Training Neural Networks (Part 2)
Overview

Learning Rate Schedules
어떤 learning rate가 이론적으로 좋다 이런거 없음. 넣어봐가면서 살펴봐야함. 어떤 옵티마이저를 쓰던 러닝레이트는 사전에 정의해줘야함. 그르면 어떤 learning rate를 선택하는 것이 좋을까?
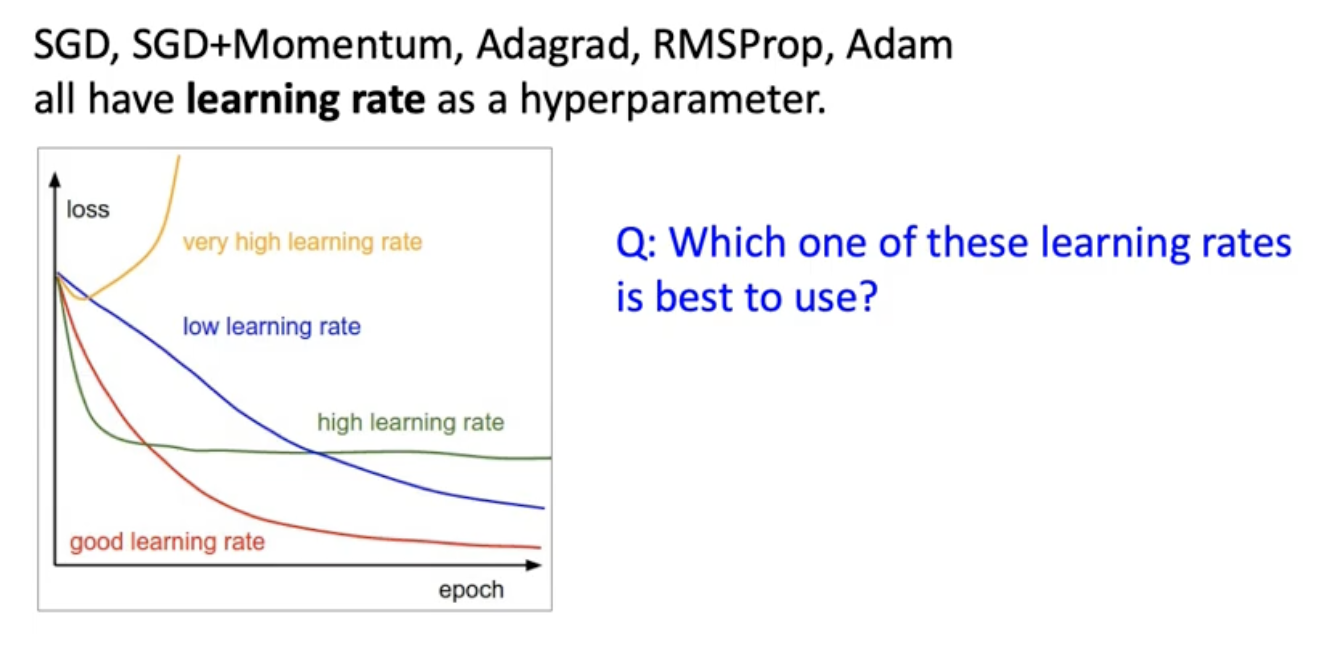
그림을 보면 4가지 경우로 나눠서 얘기하고 있음. learning rate를 너무 높게 잡으면 (노란색) 처음에 떨어지는것 같더니 점점 바깥으로 튀어나감. loss가 오히려 높아져 버리는 상황. 긇다고 해서 learning rate를 아주 낮게 잡으면 (파란색) 점점 내려가기는 하는데 내려가는 속도가 답답할 정도로 느리게 내려가서 에폭을 많이 돌려야할 수도 있음. 그래서 learning rate를 너무 높게 설정하지 않고 low한 정도에서 조금 더 높게 가져가면 어떠냐 했을 때 (초록색) 맨처음에는 loss가 엄청 빨리 감소하는데 함정에 빠질 수 있는게 빨리 내려갔다가 더 낮아질 수 있는 가능성 있음에도 flat하게 유지될 수 있음. 우리가 가장 원하는 것은 빨간색 곡선임! 우리는 사전에 어떤게 빨간 곡선에 대응할수 있을지 모름. 경험적으로 가장 잘 work하는 전략은 일단은 큰 Learning rate에서 시작한다음에 에포크가 널어날 수록 learning rate를 낮추는 방법이 전략적으로 고려해볼만하다고 함.
Learning Rate Decau : step
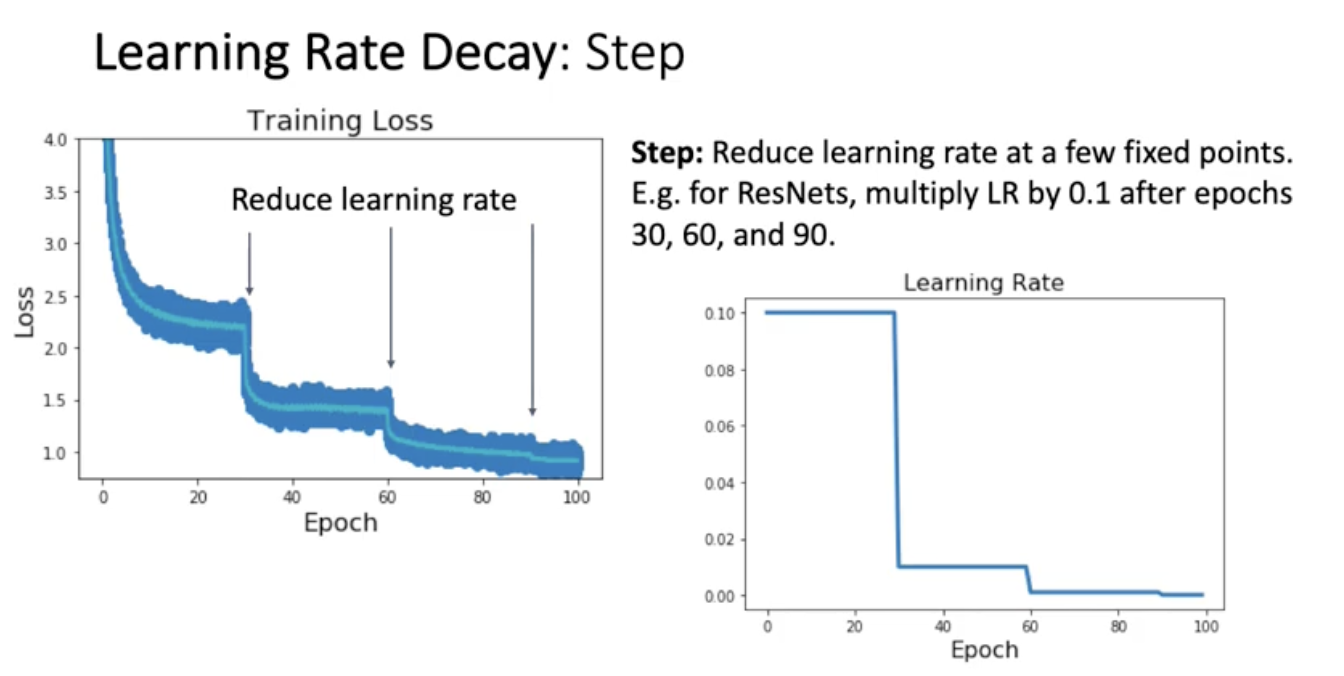
특정 에포크에서 learning rate에다가 0.1씩 곱해라 머 이런.. 오른쪽 그림을 보면 learning rate를 fixed point에서 낮춤. 예를 들면 레즈넷에서 에폭 30에 기존 러닝레이트에 0.1을 곱함. 그럼에 따라서 loss 곡선이 어떻게 생기는지 왼쪽을 보면 점 하나하나는 iteration한번해서 parameter 업데이트 한 이후의 loss 값. 파란 점들 중간의 초록 곡선은 moving average. 어떤 트렌드를 볼 수가 있냐면 learning rate를 떨어뜨리니까 loss가 쫙 내려감. 그리고 loss가 안내려갈쯤에 또 learning rate 떨어뜨림 그러면 loss 또 떨어짐. 실제적으로는 어떤 전략을 취하냐면 높은 learning rate를 고정해놓은 다음에 epoch를 돌려놓고 epoch가 증가함에 따라 loss가 얼마나 줄어드는지 실시간으로 관찰을 먼저 함. 그담에 적당히 멈출거 같으면 멈춘다음에 그 에포크에서 다시 decay를 시킴.
