CNN Architectures
AlexNet
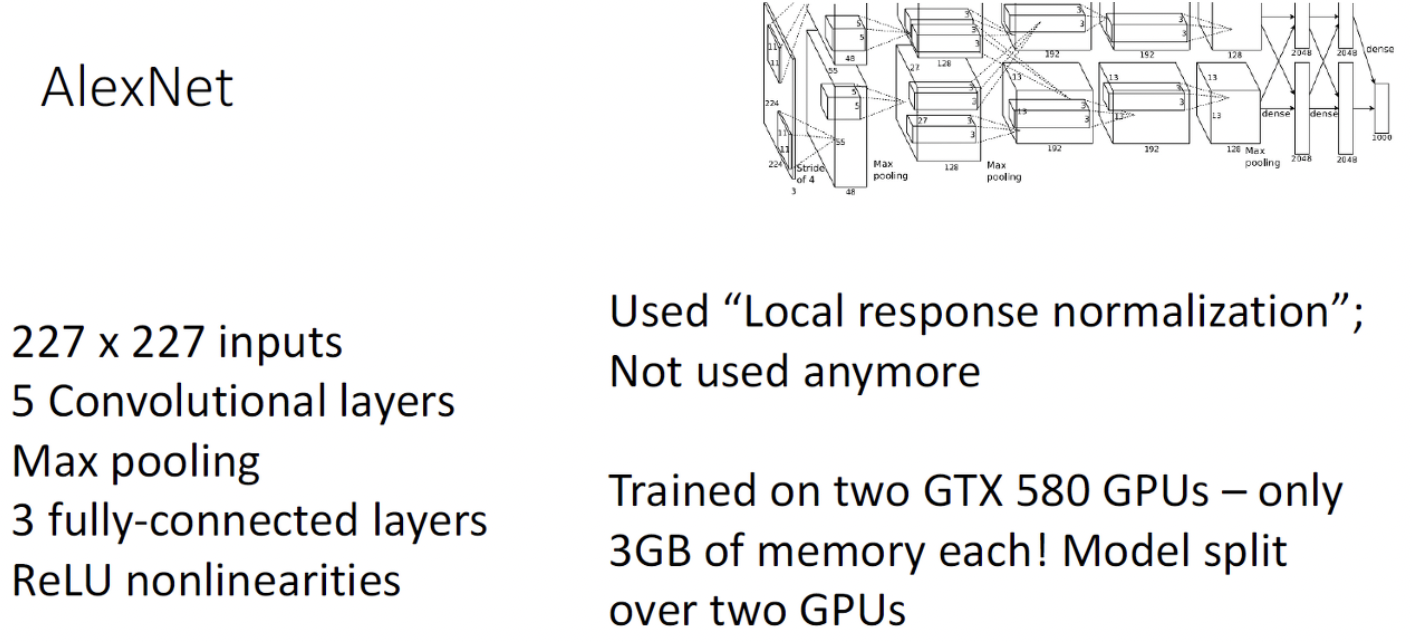
먼저 이미지넷 데이터가 227x227이니까 input으로 쓰고 지금은 deep하지 않지만 그때만 해도 5층의 layer는 deep한 모델이었음. 그리고 몇개 layer마다 맥스풀링을 했고 convolution layer를 얹고 나서 마지막에 나온 채널과 픽셀들을 한줄로 쭉펴서 그 위에는 fully connected layer를 쌓음. 또한 주목할만한 점은 Alexnet은 Relu activation을 사용한 첫번째 neural network임.
이때, 지금은 사용하지 않는 테크닉들이 쓰이는데, 이를테면 “Local response Normalization”이란 테크닉임. 이건 Batch Normalization의 옛날버전이라 하고, 이때만 해도 GPU의 메모리가 3GB밖에 없었음. (현재 코랩에서는 12기가 혹은 16기가의 메모리를 사용 가능함) 세부적으로 알렉스넷은 2개의 GPU로 병렬적으로 트레이닝되었음. 어떻게 병렬적으로 training 하는지는 10강즈음에 다시 나옴.
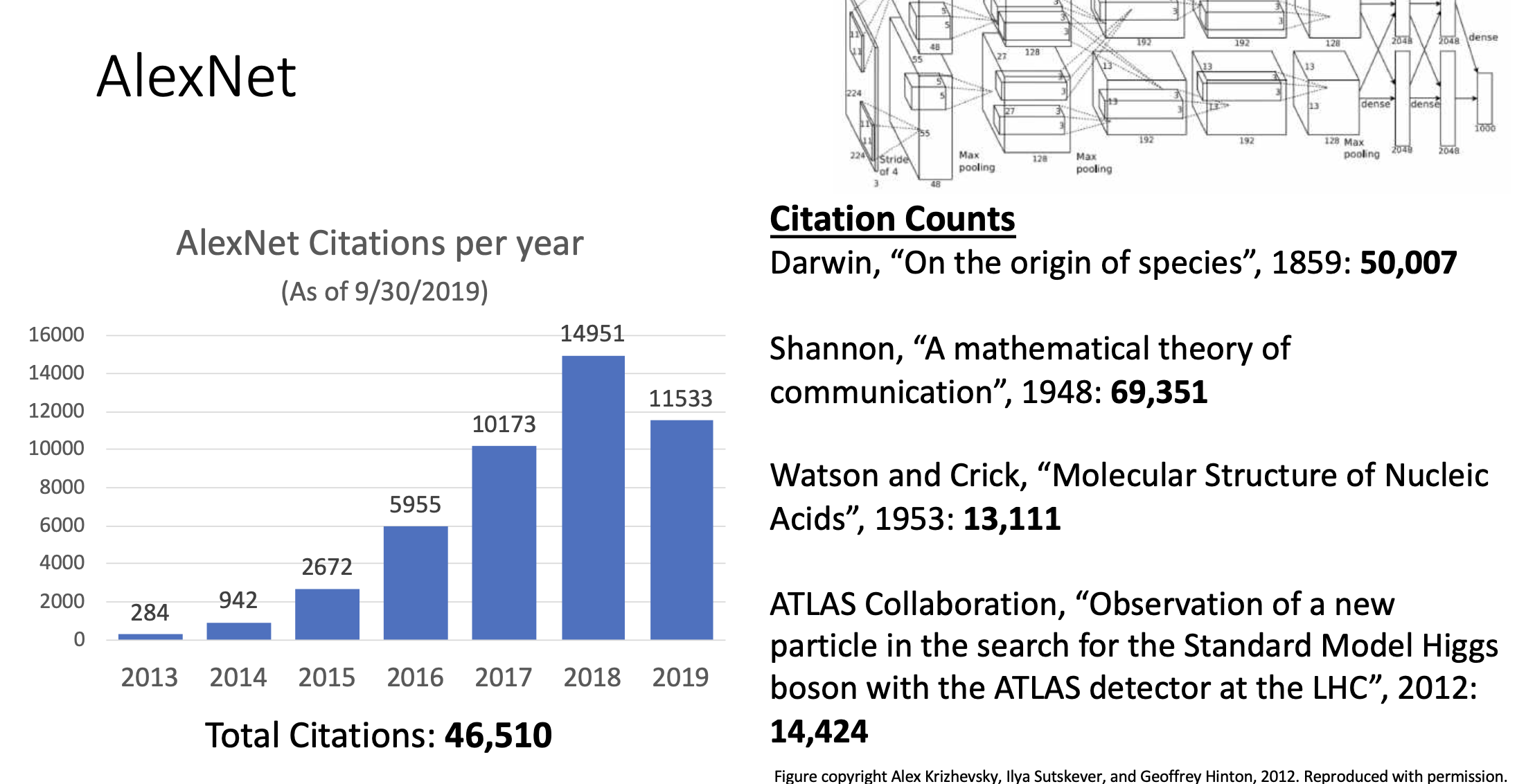
알렉스넷은 지금까지 약 46510번의 citation이 있었음. 논문이 얼마나 주목을 받고 영향을 미쳤는지는 논문이 얼마나 인용됐는지를 보고 생각함.
구조
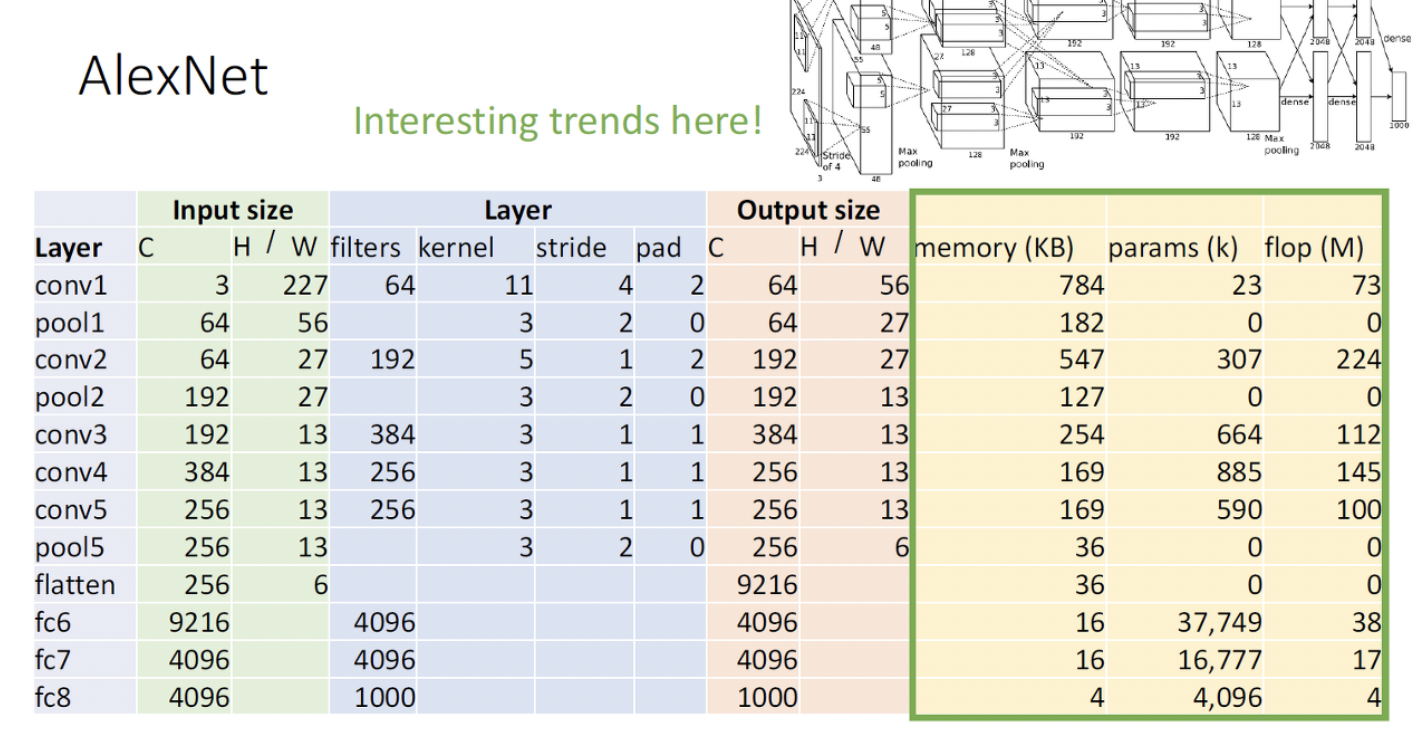
-
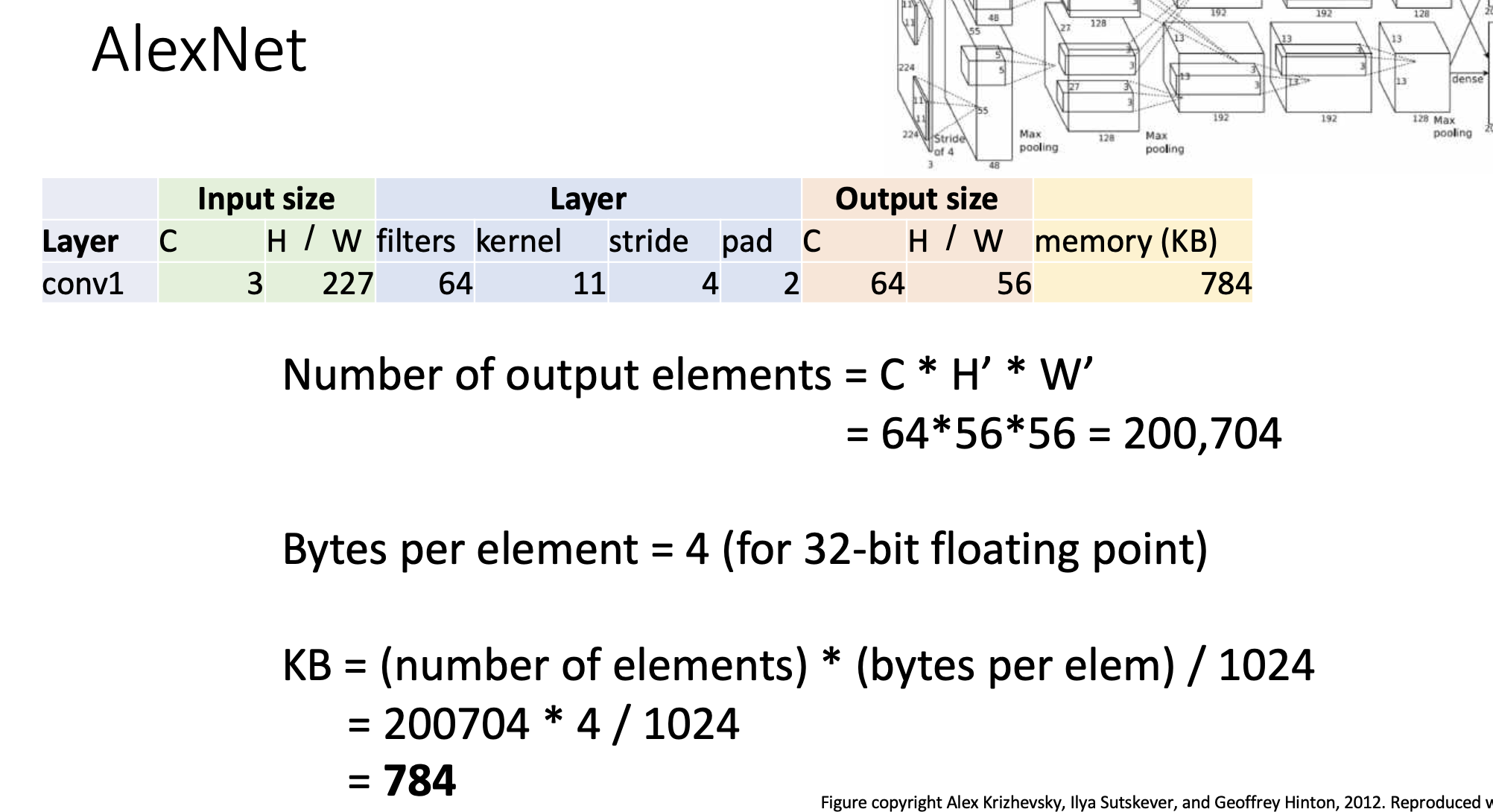
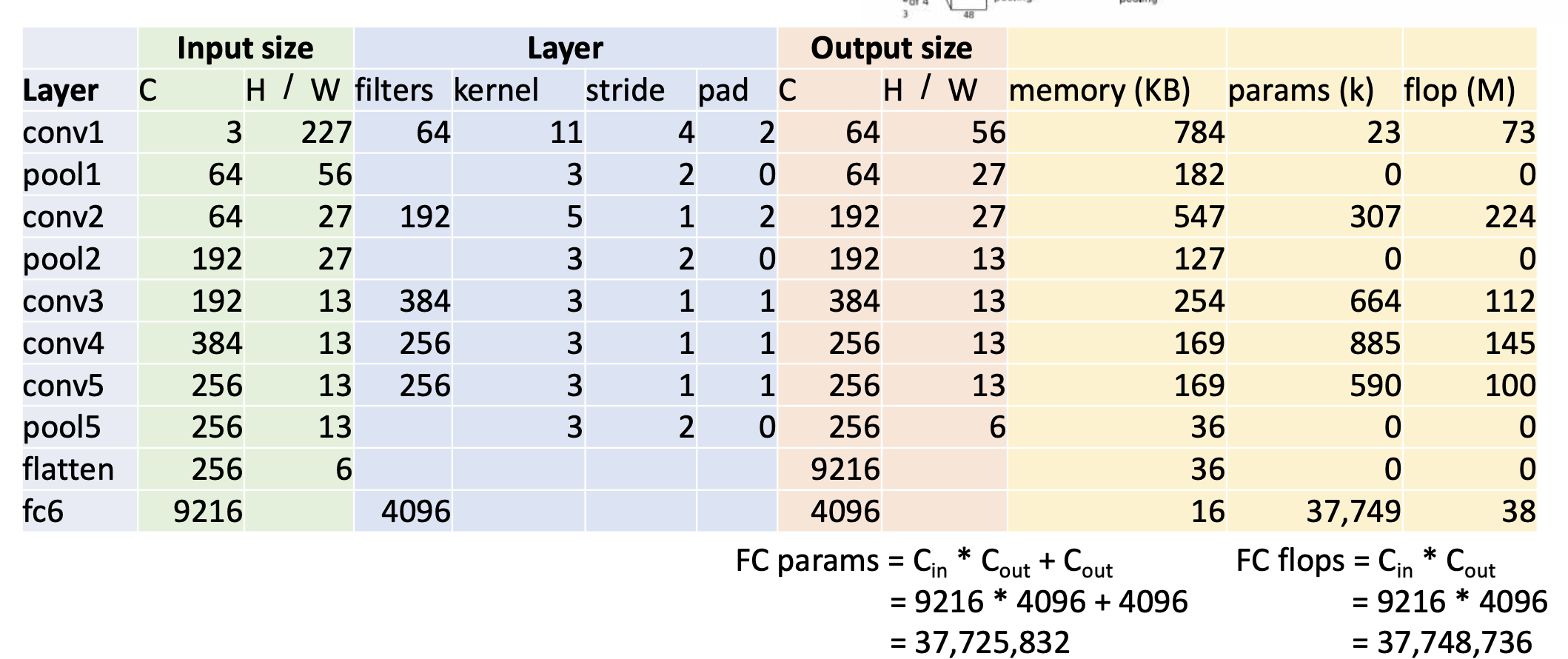
첫 레이어는 convolution layer. input channel = 3,(H,W)=(227,227),filter는 64개, 커널은 11x11이고 stride =4, padding = 2, 그러면 output volume size는 channel이 일단 64이고, 가로 세로 사이즈는 (227-11+22)/4+1 = 56이다. 그리고 메모리를 얼마나 차지하는지 계산을 해보면 일단 element 하나 당 4byte를 차지하고 (1byte가 8bit이니까 32bit이면 4바이트) 그래서 Number of output elements는 CHW = 645656 = 200,704정도. 그 다음에 얘네들을 4에 곱하고 Kb로 하기 위해서 1024로 나눠주면 784 Kb가 된다.
