 출력하게 된다.
Wxh : 입력 x와 곱해지는 W
Whh: t−1에서의 hidden state와 곱해지는 W
Wih: CNN의 출력으로 나온 feature vector와 곱해지는 W
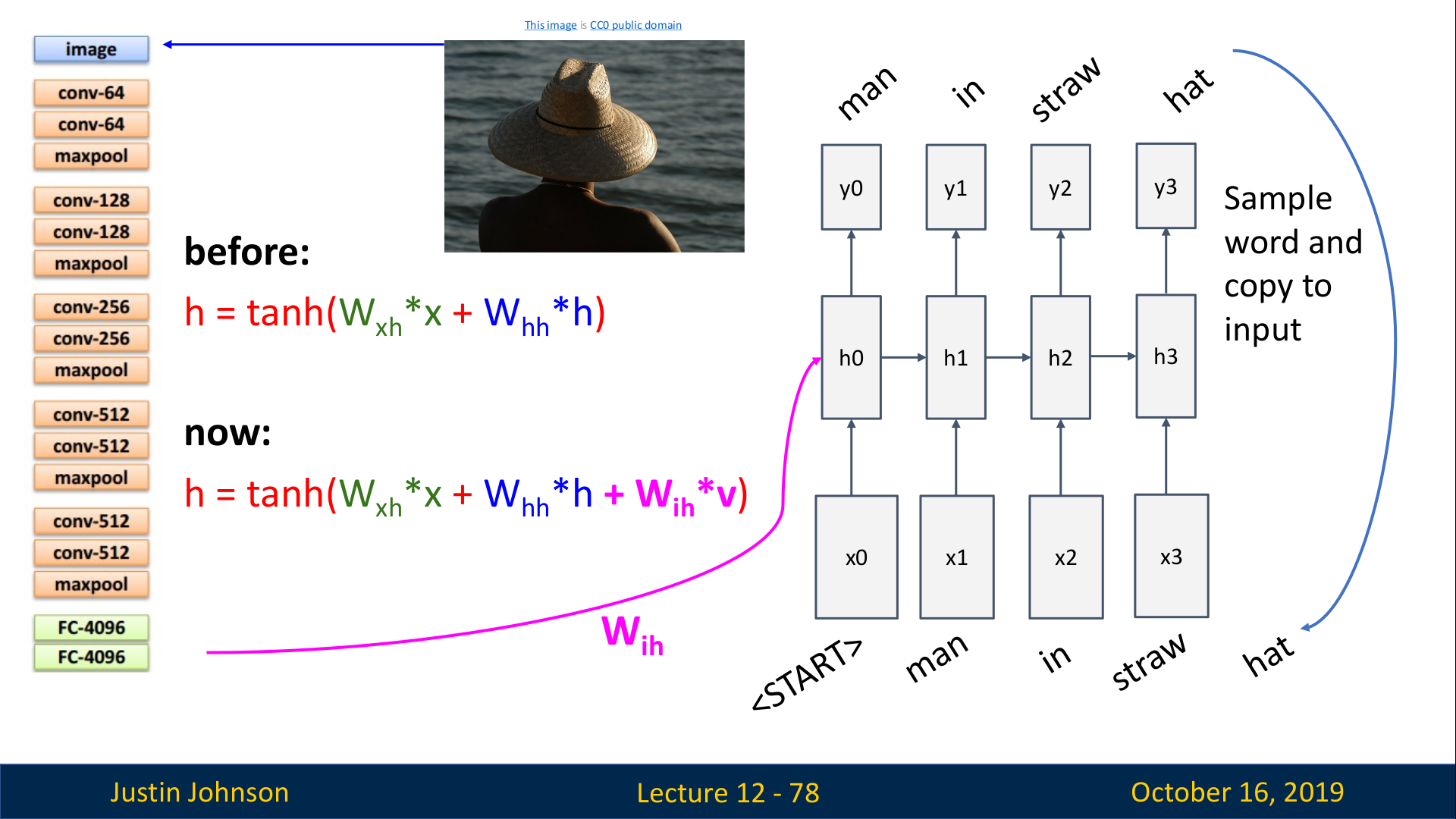
이때,
그런데 image captioning 모델은 컴퓨터비전 taks를 해결하기에는 살짝 무리임.
Vanilla RNN Gradient Flow
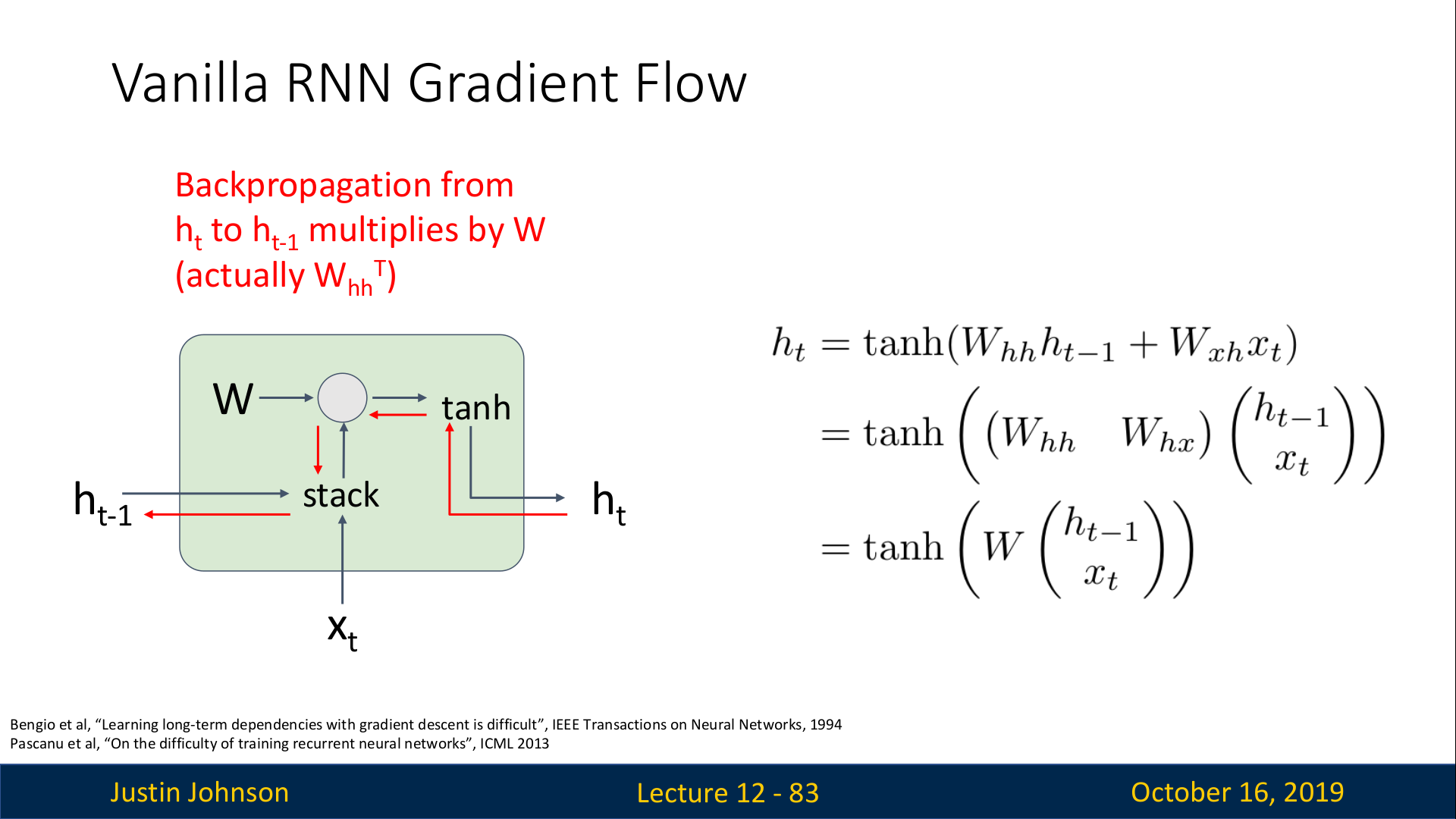
Vanilla RNN에서 ht−1에서의 gradient를 구하기 위해서는 ht
에 대한 loss의 미분을 계산해서 gradient를 back prop 해야 한다.
그런데, 이 back prop에는 다음과 같은 2가지 문제점이 있다.