Learning Rate Decau : Cosine
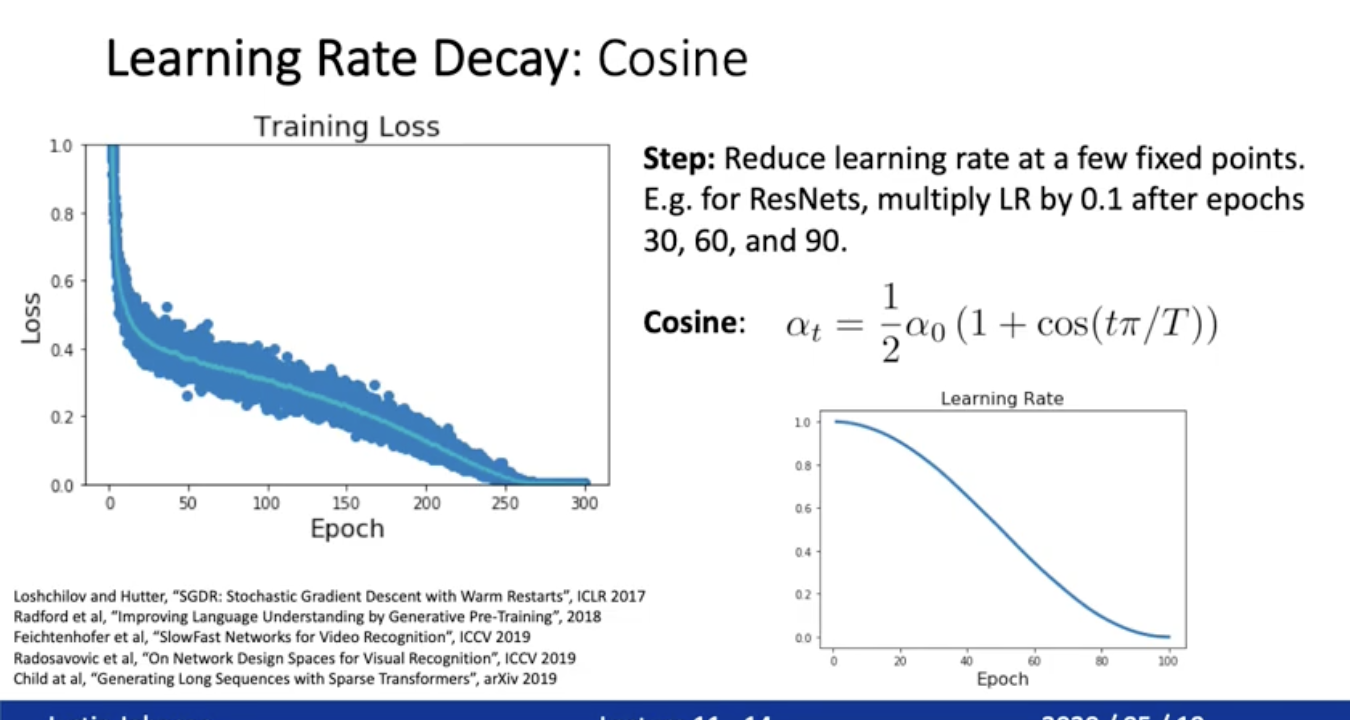
learning rate = 알파t. a0는 사전에 정의 해야됨. T는 트레이닝 시킬 에폭수 . 애폭은 t에 해당. 점점 사람들이 많이 쓰고 있음. step에 비해 장점은 a0랑 T만 결정하면 되니까 조금 더 하이퍼파라미터 고민의 여지가 줄어들었다.
Learning Rate Decay : Linear

Learning Rate Decay : Inverse Sqrt

Early Stopping
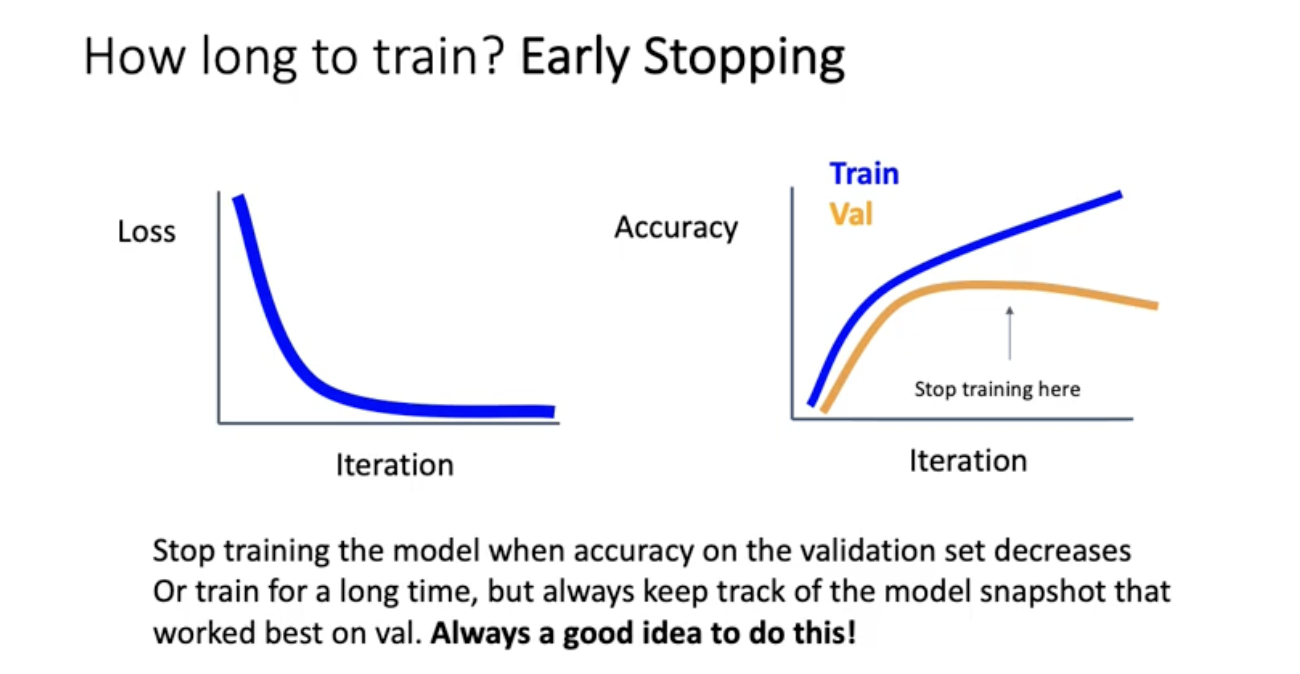
loss decay만 보는게 아니라 오른쪽의 training set validation set accuracy curve를 같이 봐야됨. 보기에는 Loss를 계속 낮추는게 좋을것 같은데 validation set accuracy가 점점 감소하려는 모습을 보이면 멈춰야됨. validation accuracy가 떨어지고 training accuracy가 오른다는 것은 학습 자체가 training set에 오버피팅. 그래서 그 전에 멈춰야됨. iteration 돌때마다 모델의 snapshot을 저장하도록 한 다음에 validation set에서 가장 잘 work할 때를 골라서 해당 화살표에 해당하는 sanption weight를 불러오면 됨. 언제나 좋은 아이디어임.
Choosing Hyperparameters
보통 신경을 쓰는 파라미터는 크게 2개인데 하나는 weight decay라고 쓰는 l2 regularization의 strength. 람다에 해당하는 수치. 2번째는 learning rate이다. 직관적으로 weight decay나 learning rate모두 log linear하게 고려. 같은 수씩 등비수열로 곱한 다는 것. 이게 grid search임

Grid search 말고 사람들이 고려하는게 random search. random search는 log linear space에서 random하게 고르는 것.