그 다음에, 메모리를 차지하는 또 다른 요소, 파라미터 개수르 알아보면
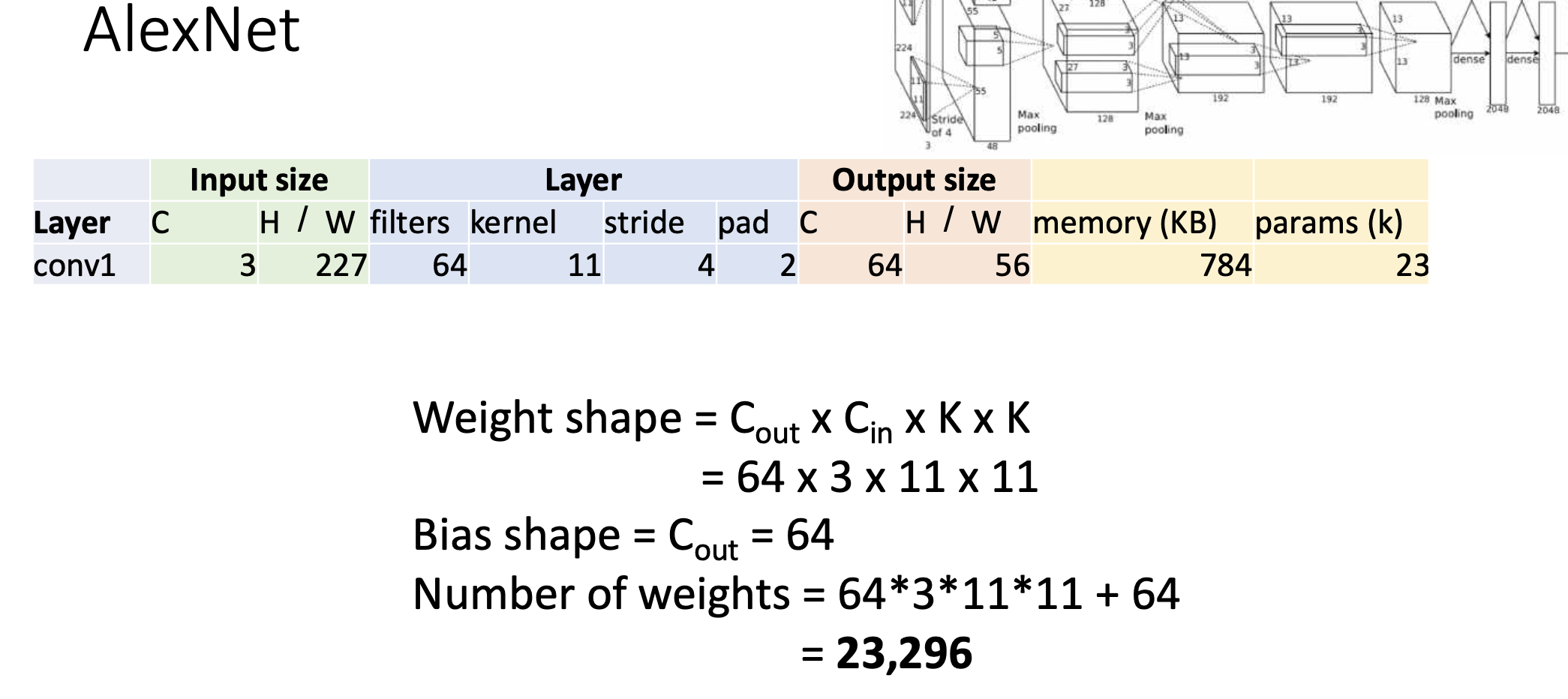
Number of Weights는 C(out)C(in)KK+(bias shape) = 64311*11+64 = 23296
그리고 output하나를 내놓는데 연산장치의 곱하고 더하는 연산 조합이 얼마나 많이 쓰이는지 보자. 이는 계산 정확도 뿐만이 아니라 네트워크의 효율성 측면에서 중요한 지표가 됨. 그래서 계산을 해보면 아래 그림과 같다.

-
두번째 layer는 pooling layer이다. pooling 시에 채널 수는 동일하다. (input=output channel)pooling의 결과는 다음과 같다.
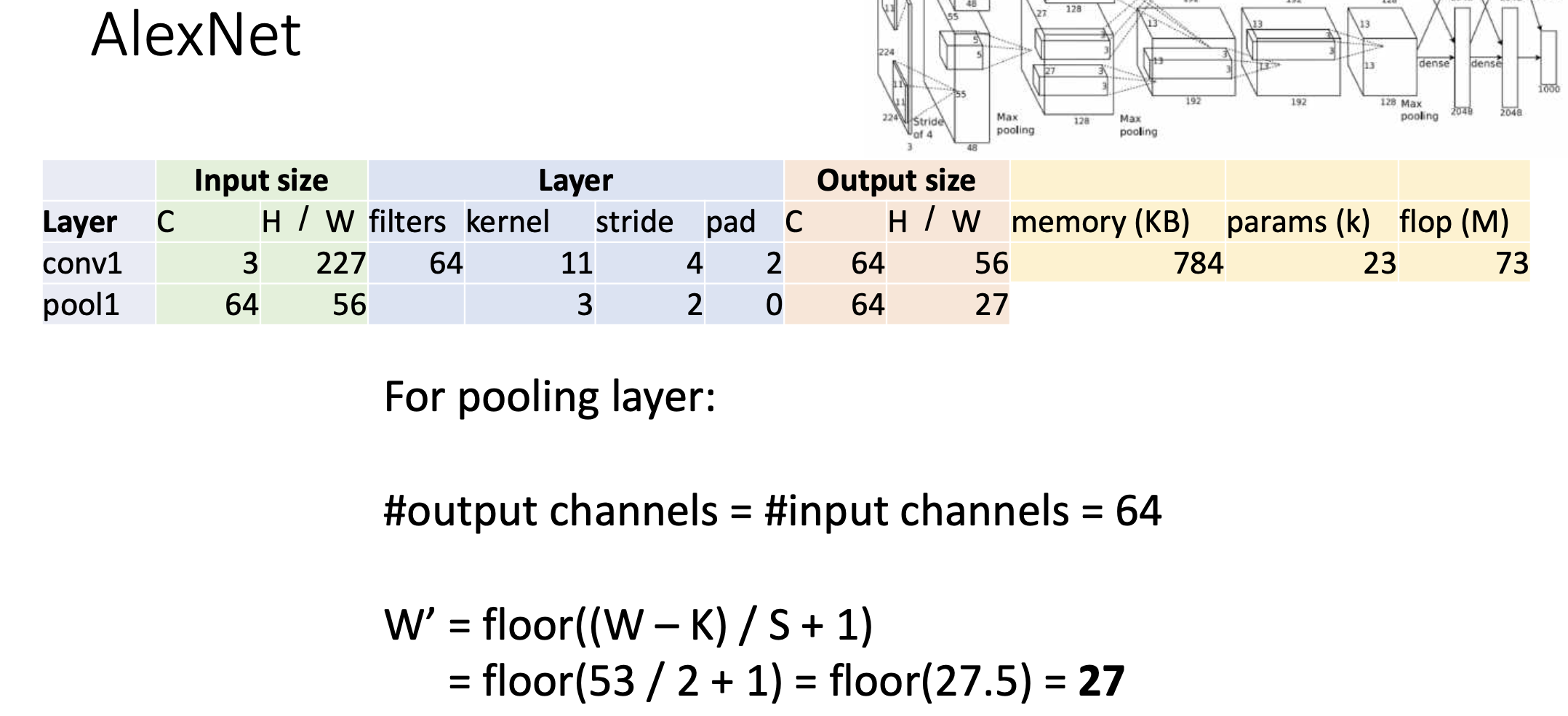
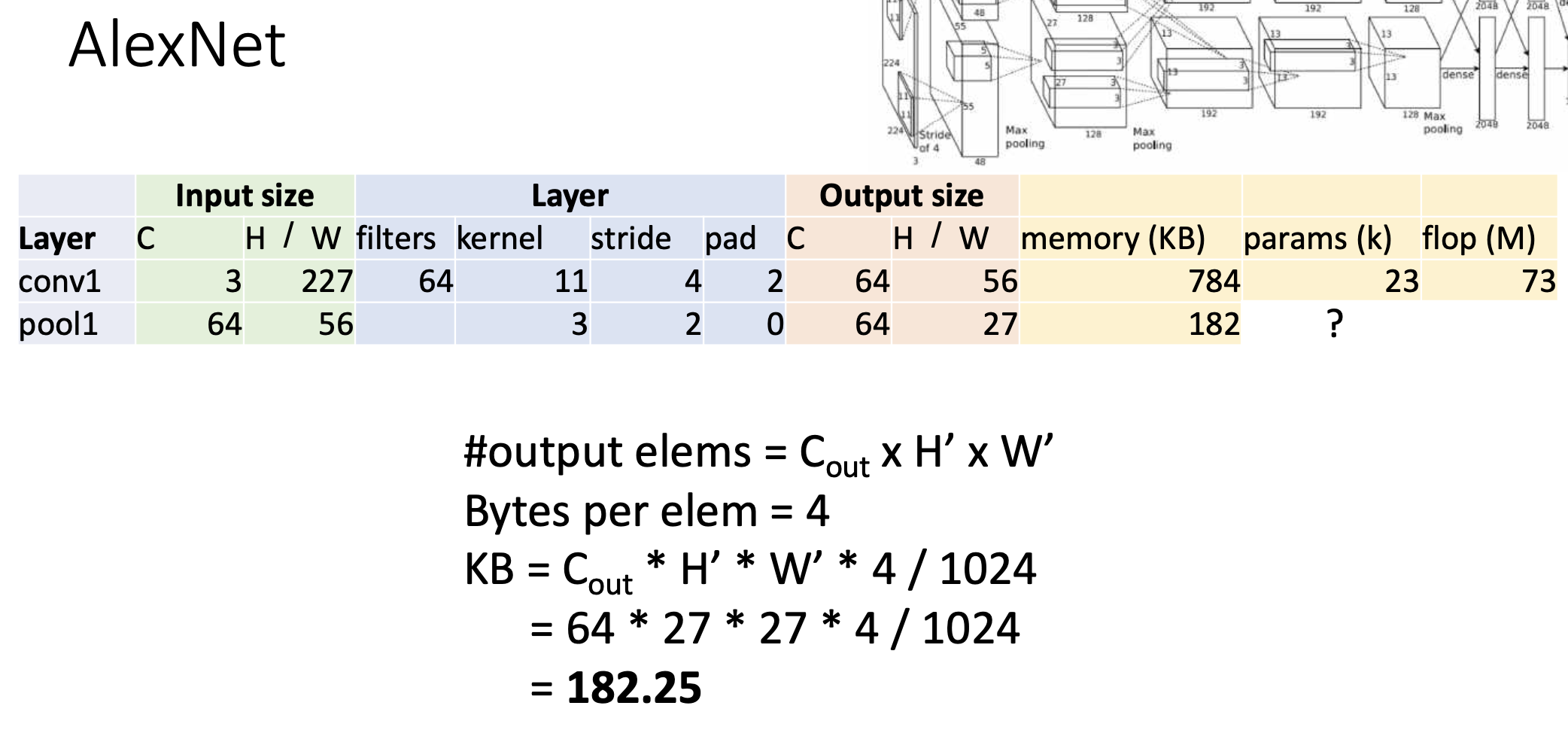
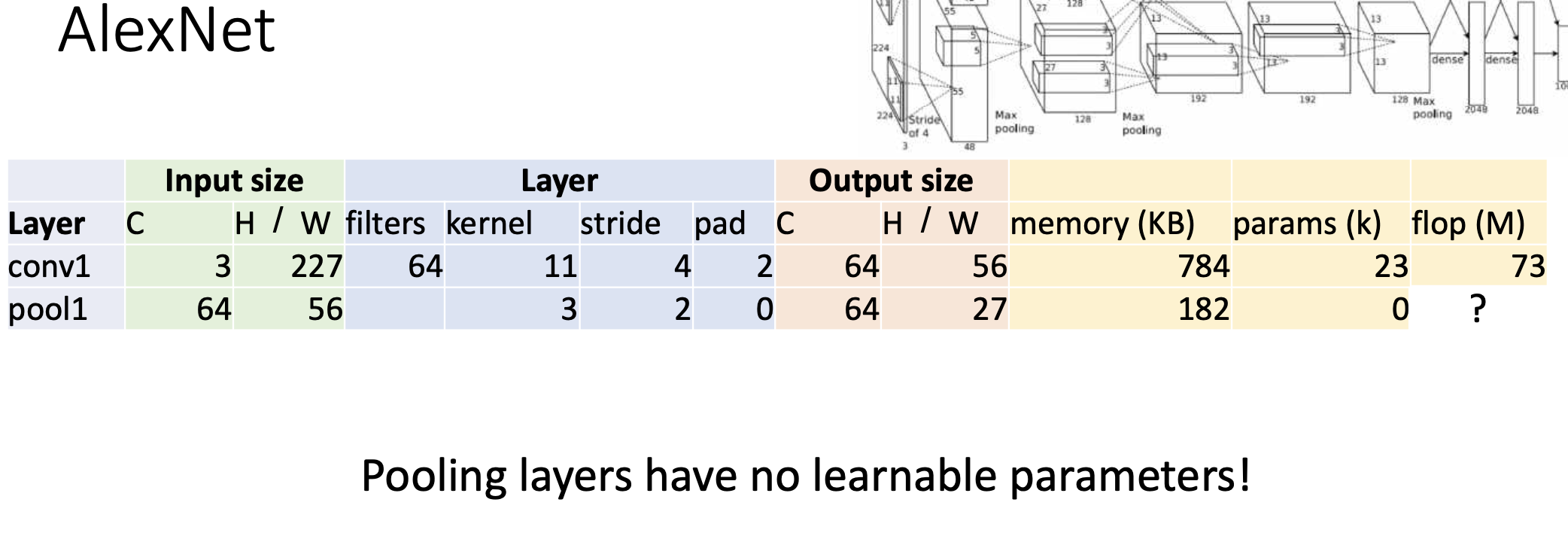
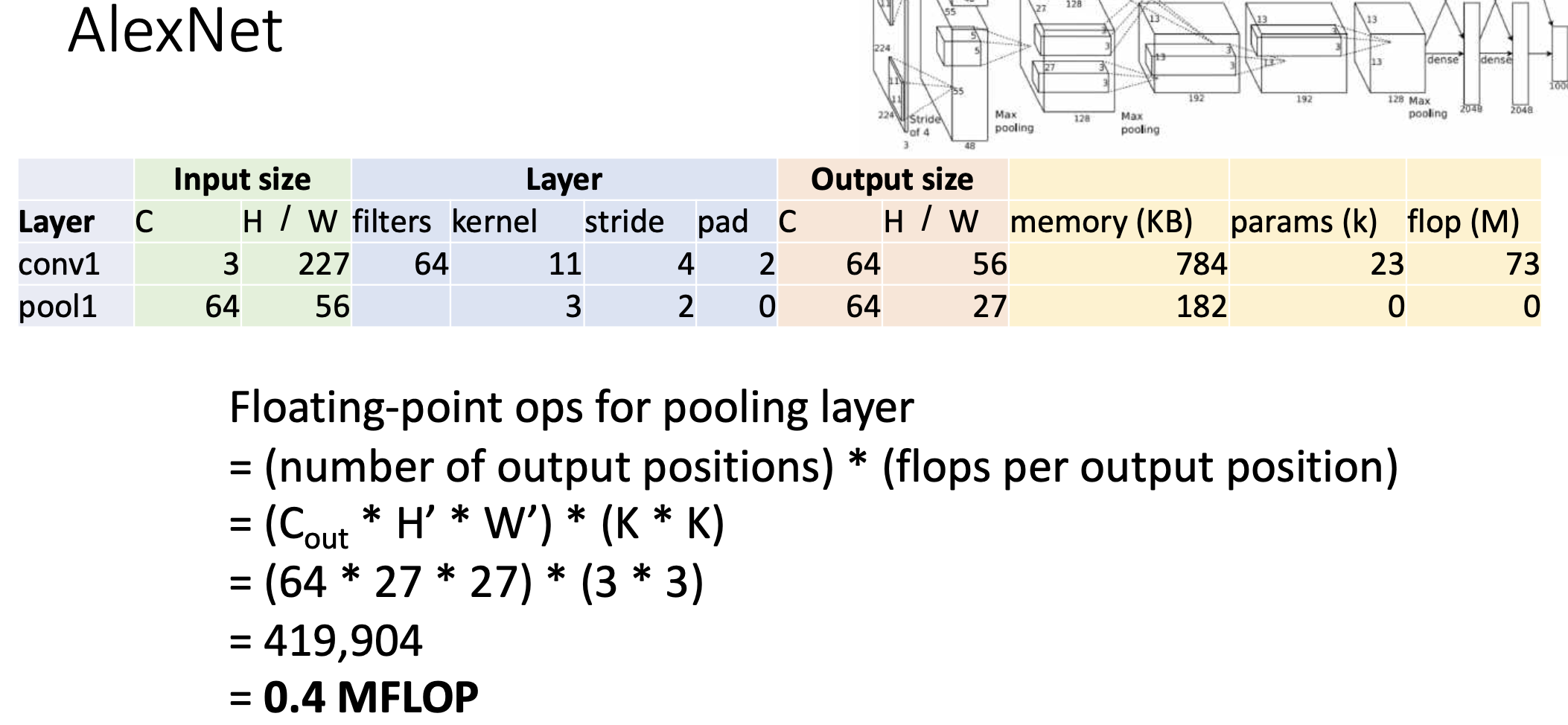