- tanh 함수가 좋지않다. (하지만, 이 모델은 90년대에 나왔기 때문에 큰 문제가 아님)
- 행렬의 곱셈에서 back prop을 수행할 때, 동일한 matrix의 transpose를 계속해서 곱하게 된다. (다음 슬라이드에서 자세히 설명함)
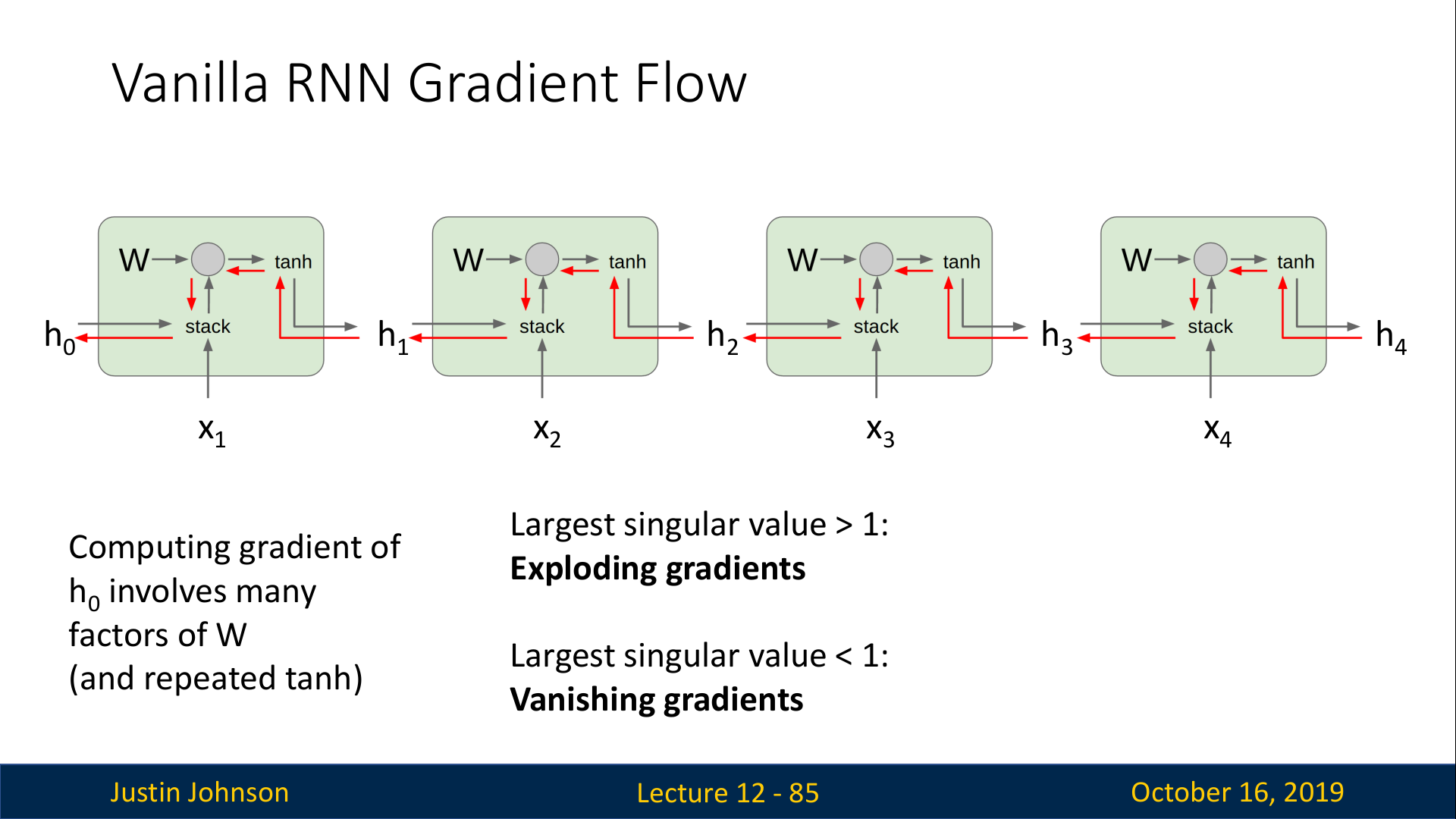
위의 슬라이드와 같이 여러개의 cell이 연결된 구조에서, upstream gradient는 cell을 넘어가는 매 순간마다 동일한 가중치 행렬 W와 곱해지게 된다. 이는 backprop중에 계속해서 동일한 가중치 행렬 W의 transpose를 graident에 곲하게 되는 결과로 이어지며, 이는 2가지 안좋은 결과를 초래한다.