많은 사람들이 random search를 추천함. 왜일까? 여러분들이 가진 데이터세소가 모델에 따라서 어떤 하이퍼파라미터가 중요할지는 아무도 모름. 그 상황에서 만약에 equal grid search하게 되면 좌측처럼 됨.
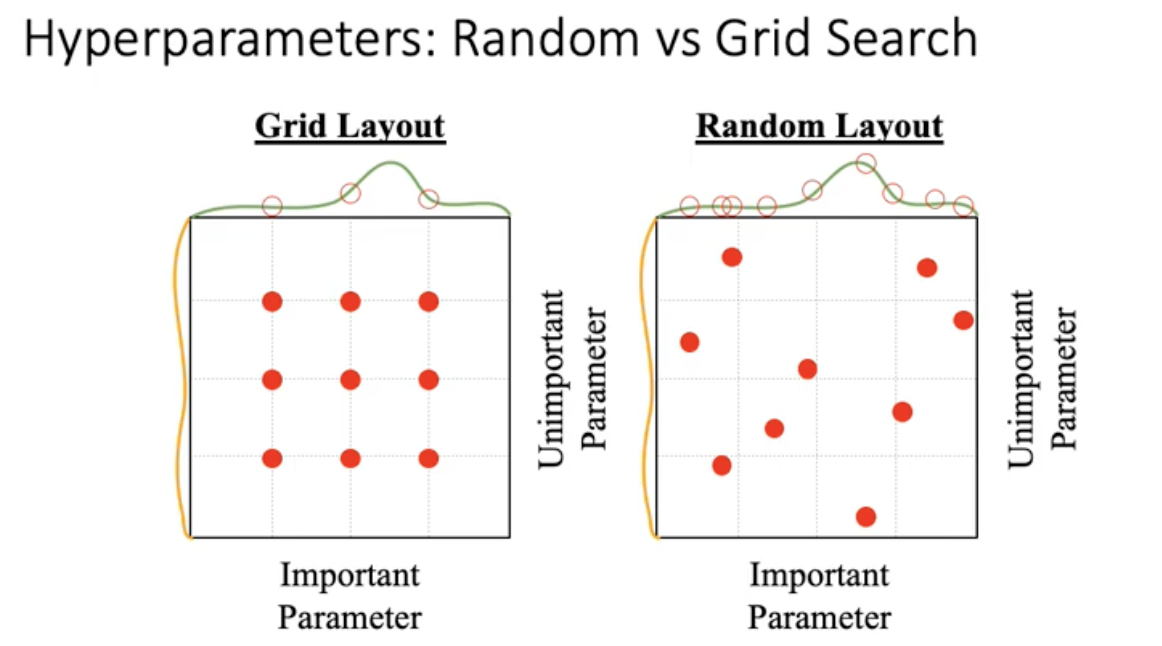
반면에 random search로 고르면 중요한 하이퍼파라미터가 있다면 여러개를 고려해봤을테니까 우리도 모르는 하이퍼파라미터에 대해서 다양한 고려를 할 수 있음. 실제로 random search가 더 낫다는 실험적인 결과가 있음.
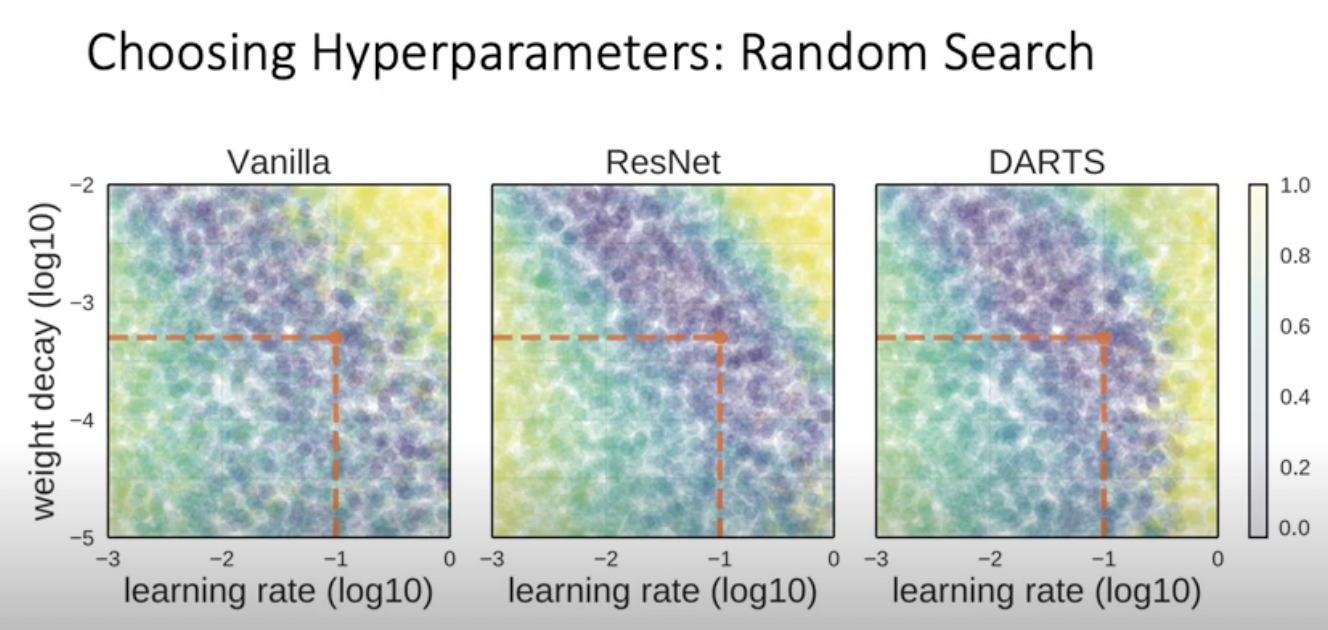
보라색 부분이 더 잘 작동한 곳. 노란색은 잘 작동하지 않음
Choosing Hyperparameters
GPU가 많지 않아도 충분히 좋은 선택을 할 수 있음.
- Step 1: Check initial loss 맨첨을 loss 값이 softmax에서는 log(C)가 나와야 에러 없이 잘 네트워크 짜여졌다는 것. sanity check
-
Step 2 : Overfit a small sample 네트워크를 잘 짰다면 작은 데이터셋에 대해서 100%의 정확도를 달성할 수 있어야 됨. 미니배치 10개로 빨리빨리 돌려보면서 작은 training set에서 100% accuracy 달성해야.

loss가 잘 떨어지지 않으면 learning rate가 너무 낮은 것은 아닌지, Initialization이 잘 안된 것은 아닌지, 확인해봐야함 -
Step 3 : Find LR that makes loss go down 모든 트레이닝 데이터를 사용. L2 regularization은 작은 걸로 켜시고 100번정도의 iteration(epoch아님) 동안 learning rate를 10의 -1승부터 시도해보면 loss가 가장 많이 떨어지는 Learning rate 찾음. 좋은 러닝웨이트라면 맨 처음의 iteration동안 loss가 매우 빨리 떨어지는걸 확인할 수 있음.

-
Step 4: Coarse grid, train for ~1-5 epochs 100번의 iteration에서 벗어나서 에포크를 1번에서 5번정도까지 돌려봐라. 이때 weight decay까지 조어해봄.