연산은 컨볼루션 레이어에 비해서 싸다. -
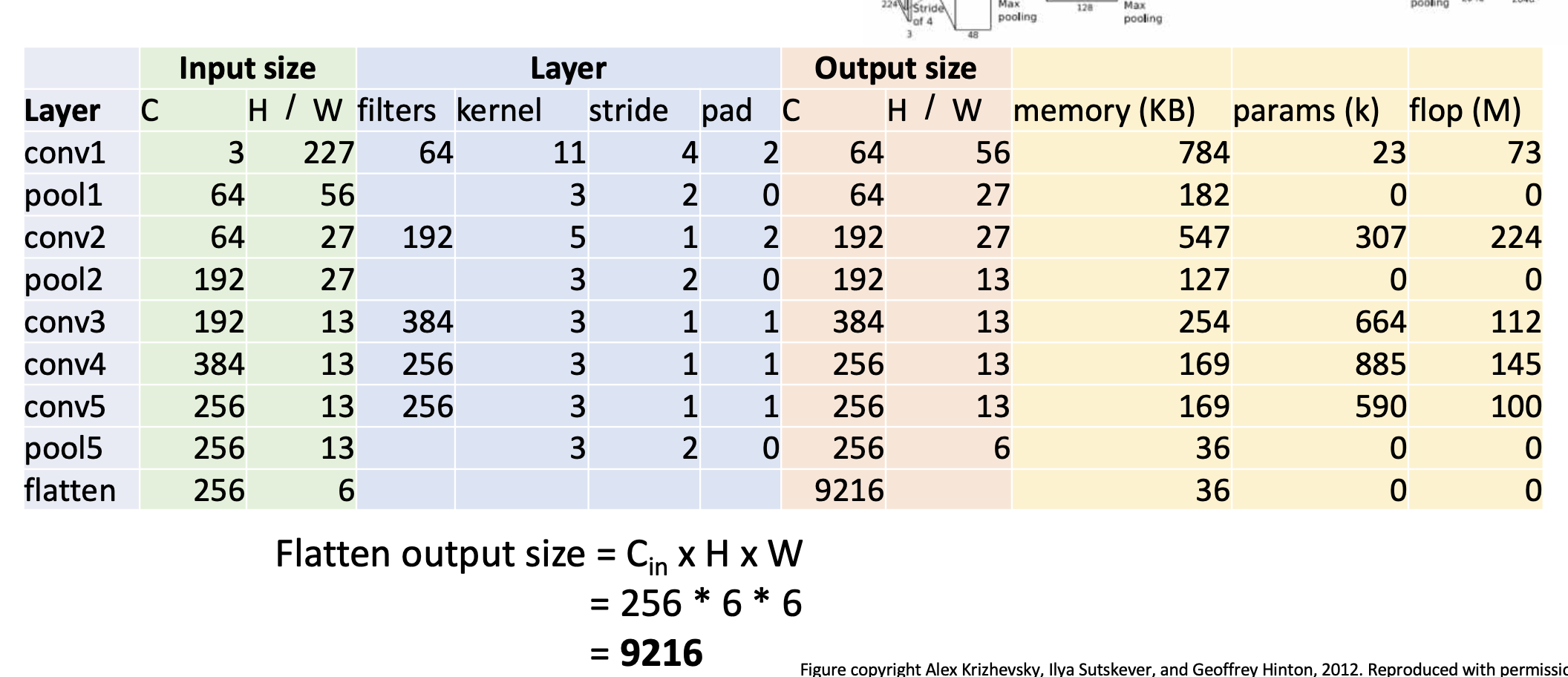
conv랑 pooling 5까지 하고 나서, fully connected layer와의 연결을 위해서 다 핌.(flatten). 5번째 pool하고 나서 Output은 256x6x6이었는데 공간적인 정보를 무시하고 일렬로 쫙 폈으니까 사이즈는 25666 = 9216이다.
-
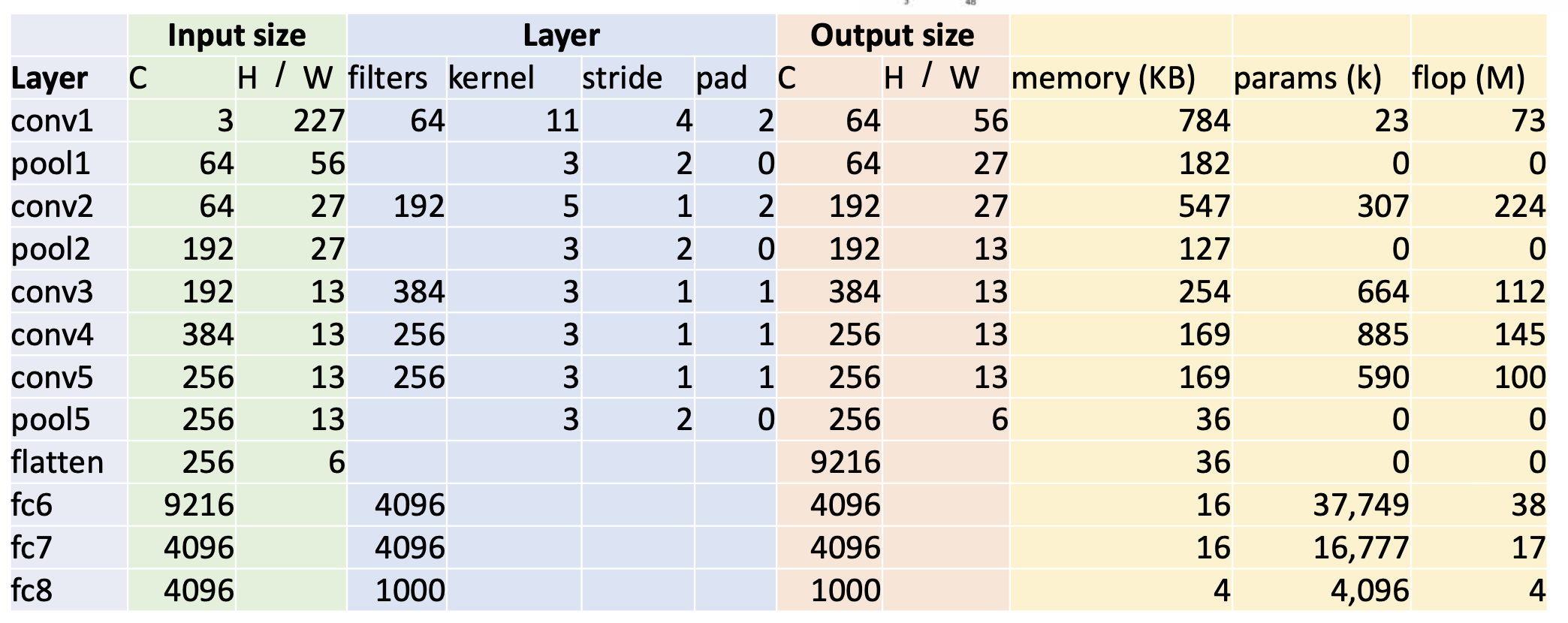
그 다음에 알레스넷이 전개 되는 것은 fully connected layer를 3번 끼얹는다. 첫번째 fully connected layer는 fc6이라고 붙은것임.
-
fc6, fc7, fc8 이렇게 fully connected layer 3번.
-
이 사람은 어떻게 이 구조를 생각했을까? 그냥 trial and error임. 강의 말미에 있겠지만 영웅이 되지 말아라. 사람들이 구현 한 1등한 구조를 따라해라 라고 되어잇음.