- Exploding gradients (singular value >1)
- Vanishing gradients (singular value <1)
따라서 W의 singular value =1인 경우에만 정상적으로 학습이 이루어지므로, 아예 제대로 이루어지지 않는다고 볼 수 있다.
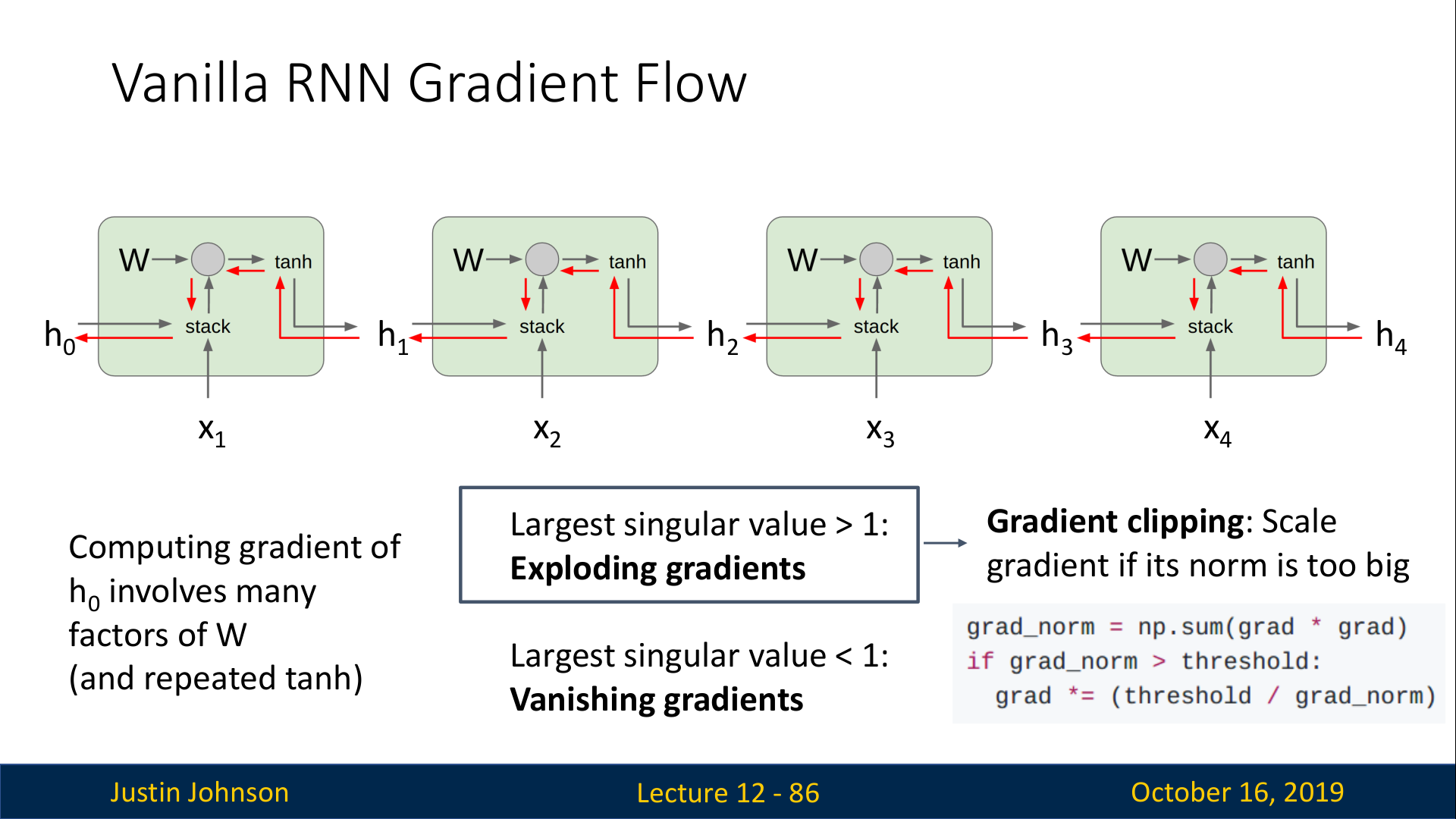
Exploding gradient의 경우에는 clipping을 수행할수도 있지만, 이는 실제 gradient가 아니므로 여전히 