- Step 5 : Refine grid, train longer
-
Step 6 : Look at learning curves
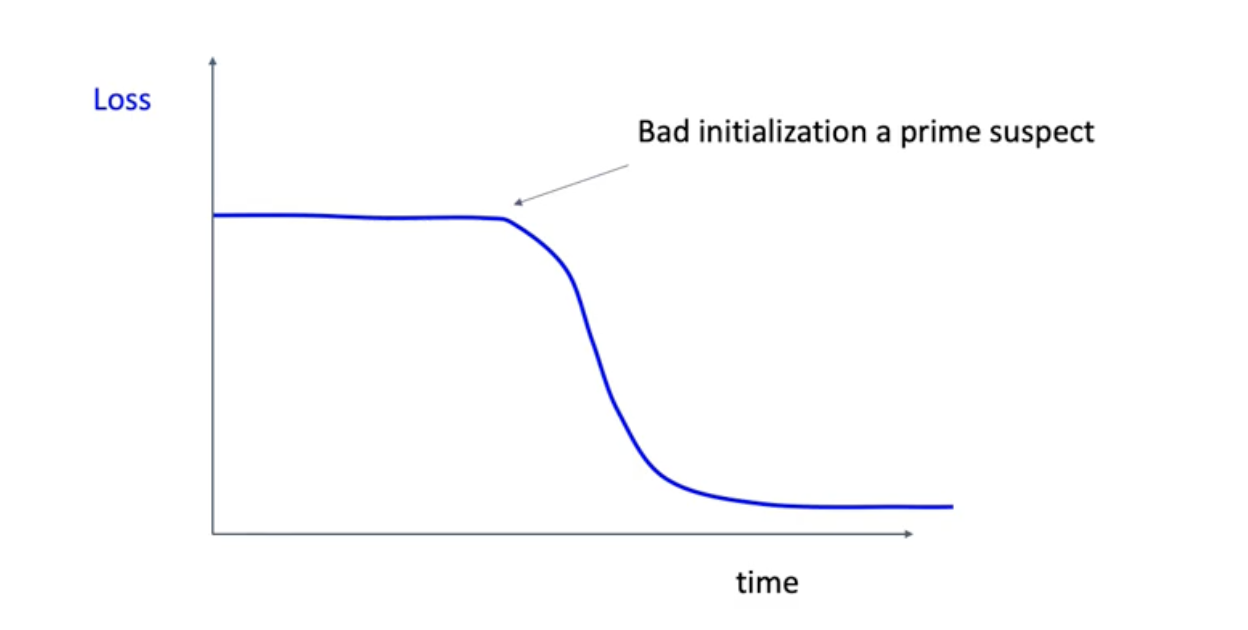
training loss curve가 flat하다가 떨어진다고 했을 때 initialization 전략이 안좋을 수도 있음. 이때 weight initialization 설정을 바꿔보기.
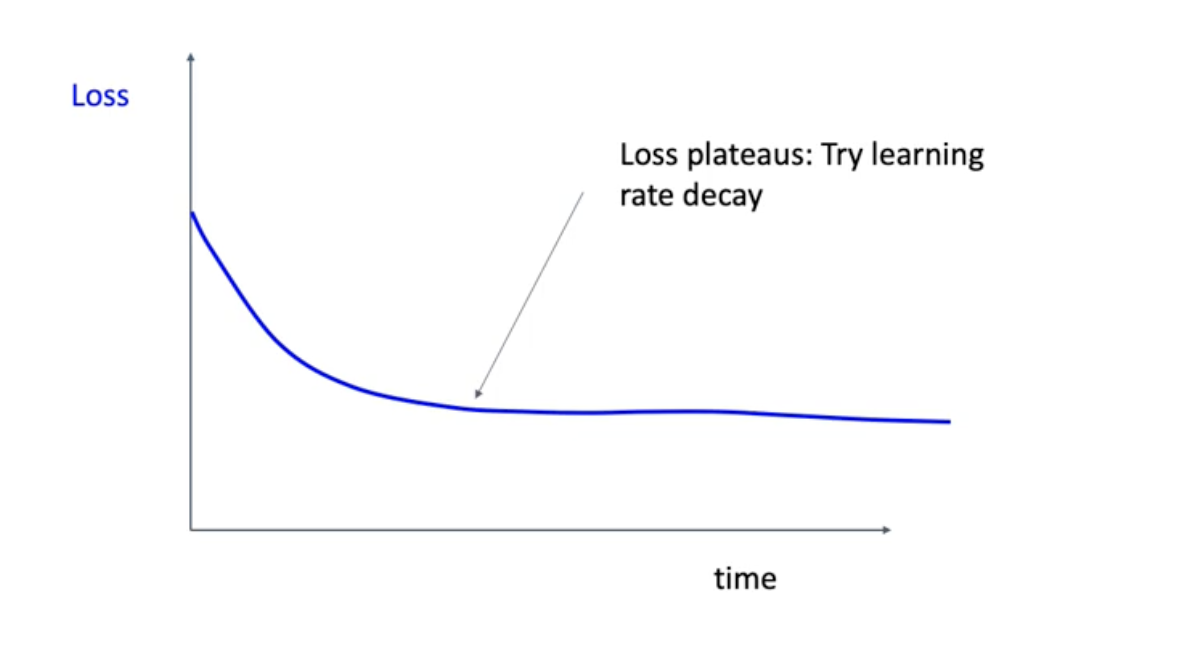
그리고 loss가 더 떨어질 수 있을것 같은데 안떨어져. 이러면 learning rate decay를 시도해보기. 그래서 ㅣearning rate decay를 시도했어 그랬더니 더 flat해져 버렸다. 그면 뭐 때문일수있냐 이건 우리가 learning rate를 너무 일찍 떨어뜨려 버렸기 때문. 아래 그림 참고
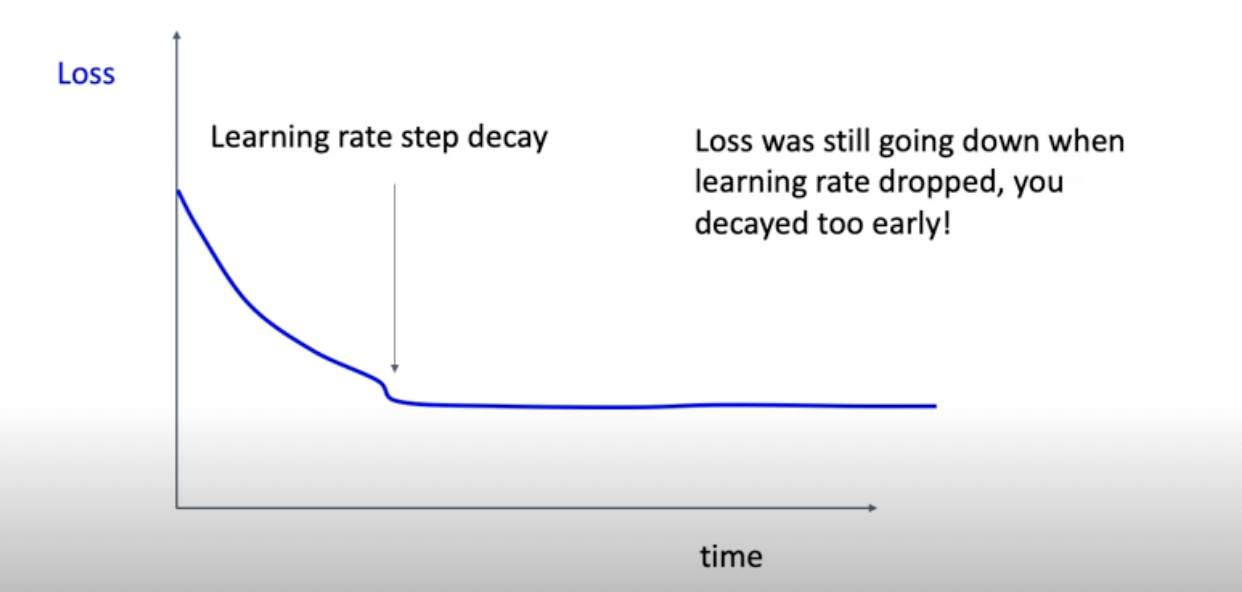
이럴때면 좀 더 지켜봤다가 flat한 트렌드가 좀 더 유지될때까지 참은 다음에 learning rate decay하기를 추천.