재미있는 트렌드
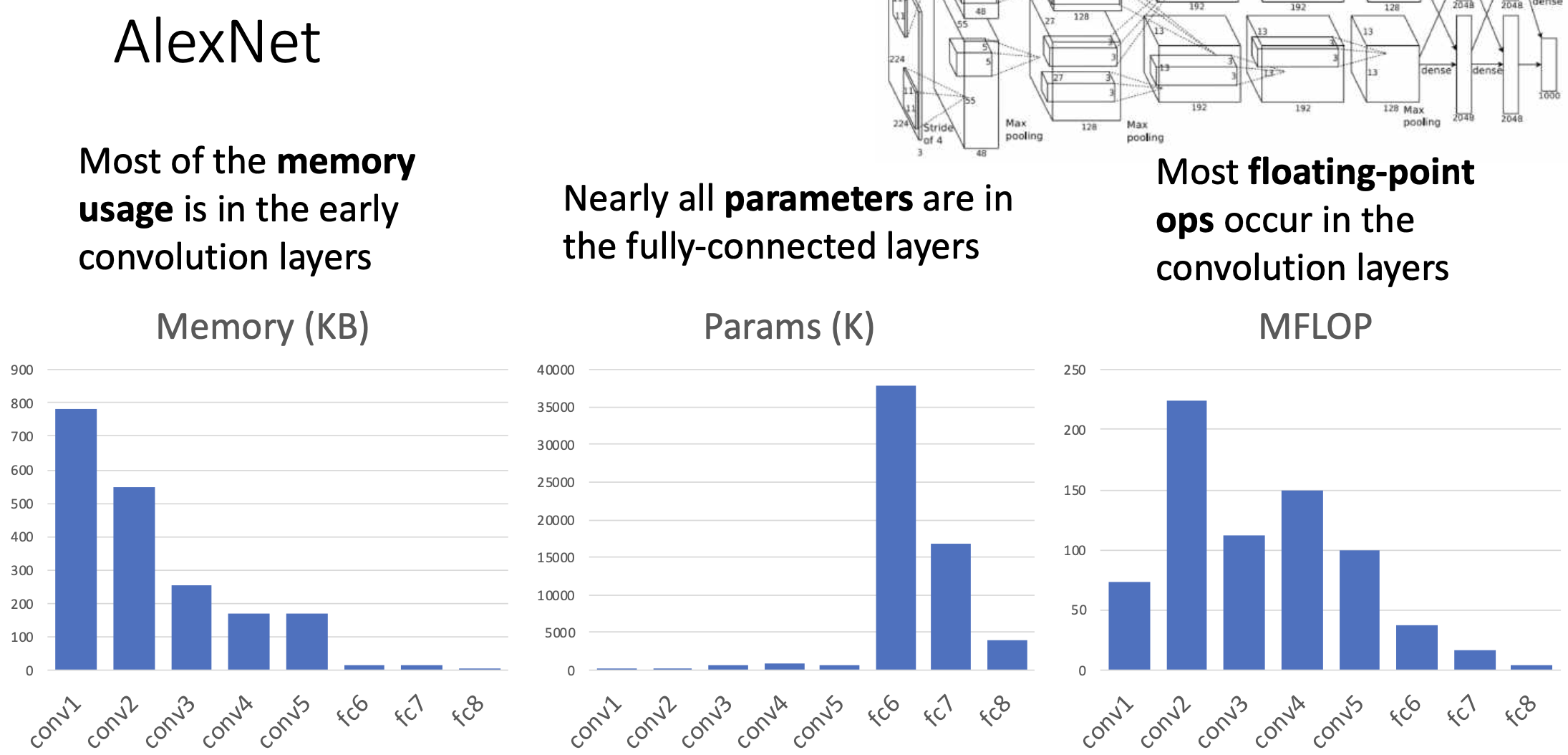
그래프를 보면 초기 컨볼루션 레이어에서 output에 차지하는 메모리가 많은데 이는 초기 인풋이나 보니 해상도가 높아서 메모리의 사용이 많은 것 같음. 그리고 파라미터 개수로 보면 컨볼루션 레이어에 비해서 fully connected layer가 배워야 되는 게 많음. 그리고 floating point operation으로 보면 convolution layer가 파라미터 개수가 적은 데 비해서 상당히 연산의 부담이 많이 일어남. 그러면 efficiency를 아끼려고 한다면 어떻게 할수 있을가? 컵볼루션 레이어에서… 아니면 풀리 커넥티드 레이어의 파라미터 개수를 줄일 수 있을까…
ZFNet : A Bigger AlexNet
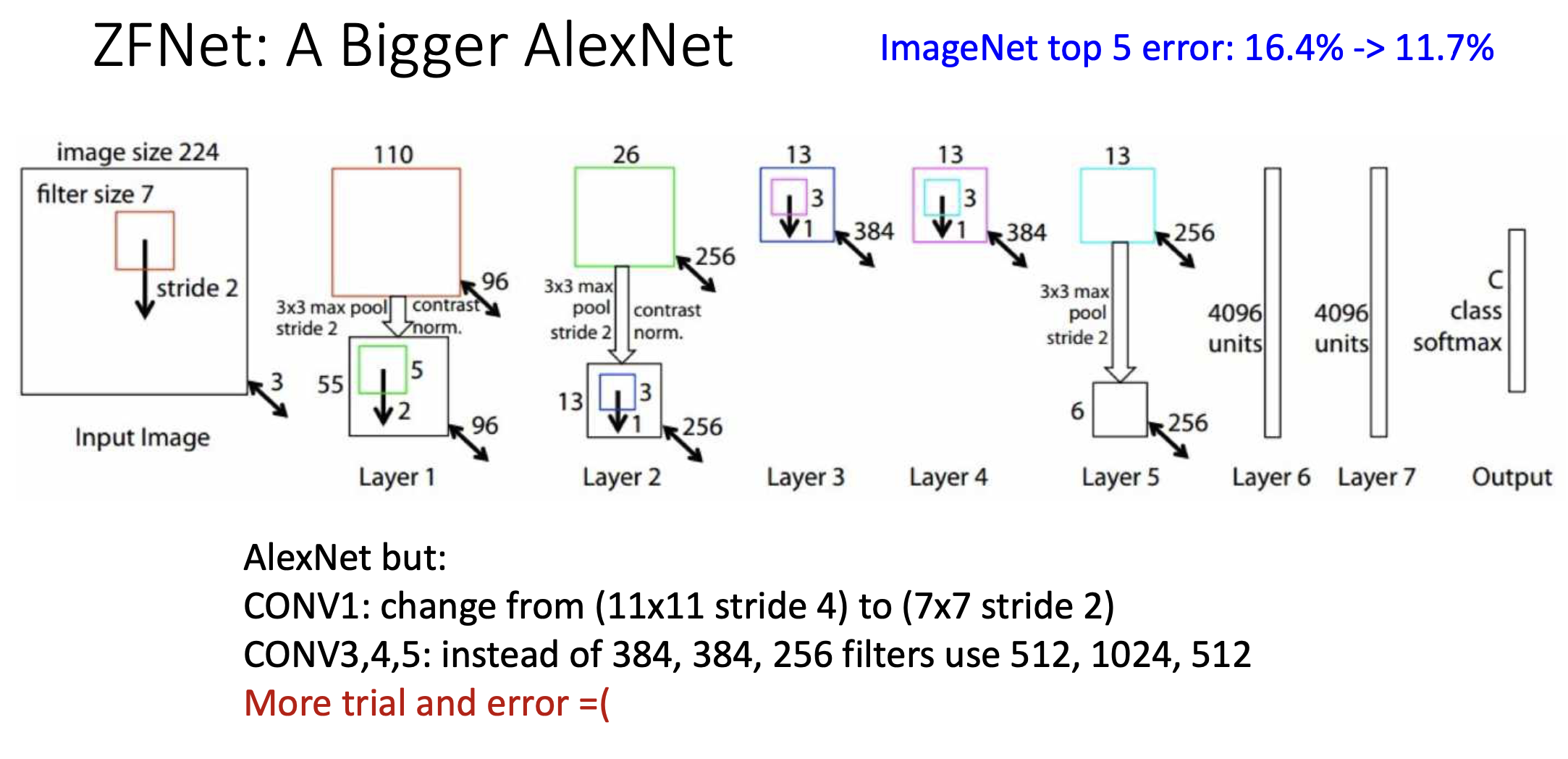
이 구조는 2013년에 일등을 한 구조이다. 이건 Alexnet에서 layer configuration을 고친 것. 첫번째 컨볼루션에서의 필터 사이즈를 7x7 stride 2 로 줄임. 스트라이드 수가 줄었으니까 다음 레이어가 좀 더 high resolution이 됨. 그 다음에 세번째, 네번재 5번째 컨볼루션 레이어에서 필터 개수가 늘어남. 그러면 해야되는 연산과 파라미터도 늘어남. 기본적으로 메모리 연산 측변에서 모두 커진 네트워크.
VGGNet(2014)
2014년에 레이어 8개에서 레이어 19개로 올라가고 accuracy는 4퍼센트정도 높아졌음. VGGNet은 CNN아키텍처 디자인 가이드를 주는 역할을 했음. 알렉스넷 이런건 트라이앤 에러로 살짝 근본이 없엇음.
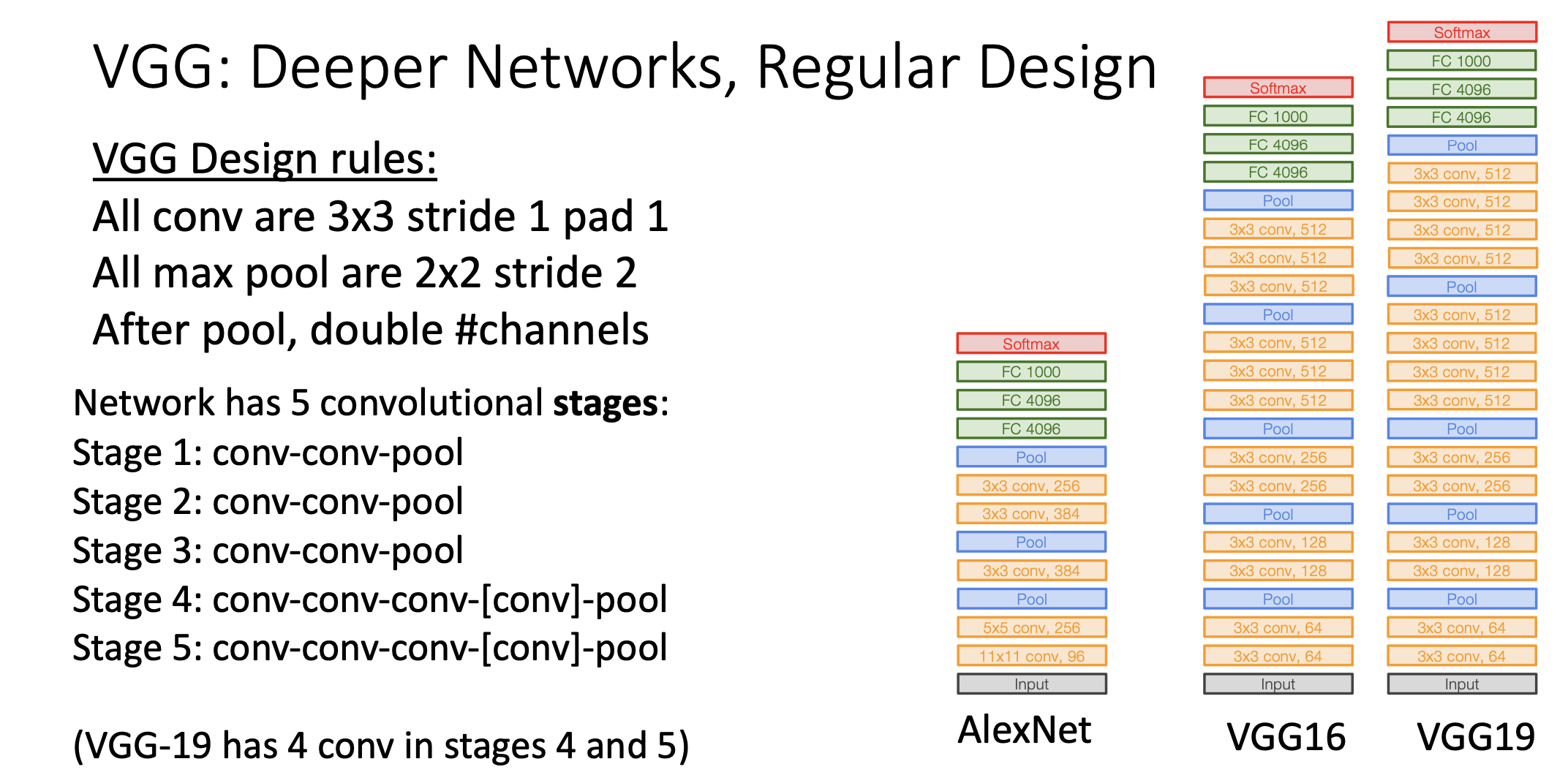
우선 5개의 스테이지로 이루어져있음. 먼저 Stage 1,2,3 에서는 conv-conv-pool로 이루어져 있고, stage 4,5에서는 convolution을 세번할수도 있고 네번할 수도 있다. Convolution 3번하면 레이어 16개 돼가지구 VGG-16이고 컨볼루션 4번하면 VGG-19라고 함.
Motivation
VGGNet의 모든 필터는 3x3, stride=1, pad=1.이다. 이러면 input과 output의 가로 세로 사이즈가 같아지게 됨. 이렇게 사용하게 된 motivation은 5x5로 input channel c개에서 output channel c개로 컨볼루션을 할때 (Conv(5x5,C->C)) 필터의 Parameter의 개수는 bias 빼고 25C^2이고 25C^2HW번의 부동소숫점 연산이 이루어진다.
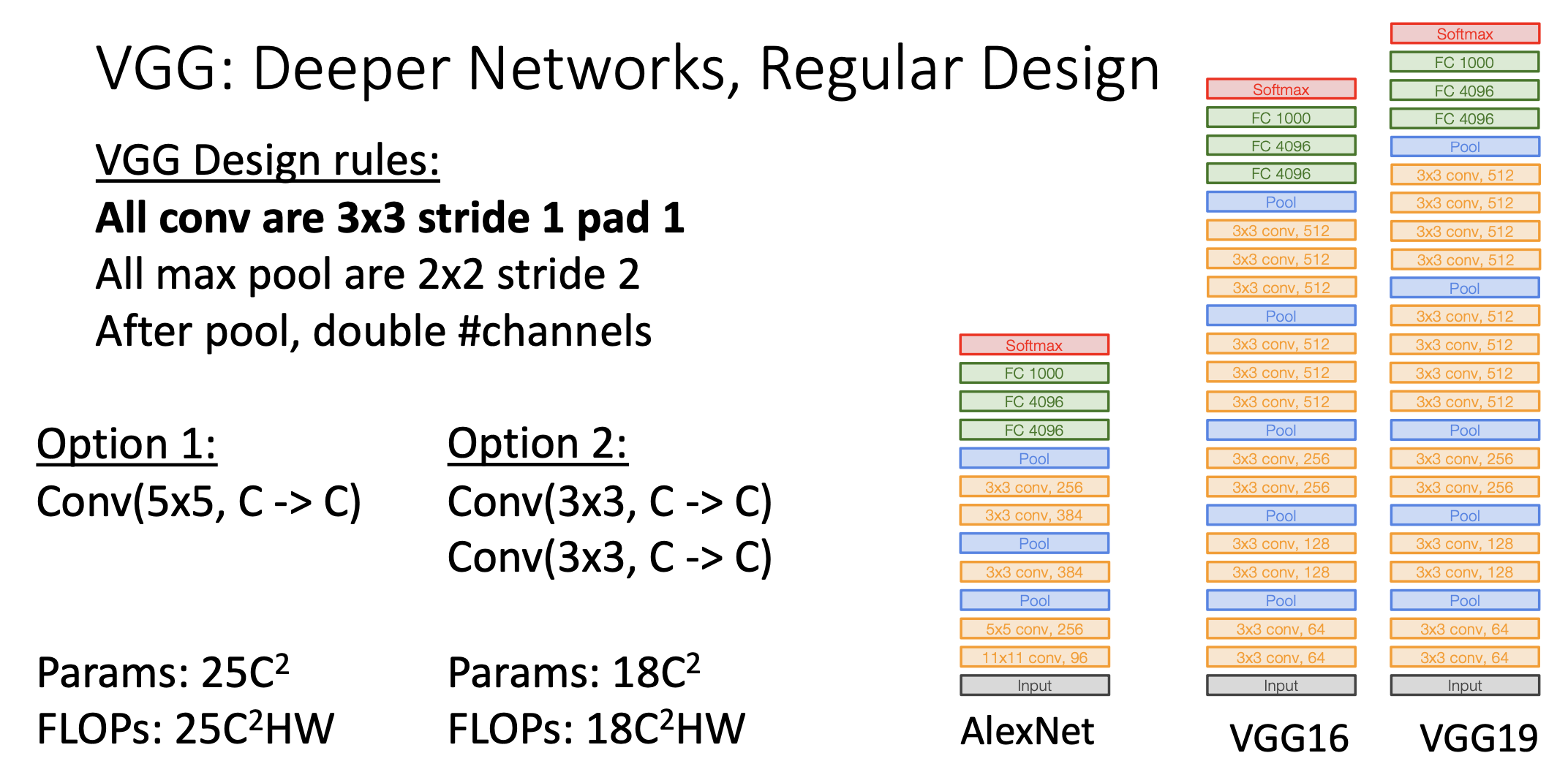
반면 2번째 option의 경우, 3x3필터를 2번 먹이면 파라미터의 개수가 18c^2이고 부동소숫점 연산 수도 18C^2HW이다.