문제이다. (강의에서 clipping은 horrible dirty hack라고까지 이야기함…)
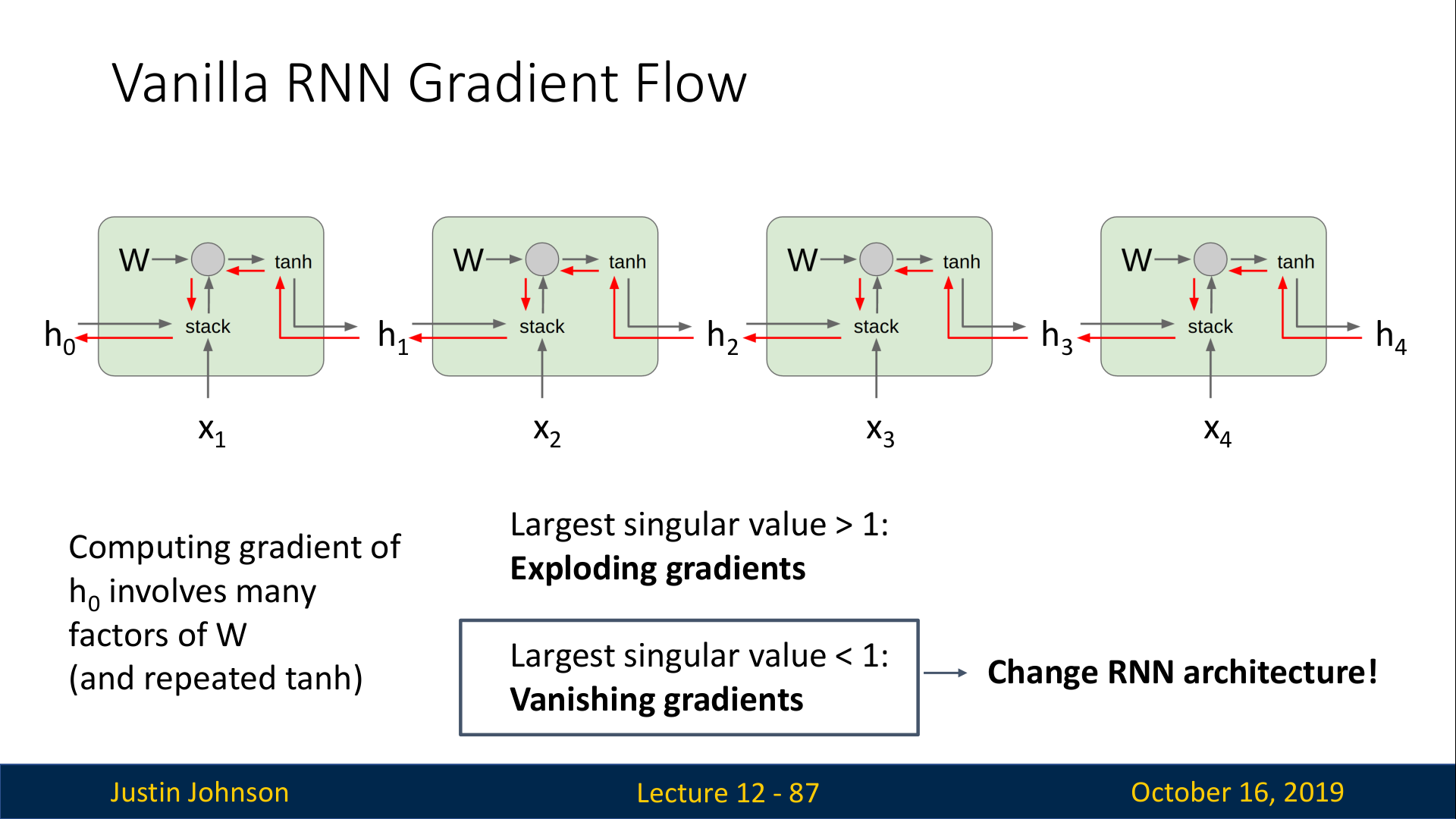
Vanishing gradient 문제에서는 clipping과 같이 heuristic한 방법이 따로 없기 때문에, 신경망 자체를 바꾸는 것이 일반적이다.
LSTM
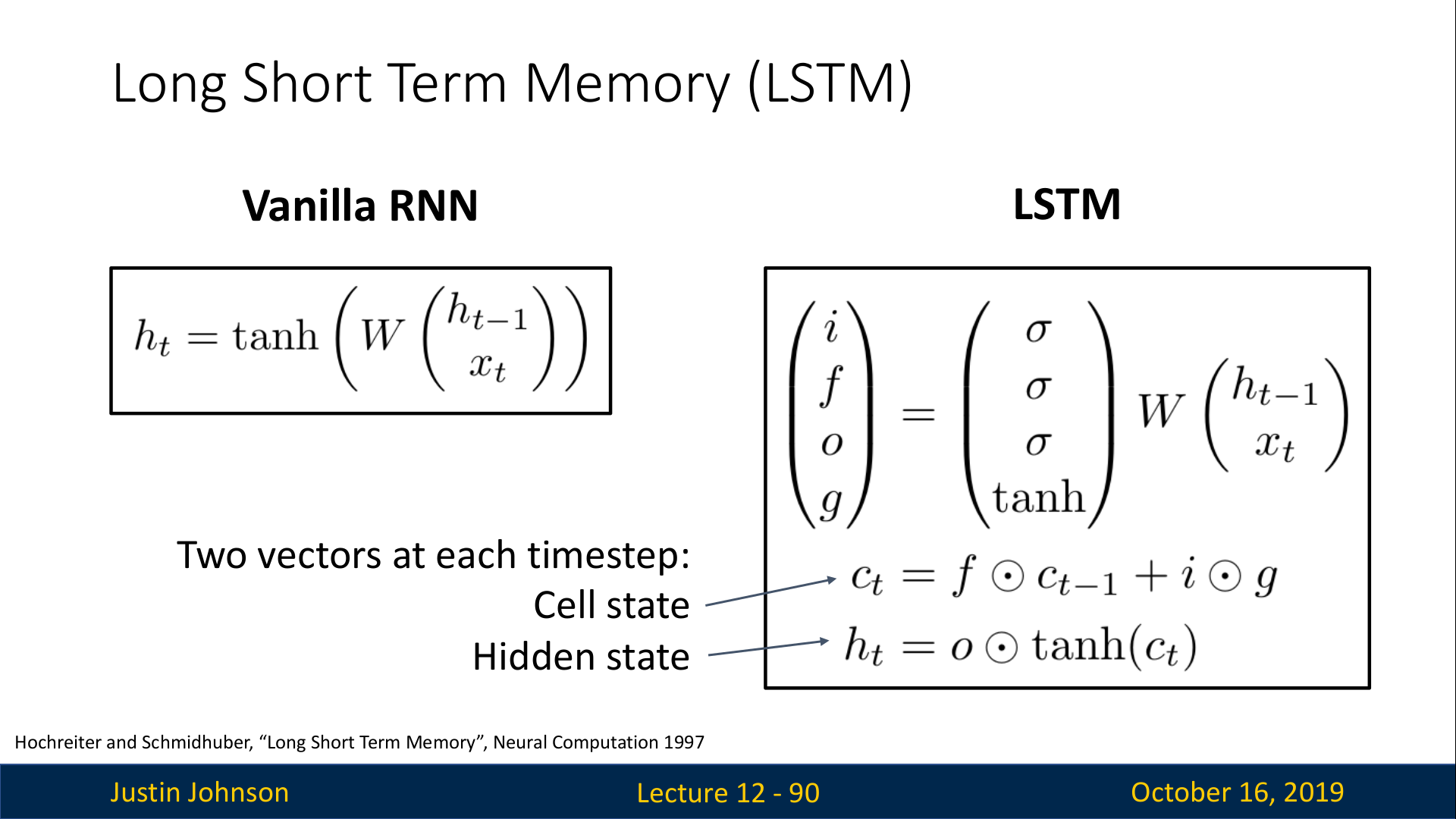
RNN에서의 Vanishing gradient 문제를 해결한 모델은 LSTM이다.