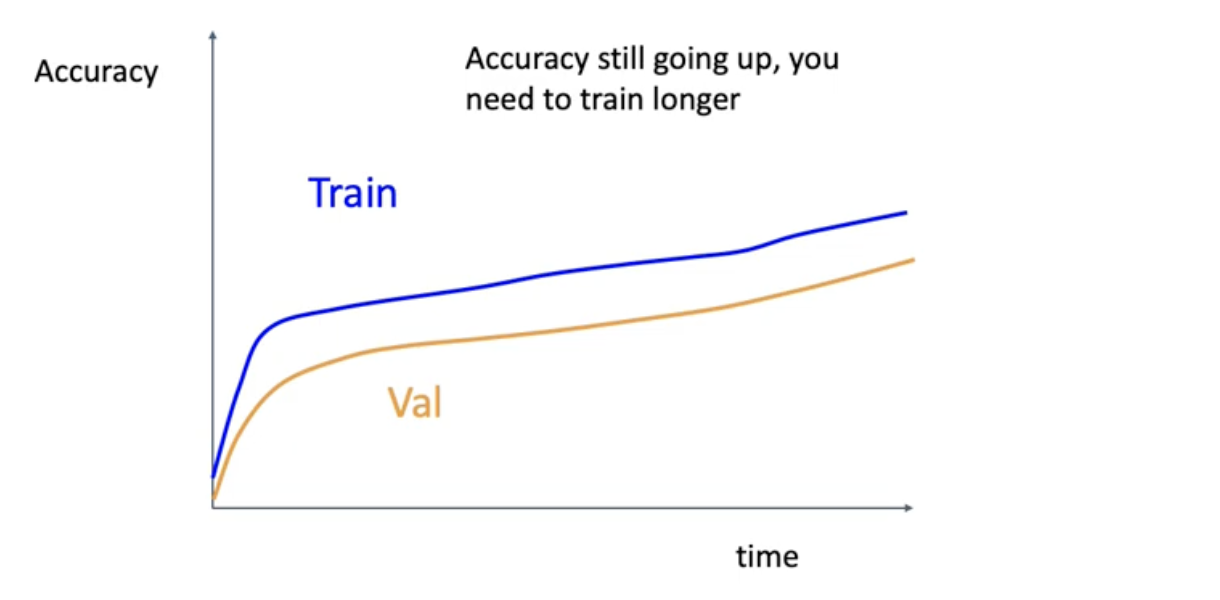
만약에 이런 상황이면 validation accuracy가 어디까지 올라가는지 지켜볼 것.
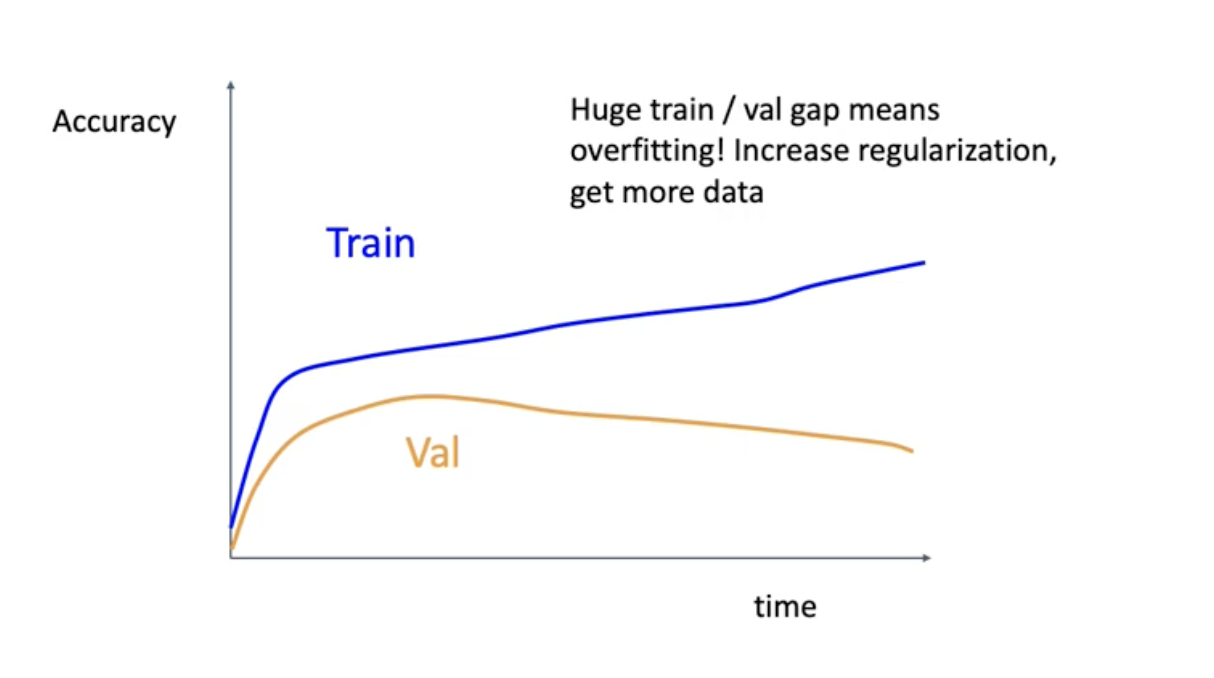
이건 overfitting이 일어나는 상황. 이런 상황에서는 첫번째로 regularization의 strength를 올려볼것. l2 reugularization의 람다값을 올린다는 의미가 될 수 있고 아니면 다른 의미의 regularization 예를 들면 dropout이나 batch normalization 같은거. 어떤 의미로건 regularization 세게 하는 방법 고려해보길 바람.
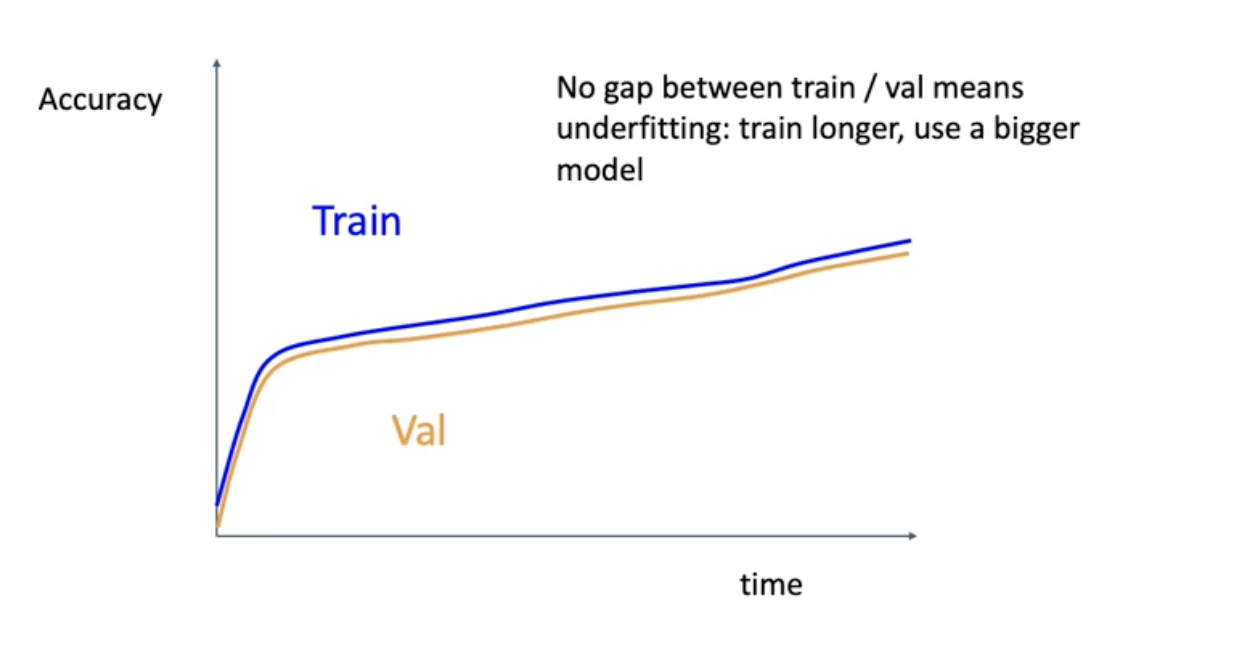
위와 같은 상황에서는 training set의 accuracy와 validation의 accuracy가 비슷하게 올라감. 근데 이건 좋은 사인이 아닐 수있음. underfitting이 일어나는 것일수도.. 트레이닝 셋은 충분한데 학습기가 잘 배우지 못하는 것일수도. 이럴때는 트레이닝을 더 오래해보던가 큰 모델을 이용한다. - Step 7 : GOTO step 5 step 5로 돌아가서 또 다른 grid를 생각해보고 많이 배워봐라.