잘 생각을 해보면 5x5 컨볼루션 한 것과 3x3 컨볼루션 두번 한 것 모두 output의 각 element에 대한 최초 input에서의 receptive field는 5x5으로 같다.
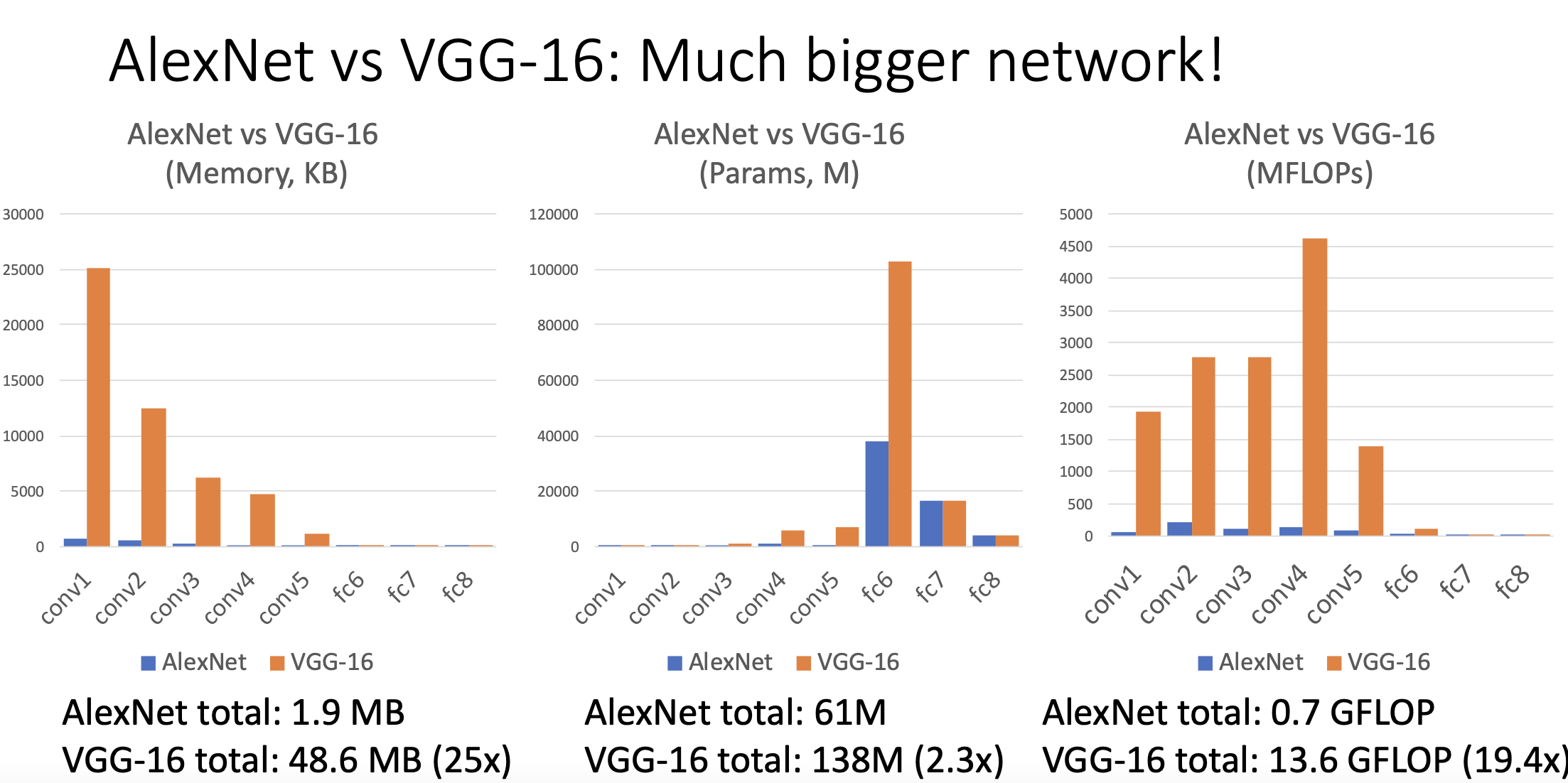
그러면 이전의 Neural Network구조와 비교하면 VGG16이 훨씬 큰 네트워크임.
GoogLeNet
GoogLeNet은 1998년에 LeNet을 Celebrate하기 위함도 있음. 2014년 VGGNet과 같은 해에 에러 레이트가 6.7%를 달성했음. GoogLeNet은 efficiency를 고민한 네트워크임. 계산 효율성을 생각했음.
구조
-
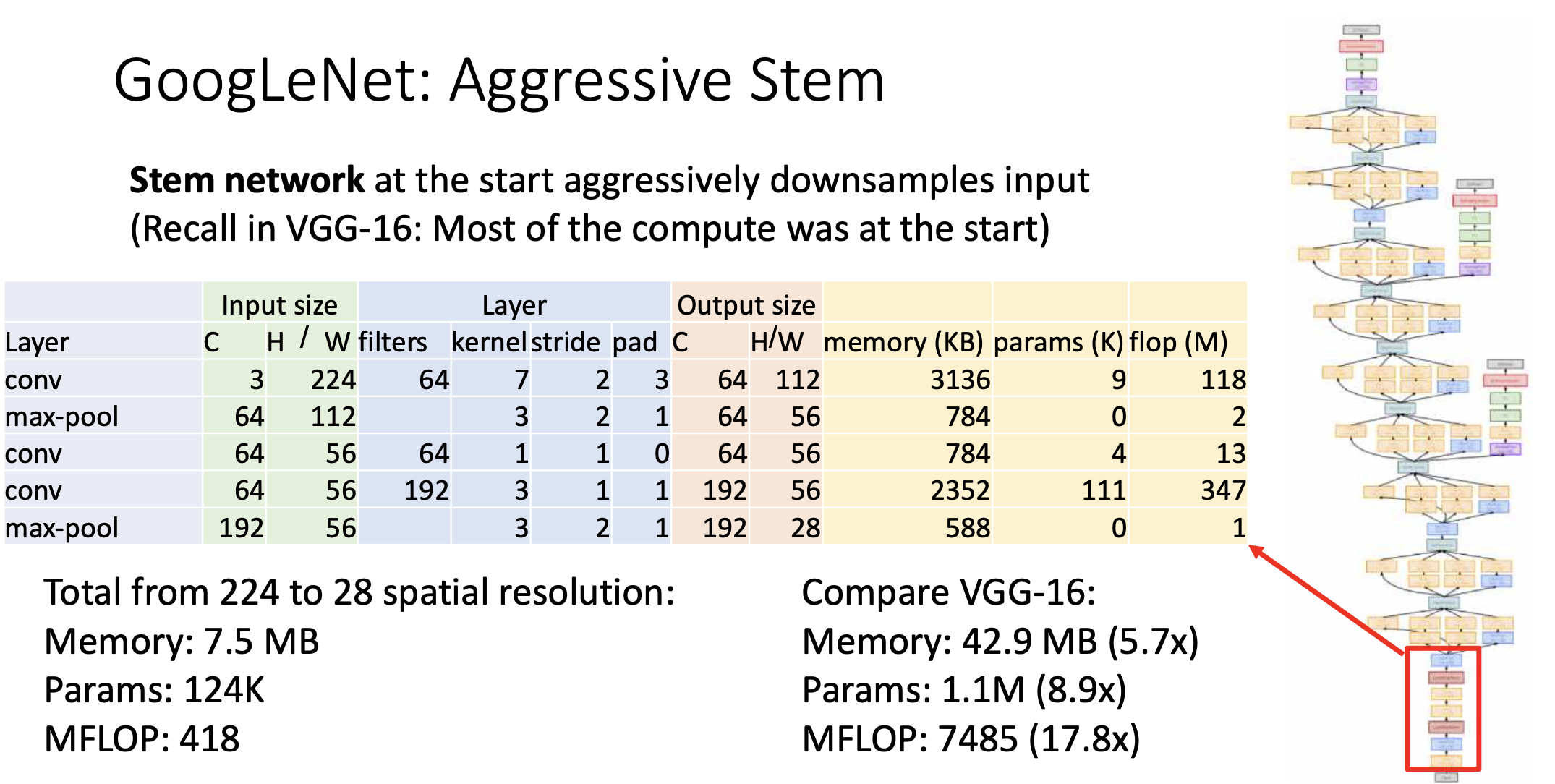
첫번째 부분은 고해상도의 컨볼루션을 먹여야 되다 보니까 그 연산을 낮추기 위해 최대한 빠르게 무작정 downsample을 했음. 위의 그림을 보면 224의 이미지에서 28x28로 내려가기 위해 단 세번의 convolution만 이용한다. VGGNet과 연산수로 비교해 보았을 때, 1/18 정도로 확 줄어들었음. 이게 첫번째 innovation임.
-
Inception Module
이 모듈의 previous layer에서 input이 들어오고, 4개의 branch로 연산이 된 다음에 벡터를 이어붙여서 하나 만들고 그걸 위로 올려보낸다. 이 structure를 반복한다.
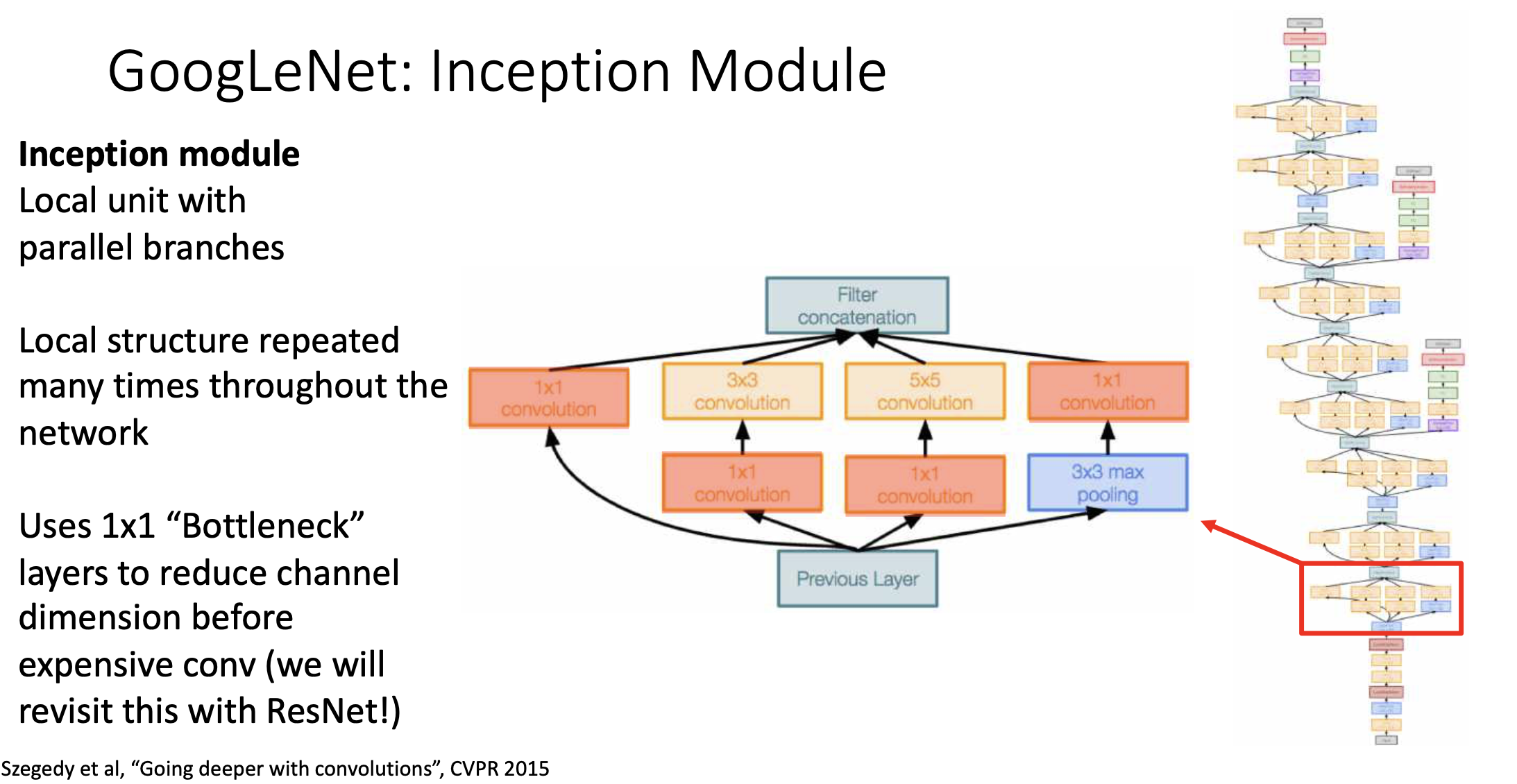
VGGNet에서는 어떤 필터를 써야 할지 고민이 될 때 3x3만 쓰면 된다 했음. 반면에 여기서는 4개로 보냄. 지난 시간에 얘기 했듯이 1x1 convolution은 픽셀별로 fully connected layer를 한번 돌린것과 같은 효과가 있어서 픽셀별로 약간의 프로세싱(Non-Linearity)를 줄 수 있는 방법임. 1x1 convolution을 보통 bottleneck layer라고 부르기도 함. 결과를 이어붙이는게 2번째 innovation임. -
세번째 innovation은 inception module에 1x1 컨볼루션을 사용한다는 것임. 값싼 1x1 컨볼루션 사용
-
Fully connected Layer를 쌓을수록 엄청나게 많은 개수의 learnable Parameter가 나오는데 Googlenet은 그래서 Fully connected layer를 거의 안쓰고 Global average Pooling을 써서 Fully connected layer로 들어갈 때의 variable개수를 최대한 줄여버림.