LSTM은 매 time step마다 1개의 state를 유지하는 것 대신에 2개의 state를 유지한다.
- C_t : Cell state
- h_t : hidden state
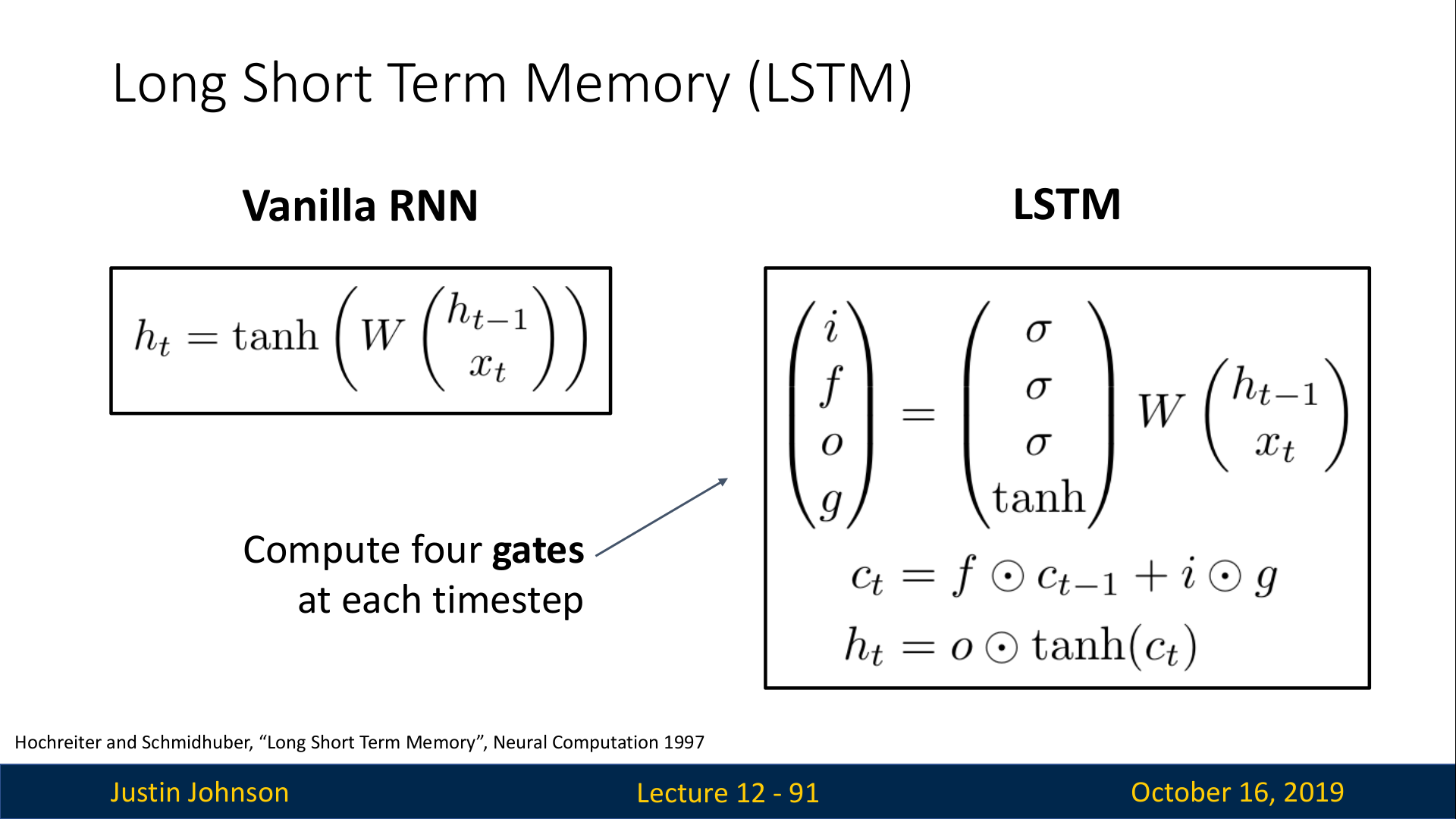
또한, 현재 입력 x_t와 과거 hidden state h_t−1을 사용해 4개의 gate value i,f,o,g 를 계산한다. 이 4가지 value는 c_t와 h_t를 계산하는데 사용된다.