그래서 주로 놀만한 hyperparameter가 머가 있냐. 첫번째로 network architecture가 있고 두번째로 learning rate, decay schedule, 그 Decay를 step으로 할거냐, linear하게 할거냐 등등 , 혹은 regularization

우리는 만치 결과를 모르는 여러가지 setting을 실험하는 것과 비슷함. 우리가 hyperparmeter를 조정한다는것 자체는 귀납적인, 과학적 추론과정과 비슷. 그러면 실험을 할때 자연대 대학원생이 하는 그런 approach를 시도해보는게 좋음. 실험노트에 하나하나 적는거. 어떤 setting을 했고 어떤 결과가 나왔는지. 이게 정도.
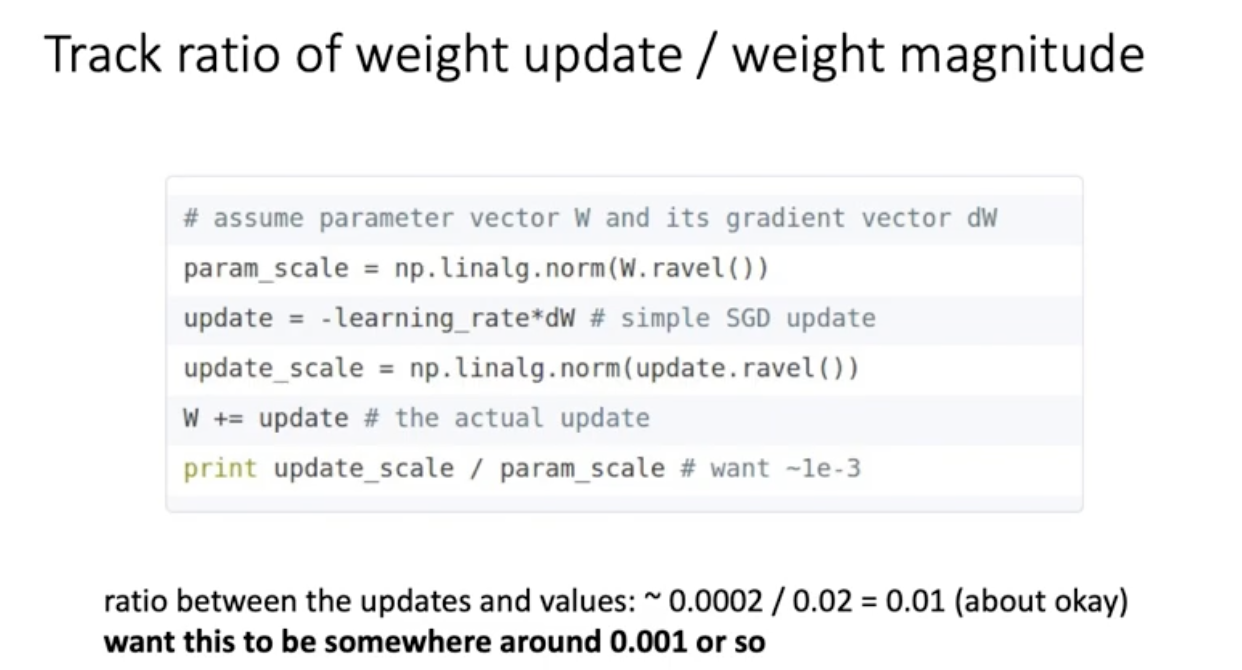
그리고 위 그림은 debugging tip 같은 건데 만약 training을 잘 하고 있다면은 weight 전체의 absolute value (l1 norm)이랑 gradient 업데이트 값의 l1 norm이랑 ratio를 비교했을 때 한 0.01에서 0.001정도의 비율이 나옴. 이 비율이 너무 높으면 이상한게 일어나고 있다는 것.
After training
Model Ensembles
여러개의 독립적인 모델 훈련한 다음에 test time 때 각각의 모델들의 결과를 average함. 보통 2퍼센트 정도의 extra performance를 더 누릴 수 있음.
Model Ensembles : Tips and Tricks
딥러닝 분야에 한해 메인스트림은 아니지만 하나의 모델만 트레인 하고서도 앙상블을 흉내낼 수 있는 재밌는 아이디어 들이 있음.
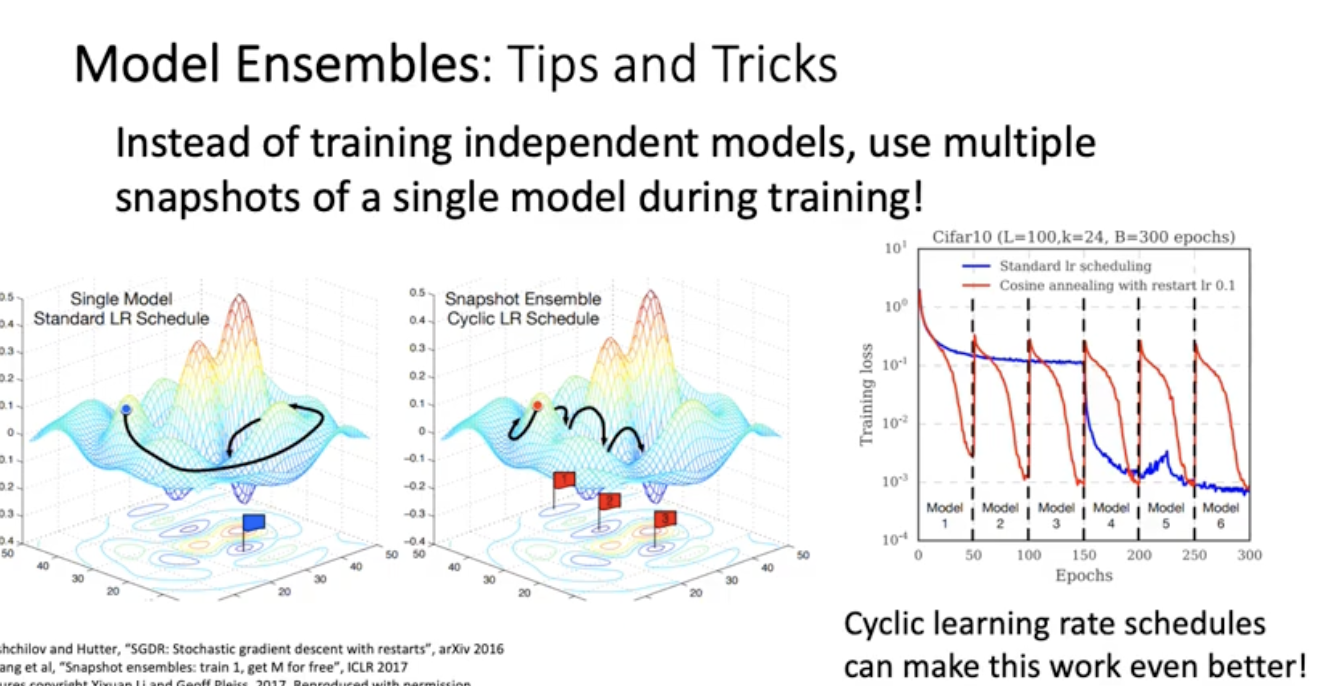
learning rate scehdule을 오른쪽에 빨간색 선처럼 내렸다 올렸다 함. 그러면 learning rate decay 마지막에 50 100 150.. 300 번대에 모델 snapshot을 저장 해뒀다가 6개의 모델들에 대해 예측치 평균 내림. 앙상블 효과. 앙상블이란게 가장 큰 성능을 낼 수 있을 때는 independent하게 트레이닝 시켰을 때. independent 데이터인게 best이고 모델 예측 값들의 covariance가 0일수록 예측값의 전체 variance가 떨어지기 때문에 훨씬 더 예측력이 좋아짐. 한 모델 내에서 여러 snapshot 앙상블이니까 성능이 꼭 올라갈거라고 기대는 못할 수 있음.