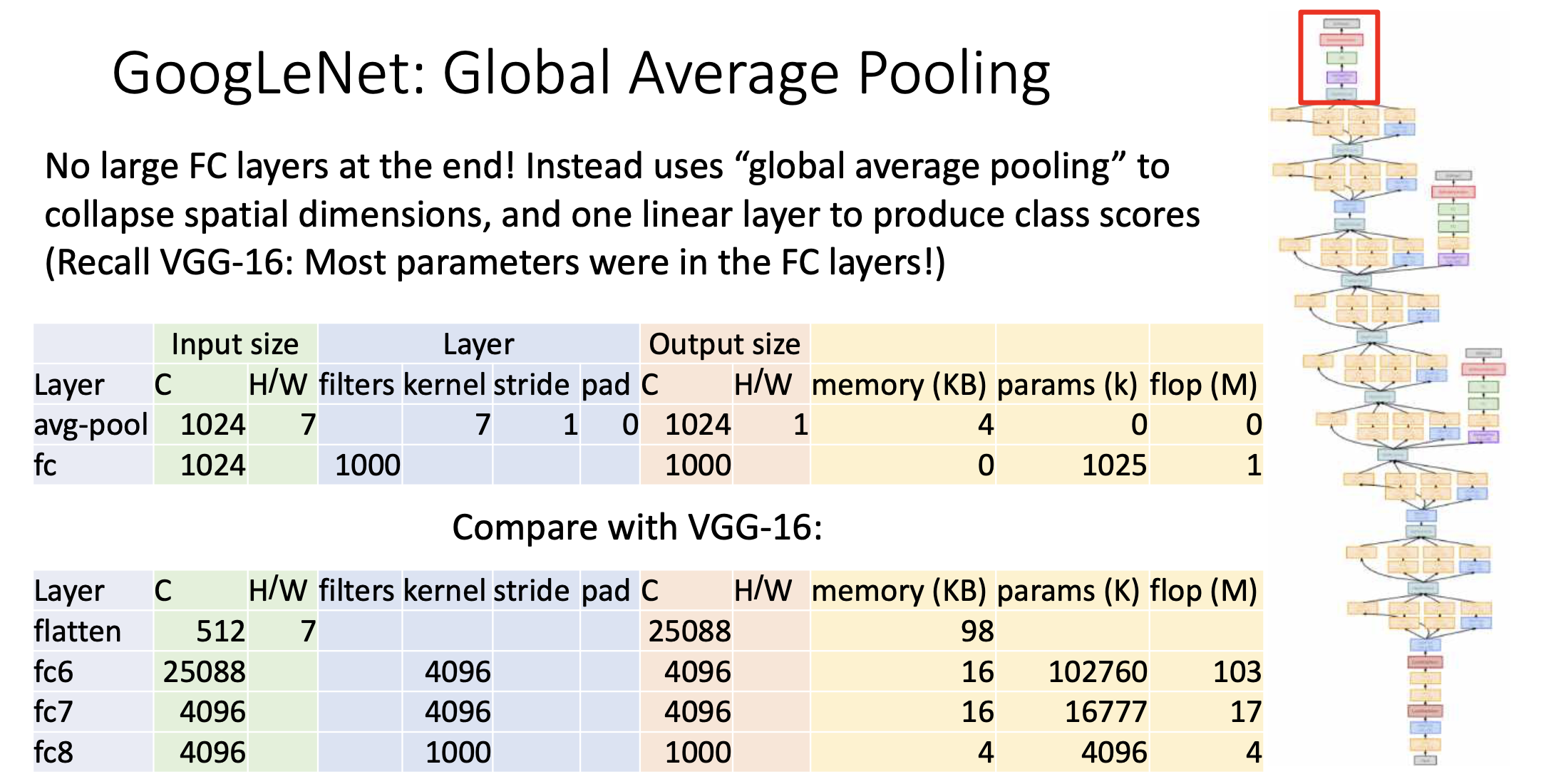
위의 그림에서 볼 수 있듯이 Average Pool을 7x7 convolution을 이용해서 한다. 그러면 output size가 1024x1x1이 나옴. 거기에 fully connected layer를 단 한번만 씌움. 그러면 fully connected layer에 사용되는 Parameter가 1024*1000개 정도 밖에 안됨. 그래서 Vgg-16과 비교하면 확 줄음. -
(이건 Innovation이라기 보다 좀 이상한거.) 구글넷은 batch normalization이전에 나와서 deep한 네트워크 트레이닝이 어려웠음. 이 당시에는 10개의 레이어 보다 깊은 네트워크를 훈련하고 싶으면 못생긴 해킹(?) 같은게 필요했음. 중간중간에 계산 결과를 빼내서 Loss term에 contribute하도록 시킴. 그래서 빨간색 두개에서 나오는 로스 value랑 맨위의 loss value 더해서 로스 계산하고 걔를 미분해서 Stochastic Gradient Descent로 파라미터 전체를 업데이트 했음. 직관적으로 로스를 빼냄으로써 중간중간 레이어에 Backpropagation으로 Gradient를 주입한다고 생각할 수 있음. 그래서 일반적으로 레이어를 많이 쌓았을때 밑에 있는 레이어들의 그래디언트가 백프로파게이션 과정에서 optimization문제가 생겨서 gradient업데이트가 잘 안되는 문제가 생겼는데 Auxiliary classifier loss function을 주입함으로써 아래단계까지 Gradient가 잘 propagate되길 바랬음.

그러나 이제는 batch normalization이 있기 때문에 빨간색 상자 같은 트릭은 사용하지 않음. VGGNet도 지금 보면 이상한 해킹 테크닉을 사용했음. 이를테면 맨처음엔 7개의 layer로 트레이닝하고 중간중간 레이어 끼워넣어서 다시 트레이닝함.
ResNet
Residual Network
Batch Normalization 이후에 10개 이상의 layer를 우리는 학습시킬 수 있었음. 근데 더 깊은 레이어를 쌓으면 무슨 일이 일어날까. 일반적인 우리의 생각은 optimization만 잘 된다면 층이 많아진다고 해서 나빠질건 없음. 레이어 많다고 해도 identitiy 처럼 취급되면 적은 수의 레이어와 비슷하니까. 층을 많이 쌓은 모델이 층을 적게 쌓은 모델을 포함하는 개념이라고 사람들을 생각함. 그렇지만 그렇지 않음!!
Batch Nomalization했음에도 불구하고 여전히 깊은 모델은 레이어 적은 모델보다 성능이 안좋았음.

그래서 사람들은 깊은 모델이 너무 많이 배워 버린 것이 아닐까 생각했음. 근데 Resnet의 1저자가 실험을 해봤더니 오버피팅의 문제가 아니었음. 심지어 Training 에서도 error가 깊은 네트워크에서 더 높았음. 즉 트레이닝 자체가 잘 안된 것.

그래서 레이어가 너무 많아지면 underfitting 문제가 일어남. 아까도 얘기 했지만 깊은 모델은 더 얕은 모델을 재현할 수 있다고 사람들은 기대함. 근데 training 자체에도 문제가 있었음. Identity 조차 쉽게 배우지 못함. 그래서 아 이건 optimization의 문제다! 깨달음.

그래서 1저작 내놓은 해법은 네트워크를 조금 손봄. 아무리 깊은 네트워크라고 해도 Identitiy function을 더 쉽게 잘 배울 수 있도록함.
Solution
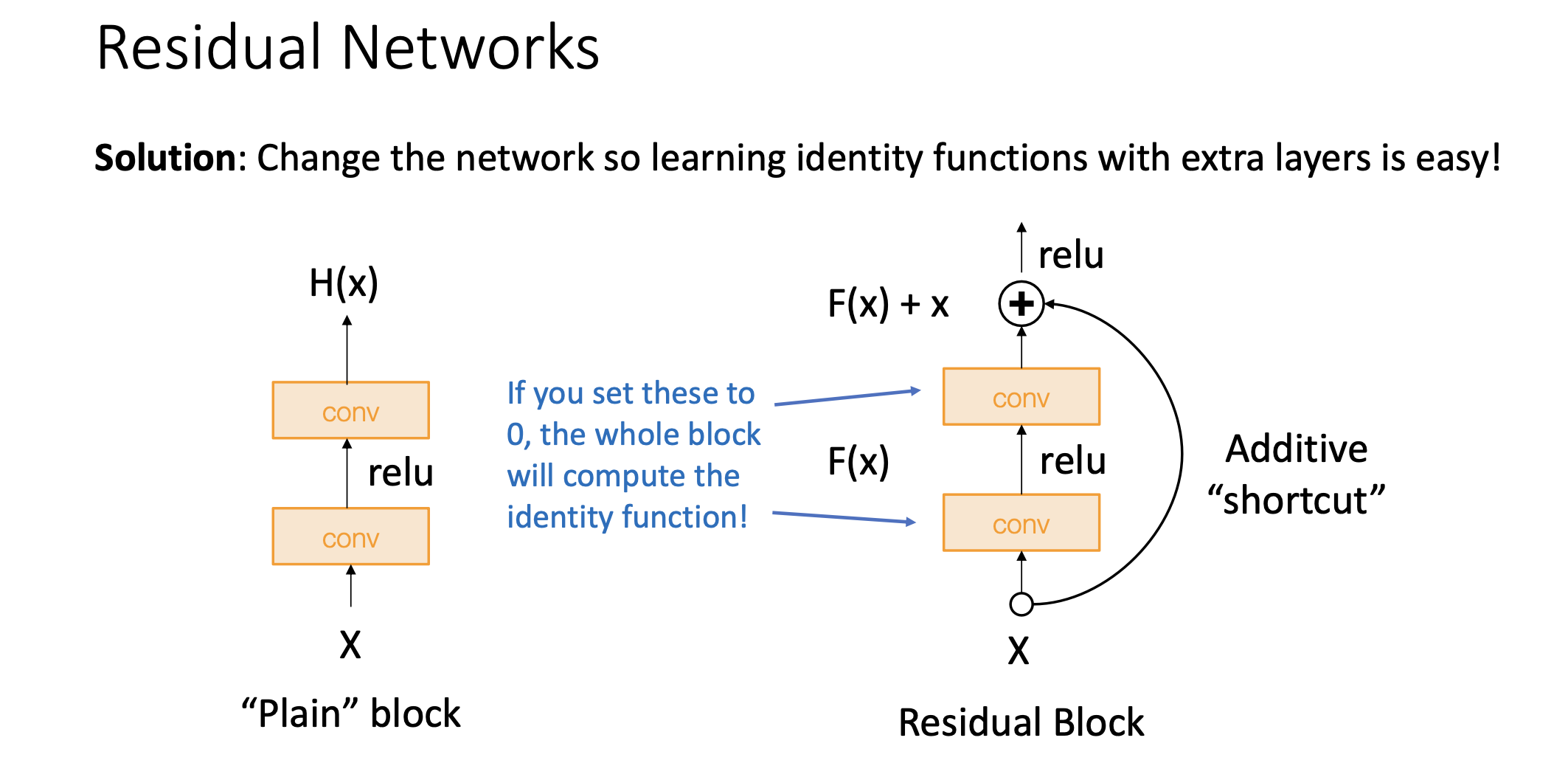
Residual block은 컨볼루션 두 번하고 중간에 렐루 씌우는 건 똑같음. 거기에다가 무엇을 끼워두냐면 인풋 X를 똑같이 더해서 F(x)에다가 X를 더한 것을 뒷단 레이어로 보내게 됨. 이게 resnet이 제안한 네트워크의 모듈 구조임. 이러면 identity function은 어떻게 배울수 있냐면 두개의 convolution layer들을 0로 설정하면 두개의 레이어는 무시되고 밑에 있는 레이어가 그대로 위로 올라가게 됨.
Computational Graph관점에서 얘기를 해보자면 더하기 노드는 Upstream gradient가 내려왔을때 똑같이 카피해서 downstream 각각으로 gradient를 쏘게됨. 이러면 위에서 바로 그래디언트를 쏴주기 때문에 중간 단계에서 gradient가 사라질수 있는 문제(Gradient Vanishing)를 어느정도 경감시킬 수 있음.
그래서 Residual Network라는 것은 이 Residual Block을 여러차례 쌓아서 이루어진 네트워크 구조를 일컫는다. Resnet도 VGGNet처럼 디자인 가이드를 제공한다. 레즈넷 블락 하나하나는 3x3 convolution이 2개로 이루어져 있고 아래 그림에서 색깔로 표시되어 있듯 여러개의 stage로 구성되어 있다.
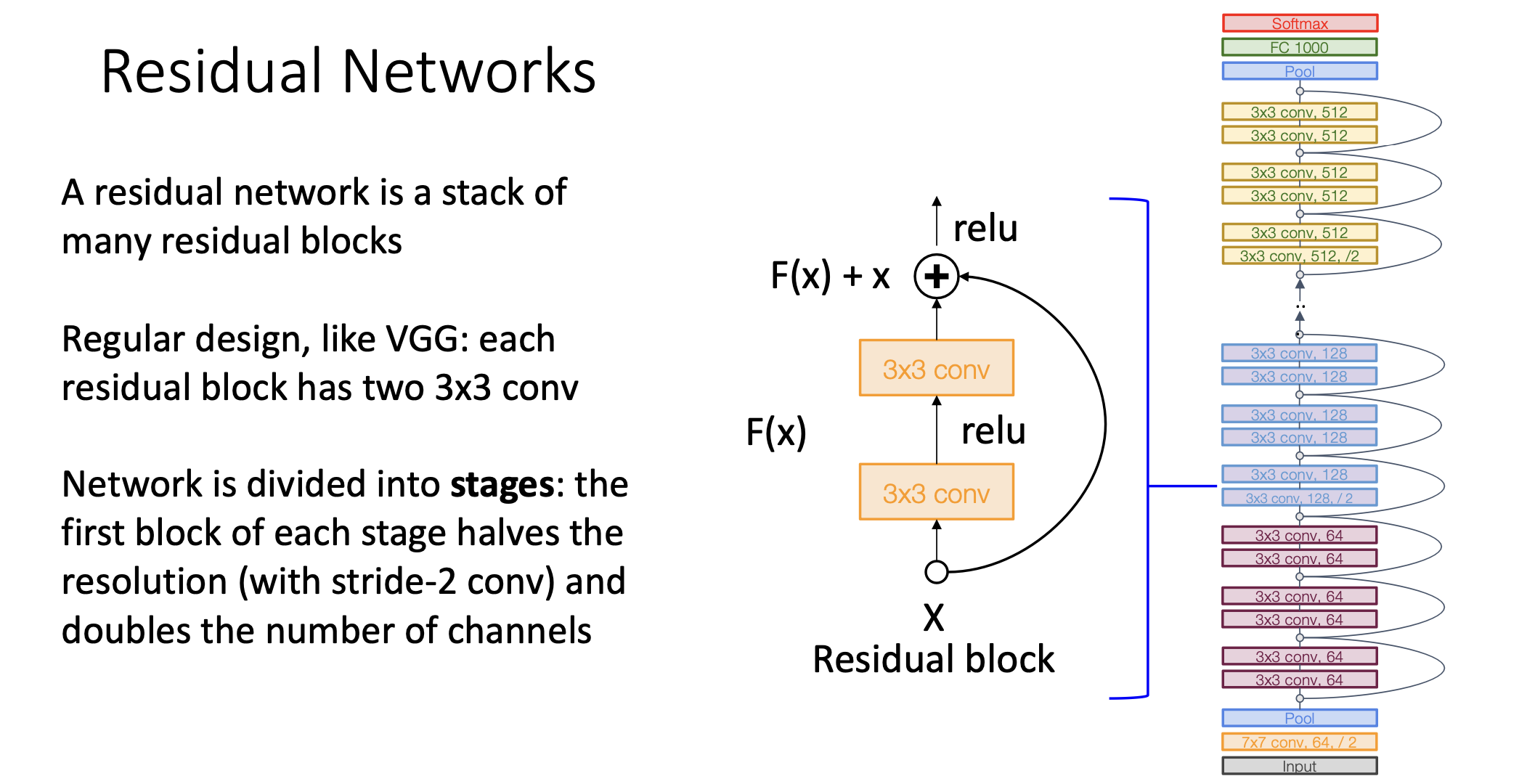
같은 색깔로 그려진 각각의 스테이지가 시작될 때 ./2가 적혀있는데 이게 뭐냐면 스테이지가 시작할때 stride가 2짜리 convolution을 이용함으로써 1/2로 다운 샘플링을 하고 그 다음에 채널을 두배로 뻥튀기 함. 그리고 구글넷에서처럼 Residual block에 들어가기 전에 매우 빠르게 downsampling을 시킴. 그래서 아래 그림처럼 224x224 이미지가 56x56으로 매우 빠르게 줄어든다.