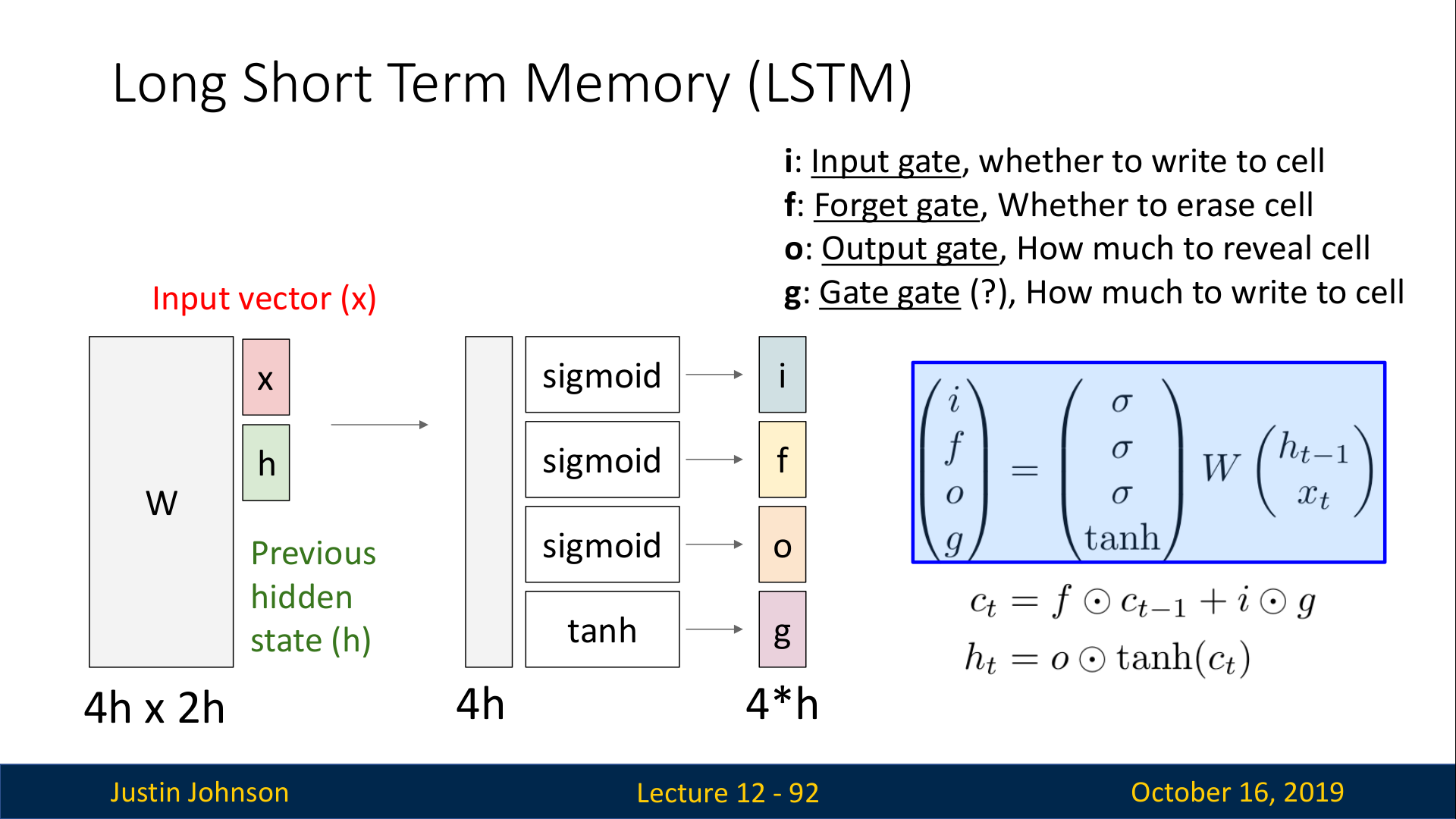
Vanilla RNN에서는 x_t와 h_t-1을 W와 곱한 결과가 tanh()를 거쳐서 바로 h_t가 되는 구조였다. 하지만 LSTM은 x_t와 h_t-1을 W와 곱한 결과를 총 4개의 gate i,f,o,g로 출력한다. 이때 각각의 gate는 다음의 activation function을 통해 출련한다.
i: Input gate / sigmoid() —> 0∼1
f: Forget gate / sigmoid() —> 0∼1
o: Output gate / sigmoid() —> 0∼1
g: Gate gate / / tanh() —> −1∼1

Gradient Flow
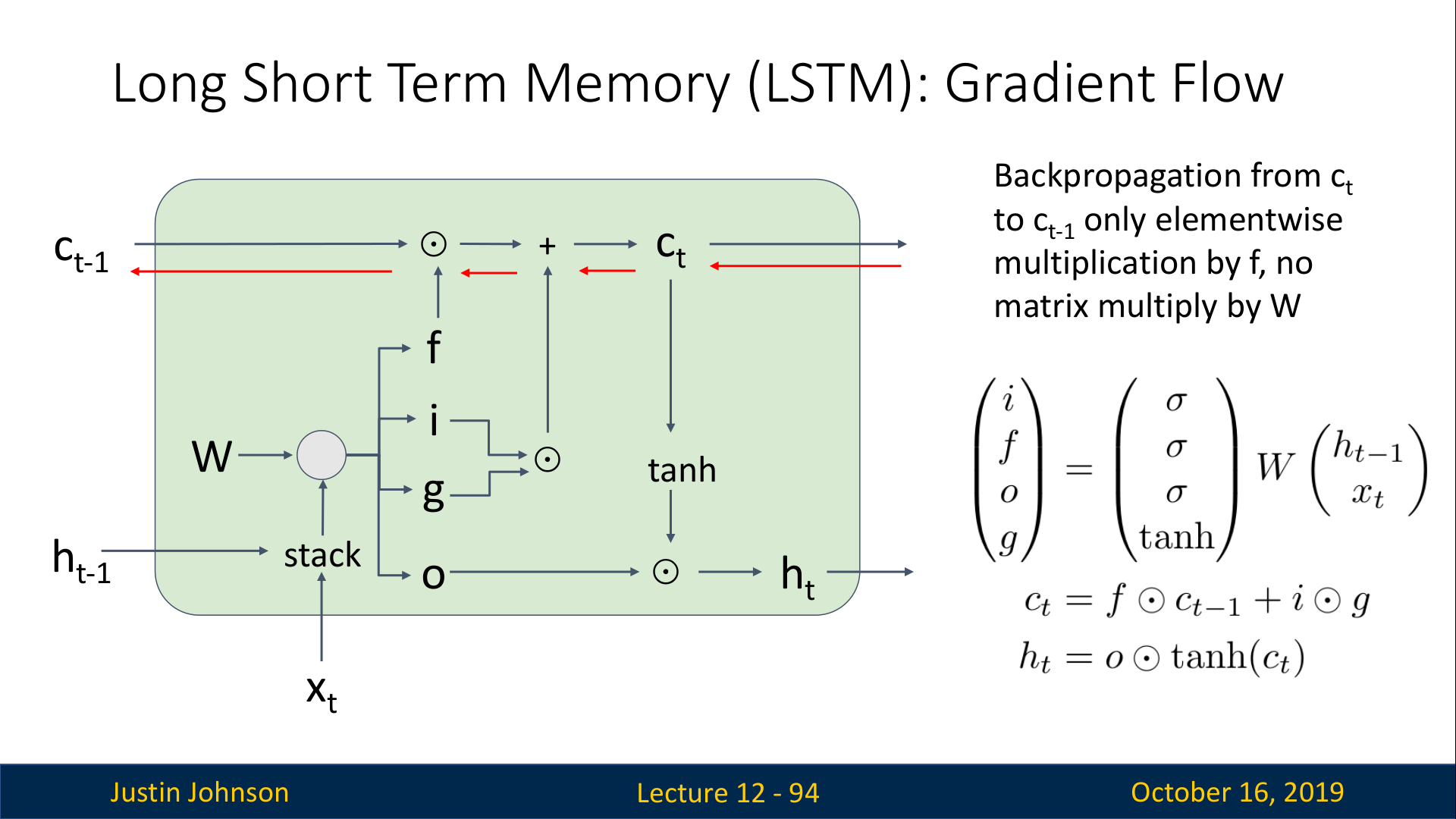
LSTM의 다이어그램을 통해 gradient flow를 보면서 back prop과정을 살펴보자 (c_t -> c_t-1)