training 끝내고 마지막 weight를 최적 모델로 쓰는게 아니라 최근 100번 동안의 weight average를 파이널 모델로 쓰는 것. 이거는 polyak averaging이라고 함.
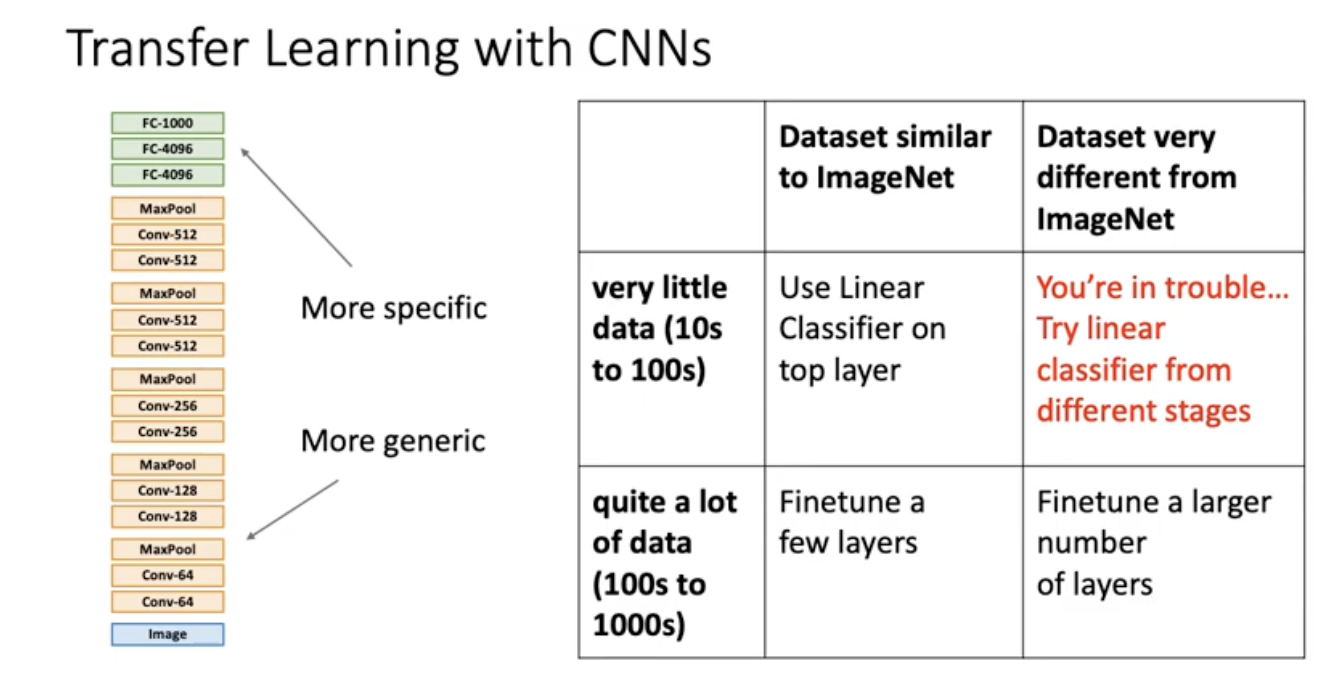
Transfer Learning
Transfor Learning의 기본 철학은 좋은 CNN 분류기를 얻기 위해 무조건 많은 데이터가 필요하냐? 그게 아님. 좋은 데이터셋에서 트레이닝 된 네트워크 구조가 있으면 예를 들어 이미지넷 데이터에서 트레이닝 한 weight가 달려서 다운됨. 그 weight값을 활용해볼 수 있음. 예를 들어 alexnet다운 받고 나서 fully connected layer는 날려버리고 남은 레이어 까지의 weight들은 freeze를 해서 업데이트에 전혀 사용하지 않음. feature 추출기로 사용.
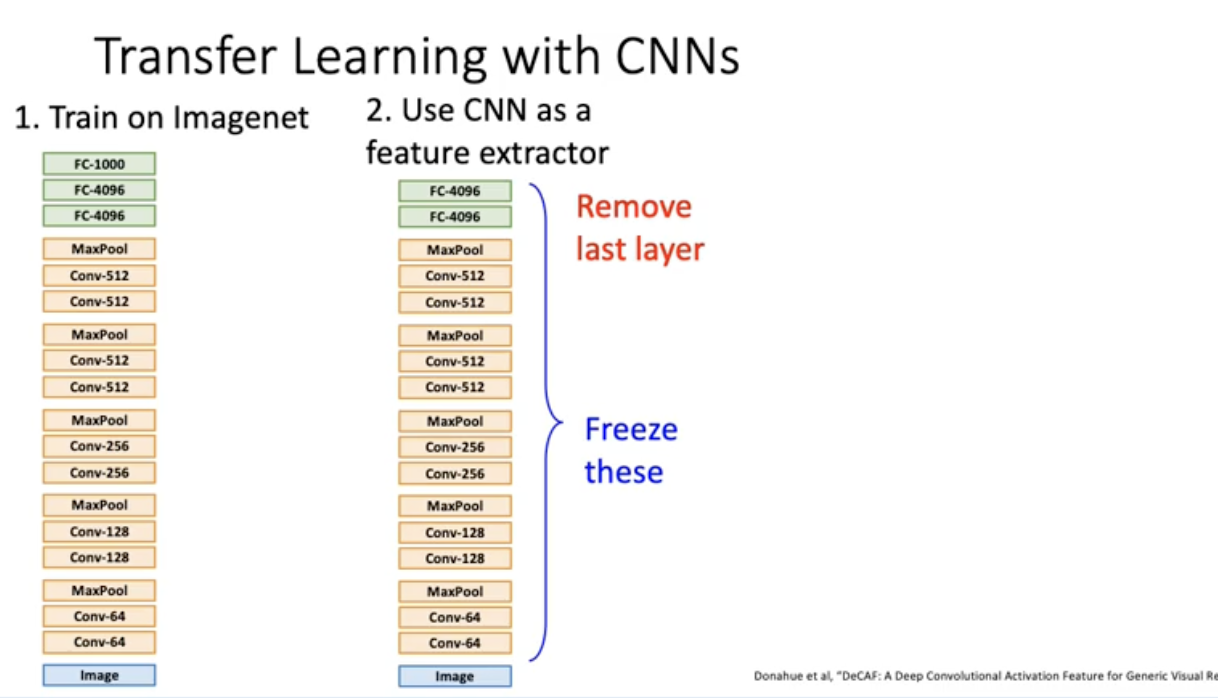
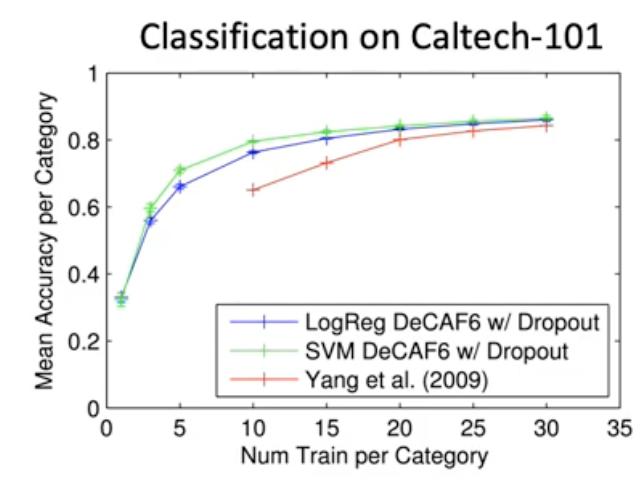
이렇게 했을 때 옛날 2009년의 custom하게 rule 기반으로 피쳐 추출기 만들고 그 위에다가 linear classifier한 방법 (빨간색 곡선) 보다 알렉스넷 탑 레이어 빼버리고 나머지 피쳐 추출기로 써서 그 위에 linear classifier 돌렸을 때 (초로색, 파란색) 더 좋은 성능을 냄.