그럼으로서 네트워크 초반에 고해상도 이미지에서의 부동소숫점 연산이 경감된다.
그리고 구글넷처럼 맨 윗단의 fullt connected layer의 구조를 적게 가져간다. 똑같이 global average pooling을 써서 맨 윗단에서의 parameter 개수가 너무 많아지는 문제를 경감시킴.

정리를 해보자면 많이 사용되는 구조가 ResNet-18이다.

더 깊게 쌓으면 ResNet-34로 위와 같다. 비슷한 VGG-16과 비교를 해보면 error rate은 적은데 계산 시간은 4배정도 경감이 되었음.
Bottleneck Block
혁신은 끝나지 않고 Bottleneck Block이란 것을 제안함.

중간에 3x3 컨볼루션을 냅두고 그 위아래에 1x1 컨볼루션을 하고, 채널은 4배로 증폭시키는 네트워크를 만듬. 이렇게 했을때 Totla FLOPs는 17HWC^2이 된다.
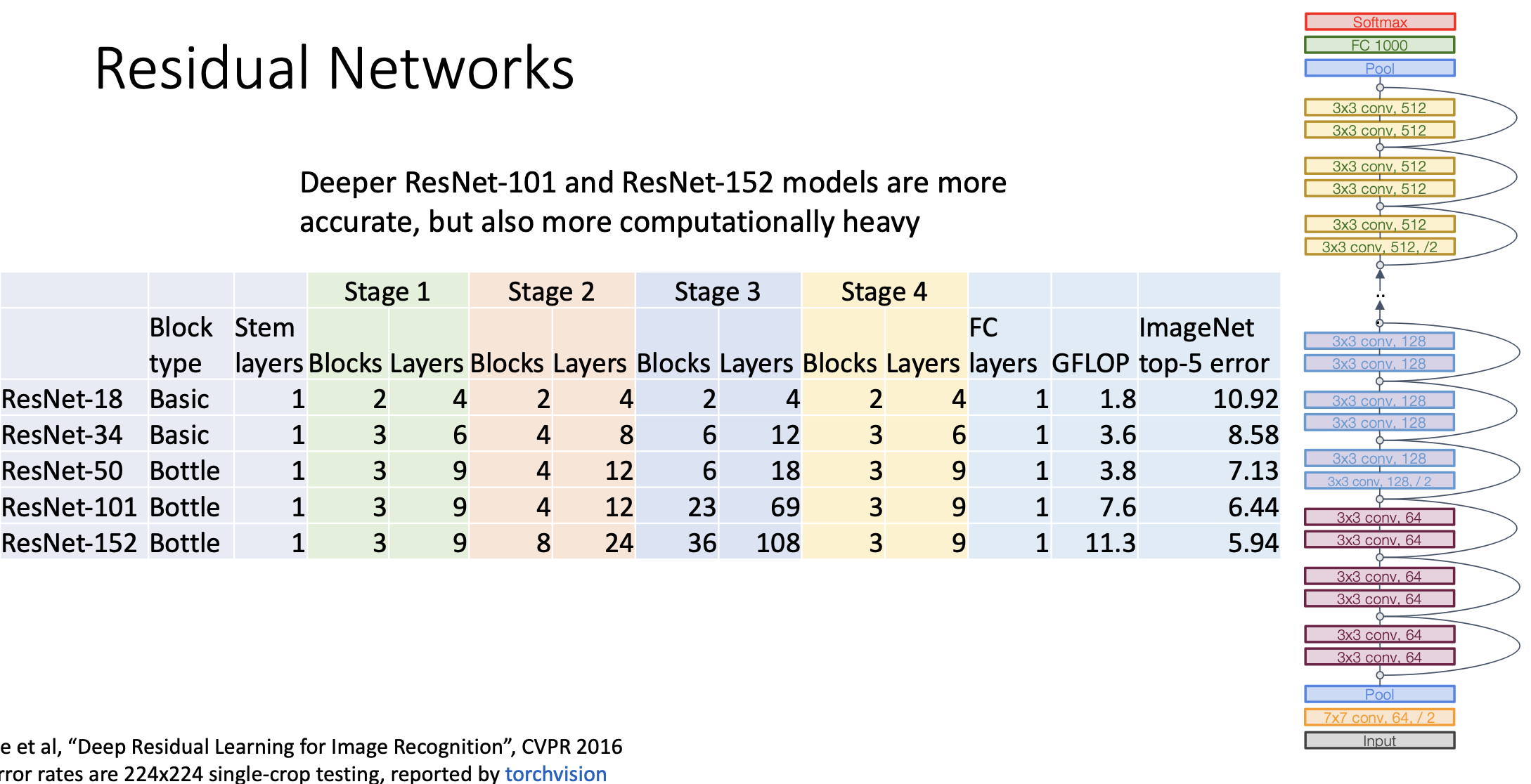
보틀넥 구조가 아직까지도 많이 사용됨.
ResNet Block의 개선 시도

블럭 operation 순서를 바꿈. 왼쪽은 conv-Batch-ReLu-Conv-Batch하고 나서 오리지널이랑 더하고 나서 렐루 씌움. 이러면 윗단 레이어의 입장에서는 Positive값만 들어오게 됨. 그래서 이사람이 생각한 문제점은 Identity function을 제대로 배울수가 없다는 것임. 왜냐면 output은 다음 블락의 input이 될텐데 이게 non negative되가지고 이게 잘 배울수 있을까라는 문제의식을 갖고 오른쪽 처럼 개선함. 그런데 큰 차이는 없음. Practice에서는 많이 쓰이지 않음.
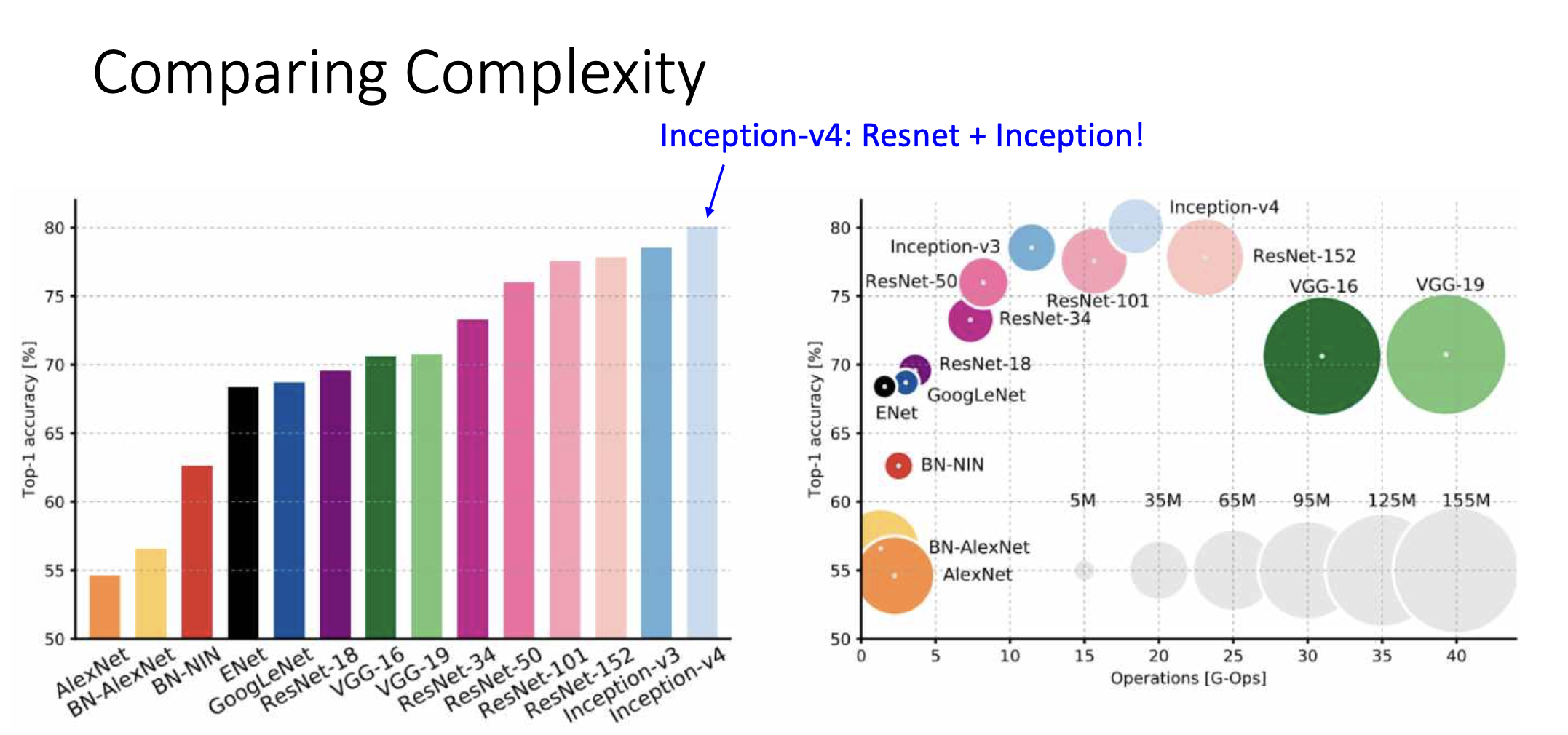
Comparing Complexity
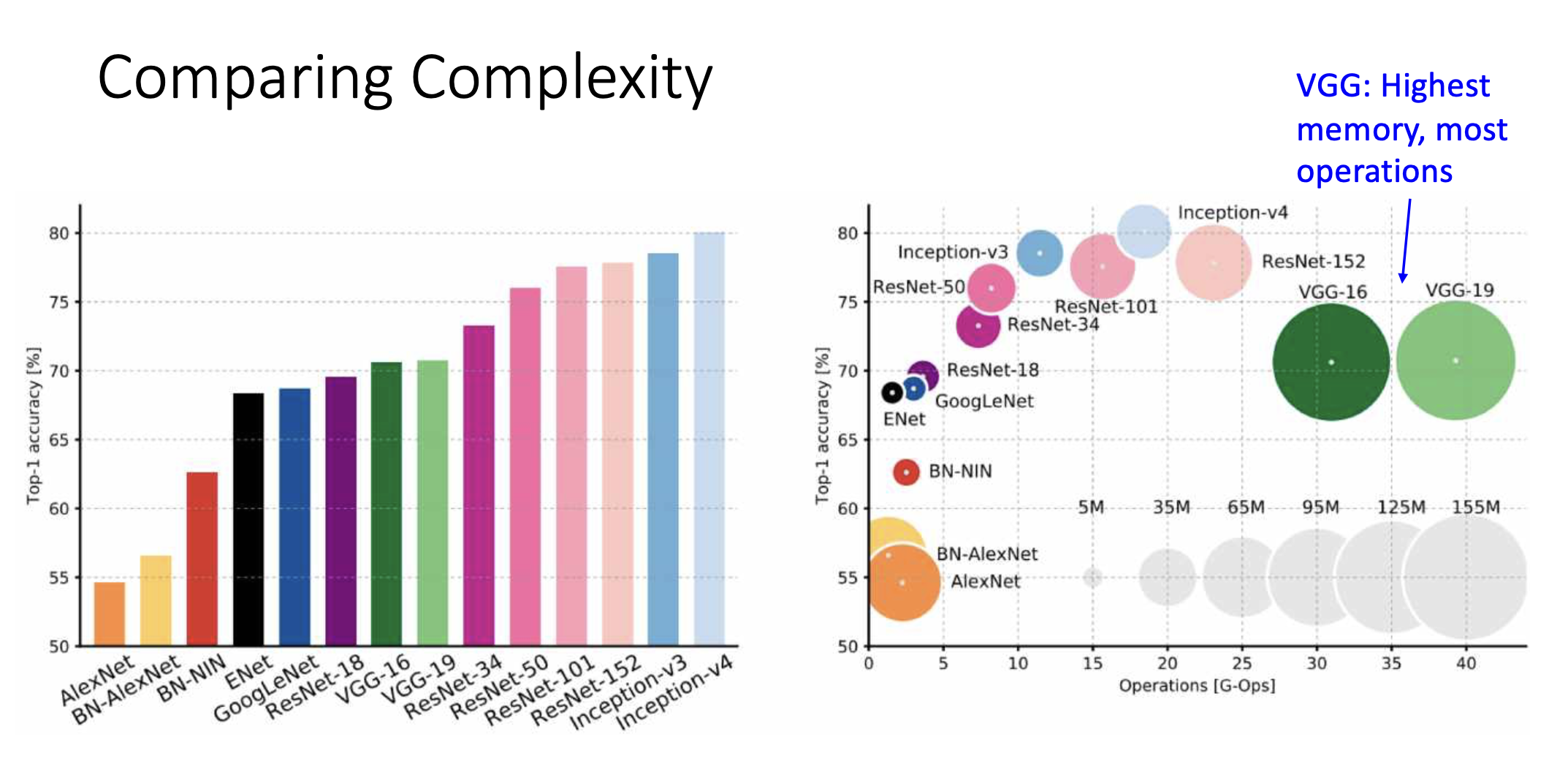
Improving ResNets
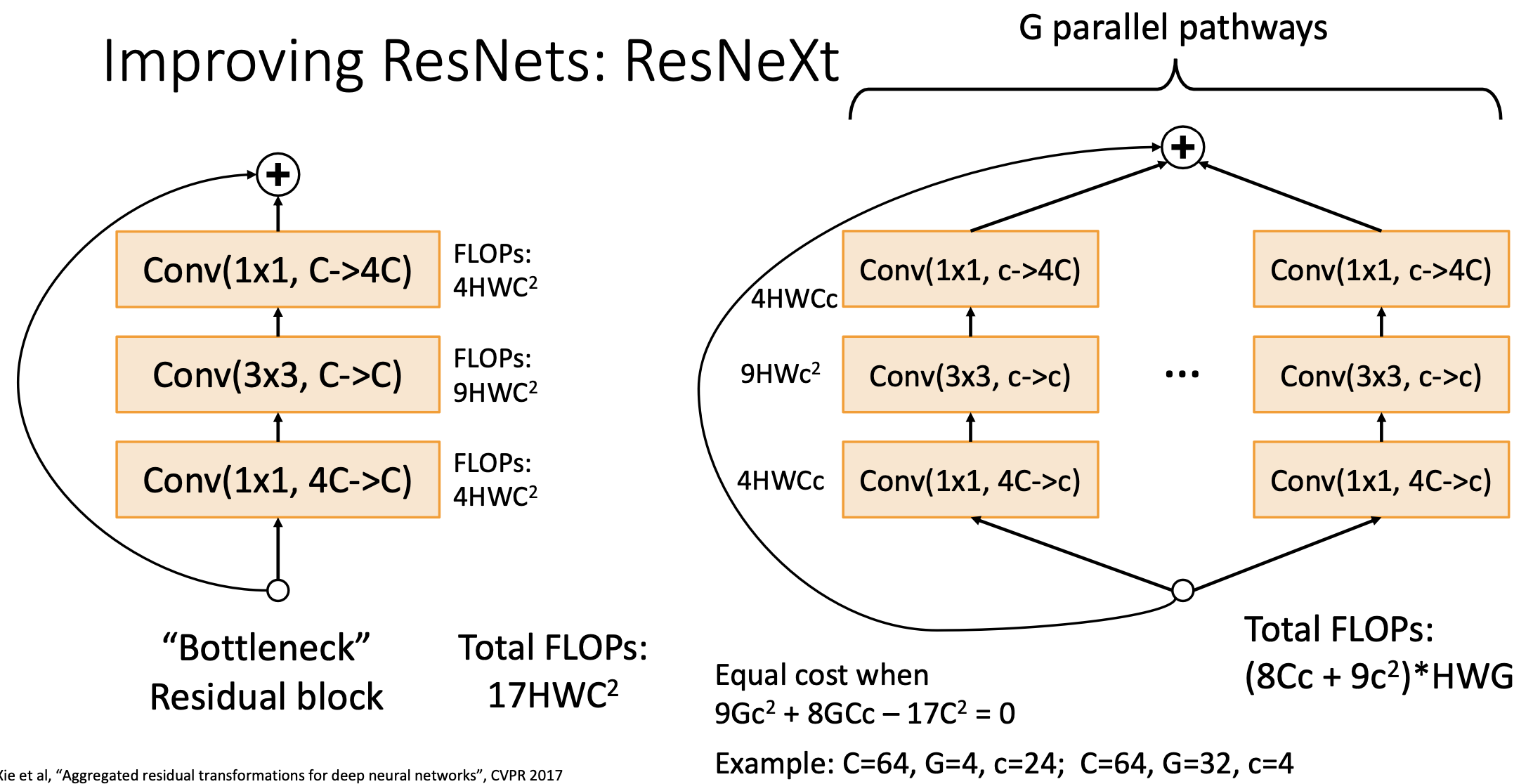
Inception 모듈처럼 병렬적으로 연결함. 위의 그림에서 나온 거 같이 방정식 풀어서 해를 구함.