c_t가 가장 먼저 만나게 되는 sum node +는 gradient distributor역할을 수행하기 때문에 gradient가 잘 전달된다. 다음으로 만나게 되는 forget gate와의 element wise 곱셈은 gradient를 파괴할 수도 있지만 0~1 사이의 값으로 조절되는 것이기 때문에 기본적으로 파괴하는 껏은 아니다. 이때, forget gate의 0~1 값은 sigmoid를 거친 후에 나온 값이기 때문에, sigmoid로 직접 backprop 되는 것이 아니다. 따라서 sigmoid에서의 gradient문제들도 일어나지 않는다. (강의에서는 이를 non-linearity에의한 문제가 없다라고 말함)
따라서, back prop 경로에 행렬
W와의 곱셈도 없고 element-wise 곱셈만 존재하므로 문제가 없다.
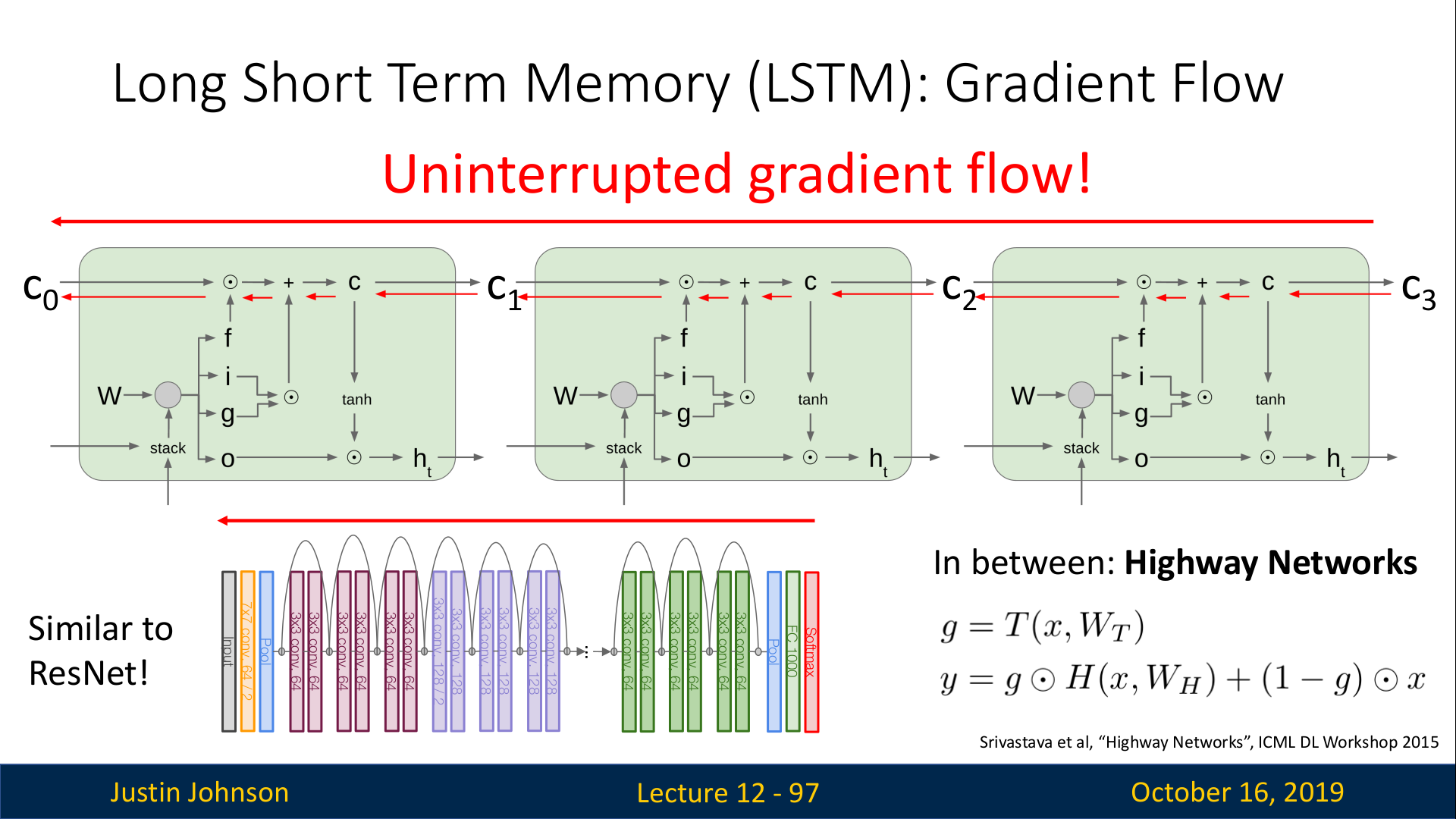
또한, 여러개의 cell을 위 슬라이드와 같이 연결하더라도, Back prop되는 경로에 방해되는 것이 없다.(Uninterrupted gradient flow)
Multilayer RNNS
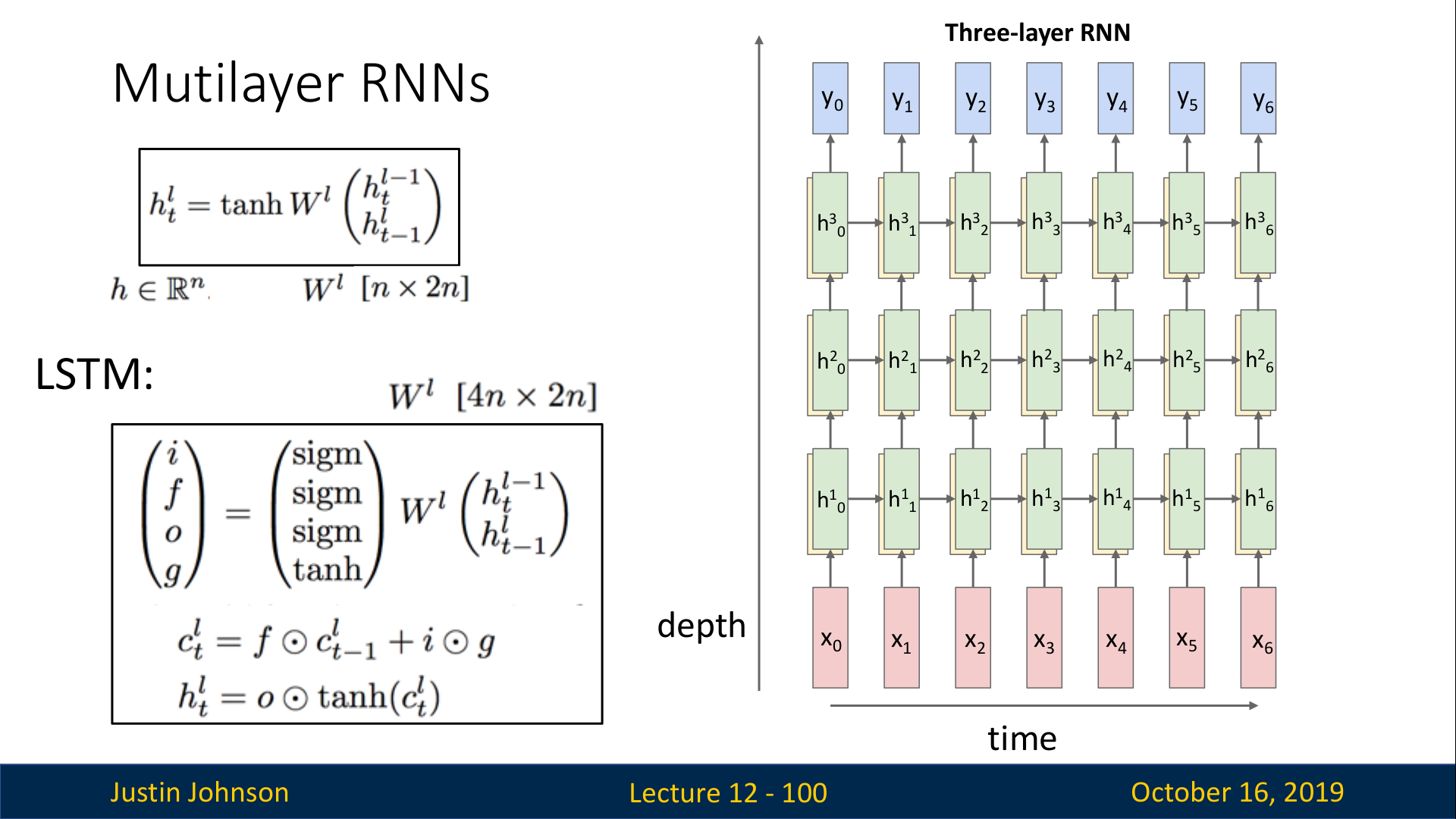
RNN도 마찬가지로 여러겹을 쌓아서 Multi layer로 구성할 수 있으며, 실제로도 성능에 약간의 향상이 있다.
하지만, RNN에서는 CNN처럼 매우 깊게 쌓는 구조는 흔하지 않으며, 주로 3~5개의 layer 정도로 구성된다.
이때, 각 layer끼리는 다른 가중치 행렬
W를 사용한다. (한 layer내에서는 앞에서 배운대로 동일한 W를 사용한다.)
Other RNN Variants

RNN 중에서 짚고 넘어갈만한 모델은 위 슬라이드 왼쪽의 GRU(Gated Recurrent Unit)가 있다.
LSTM을 단순화한 버전이라고 생각할 수 있으며, LSTM과 마찬가지로 추가적인 연결을 통해 gradient flow를 개선시킨 모델이다. (강의에서 자세하게는 다루지 않음)
또한, brute force로 수만개의 조합을 직접 탐색하면서 좋은 성능을 내는 RNN 모델을 찾으려는 시도도 있었지만, LSTM보다 아주 우수한 성능을 내는 모델은 찾지 못하였다. (슬라이드 오른쪽에 있는 논문)
참고 : https://younnggsuk.github.io/2020/12/23/eecs-12.html