여기서 질문! 우리가 불러온 weight들을 weight의 initial value로 해서 우리의 데이터셋에 대해서 계속 learning을 이어나갈수 없느냐. 그걸 사람들이 보통 fine tuning이라고 부른는 방법임.

fine tuning은 마지막 레이어 완전히 날리는 건 똑같고, 마지막은 새로운 weight로 initialization해서 얹고, 나머지 weight에 대해서도, 우리가 갖고 있는 데이터셋에 대해서 업데이트. 그니까 다운로드 받은 weight를 Initial value로 사용하는 것.
fine tuning에서의 trick :
- Train with feature extraction first before fine-tuning : fine tuning 하기 전에 먼저 feature 추출기로 사용해 볼것. last layer만 배움. 나머지는 freeze하고. 그러면 이게 baseline 성능이 됨.
- Lower the learning rate : use ~1/1- of LR used in original training : 원래 training시의 learning rate보다 낮은 learning rate 사용하는 것 추천.
- Sometimes freeze lower layers to save computation : 이미지 근처의 낮은 레이어 있고, 분류기 근처의 높은 레이어가 있는데, low level layer는 computational 비용을 save하고, 어떤 이미지가 들어오건 low level feature extraction은 비슷하다, 이런 가정이 들어있어서 암튼 low layer를 ,freeze함.
그러면 실제로 많이쓸까? 매우 만연하게 많이씀.
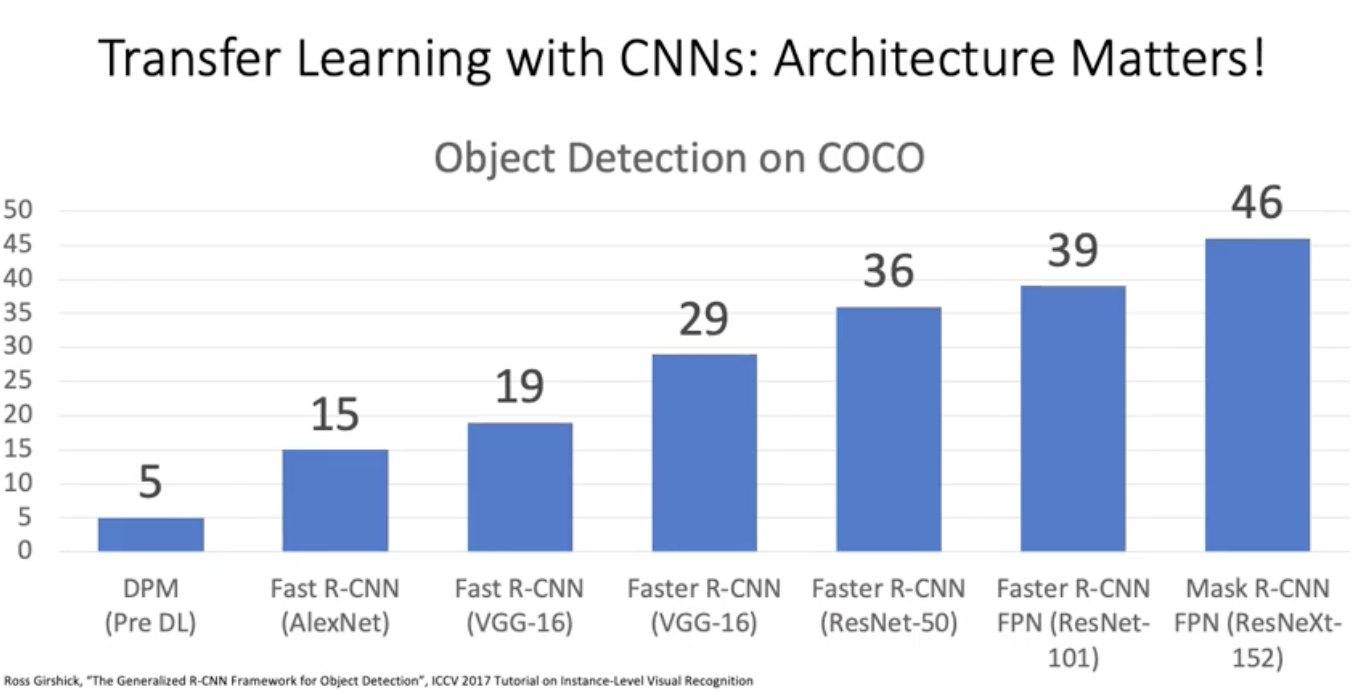
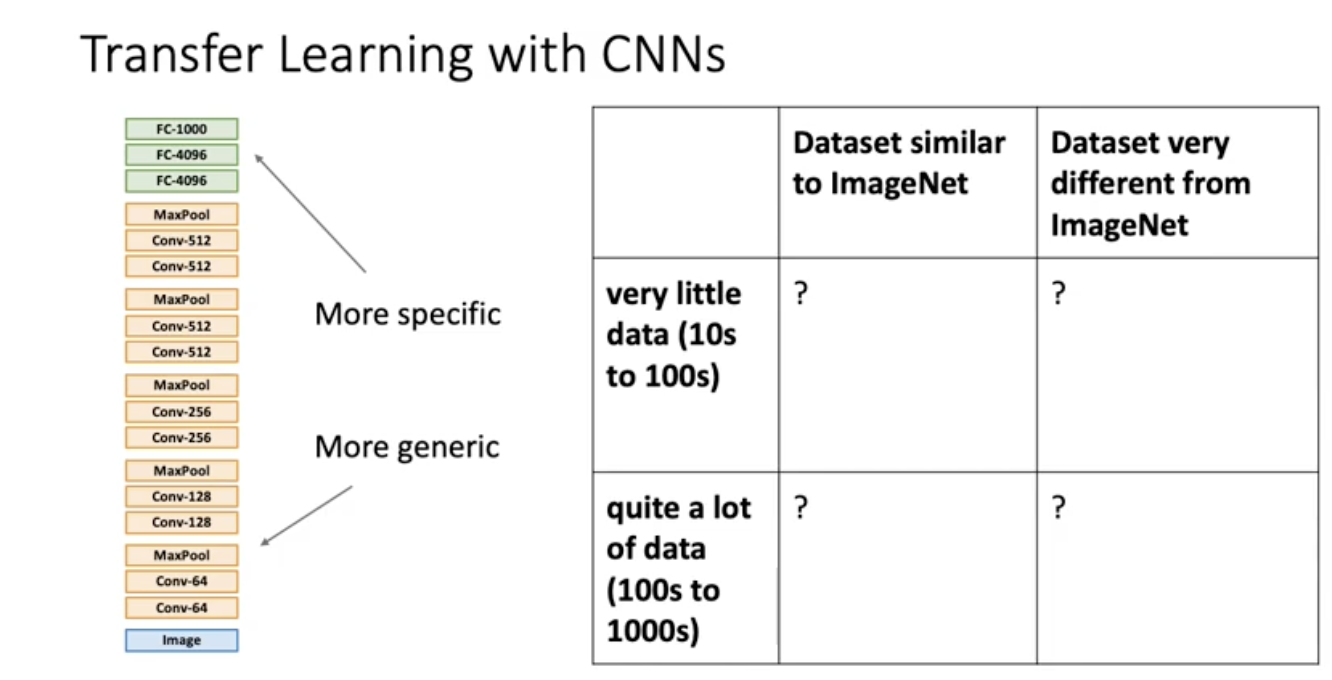
우리의 이미지가 이미지넷 데이터와 다를수도 있고 비슷할수도 있음. 이미지넷 데이터와 비슷하게 생길수록 둘의 dataset distribution이 가까울 테니까 아마 많은 도움을 줄 것. imagenet으로 pretrained된 resnet instance들이 많은 도움을 줄 것. 그러나 만약 여러분 데이터셋의 생김새가 이미지넷과 너무 다르면 두 데이터셋의 distribution이 너무 다르기 때문에 이미지 넷 데이터 셋이 줄수 있는 도움이 될 가능성 별로 없다. 정리해보자면 아래 그림과 같다.