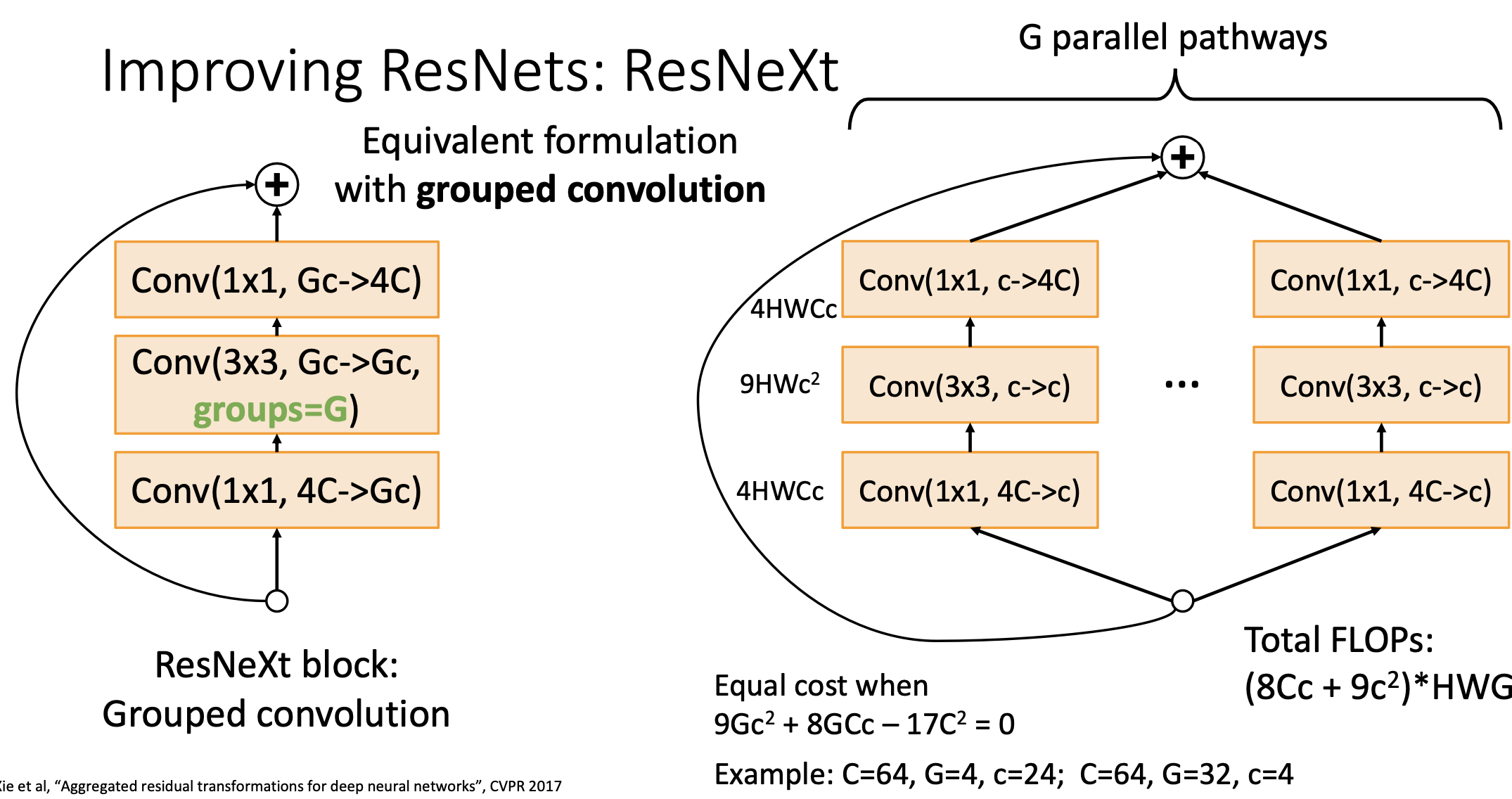
좌측처럼 groups=G를 설정해주면 병렬적인 네트워클 구조를 한큐에 연산이 가능하다. 그래서 ResNet에서 각자의 Bottleneck block을 grouped convolution으로 바꾼것을 우리는 ResNeXt라고 부름.
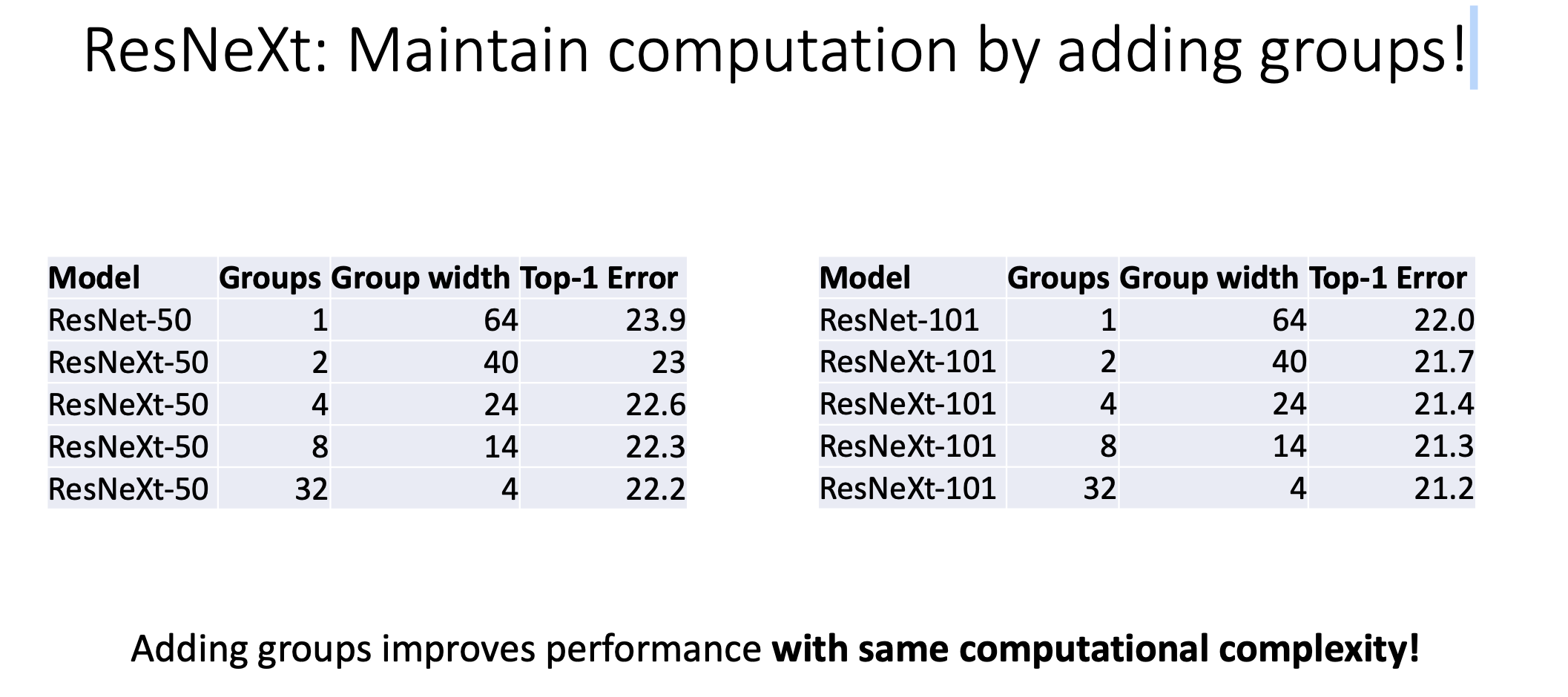
이렇게 하면 computational complexity는 같게 가져가면서 Accuracy를 improve함.
Grouped Convolution

이 방법은 채널을 기준으로 아예 2개로 split해가지구 따로 훈련을 시키고 나중에 output단계에서 모아줌. 반개의 채널씩만 보면서 GPU에 parrell한 계산을 시키기 더 쉬움. 이 녀석에 대한 연산 비용은 위와 같이 정리가 된다.

grouped convollution연산은 pytorch의 Conv2d함수에서 groups argument를 사용할 수 있다.
Post-ResNet Architectures
Squeeze-and-Excitation Networks
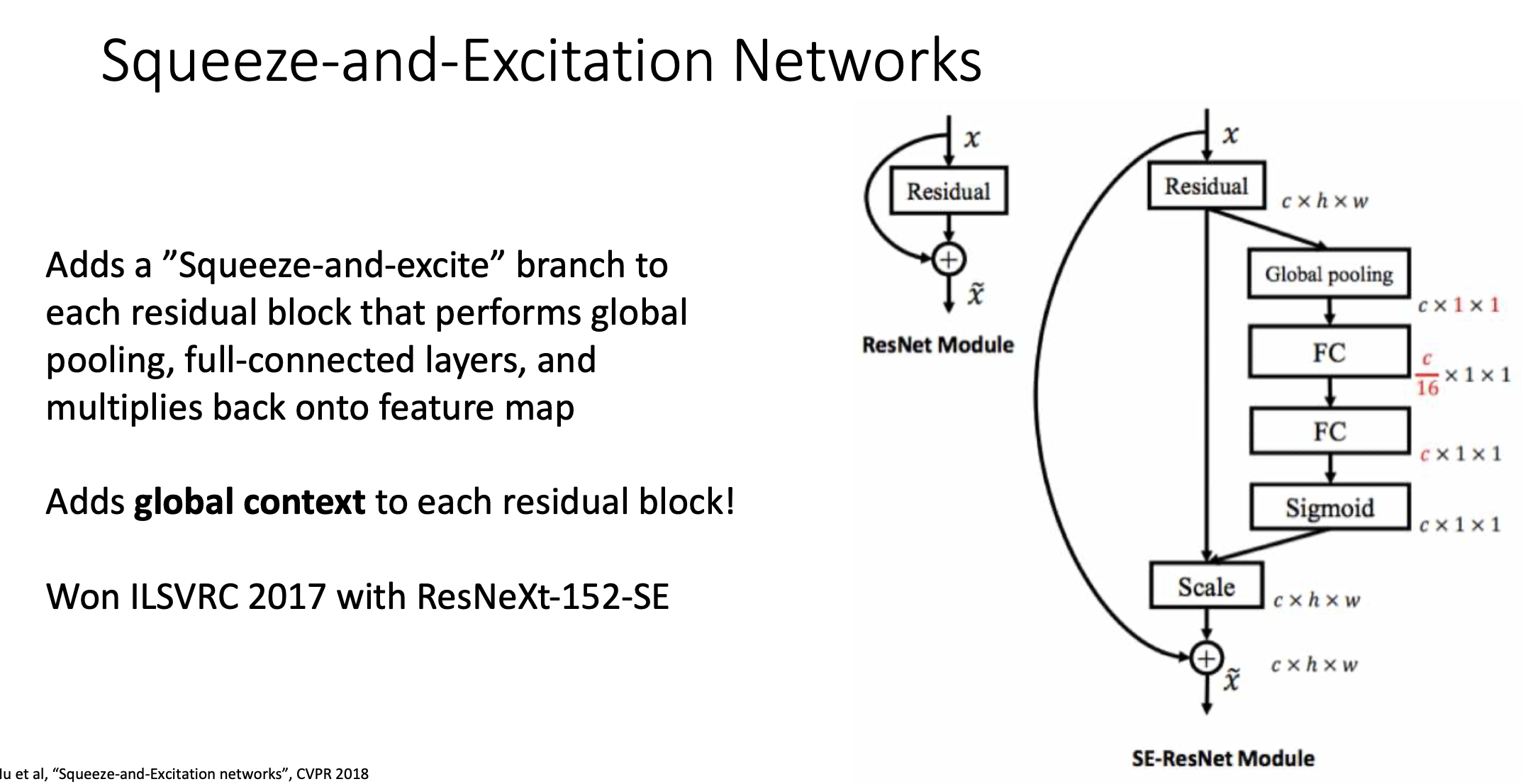
residual block에서 중간에 또 하나가 추가됨. 이것이 2017년 챌린지에서 1등을 함.
MobileNets : Tiny Networks
모바일 어플리케이션 쪽에서 빠른시간에 쓸수 있는 네트워크에 사람들이 관심을 기울임. 매우 적은 수의 연산으로 훈련 가능한 네트워크가 제안됨.

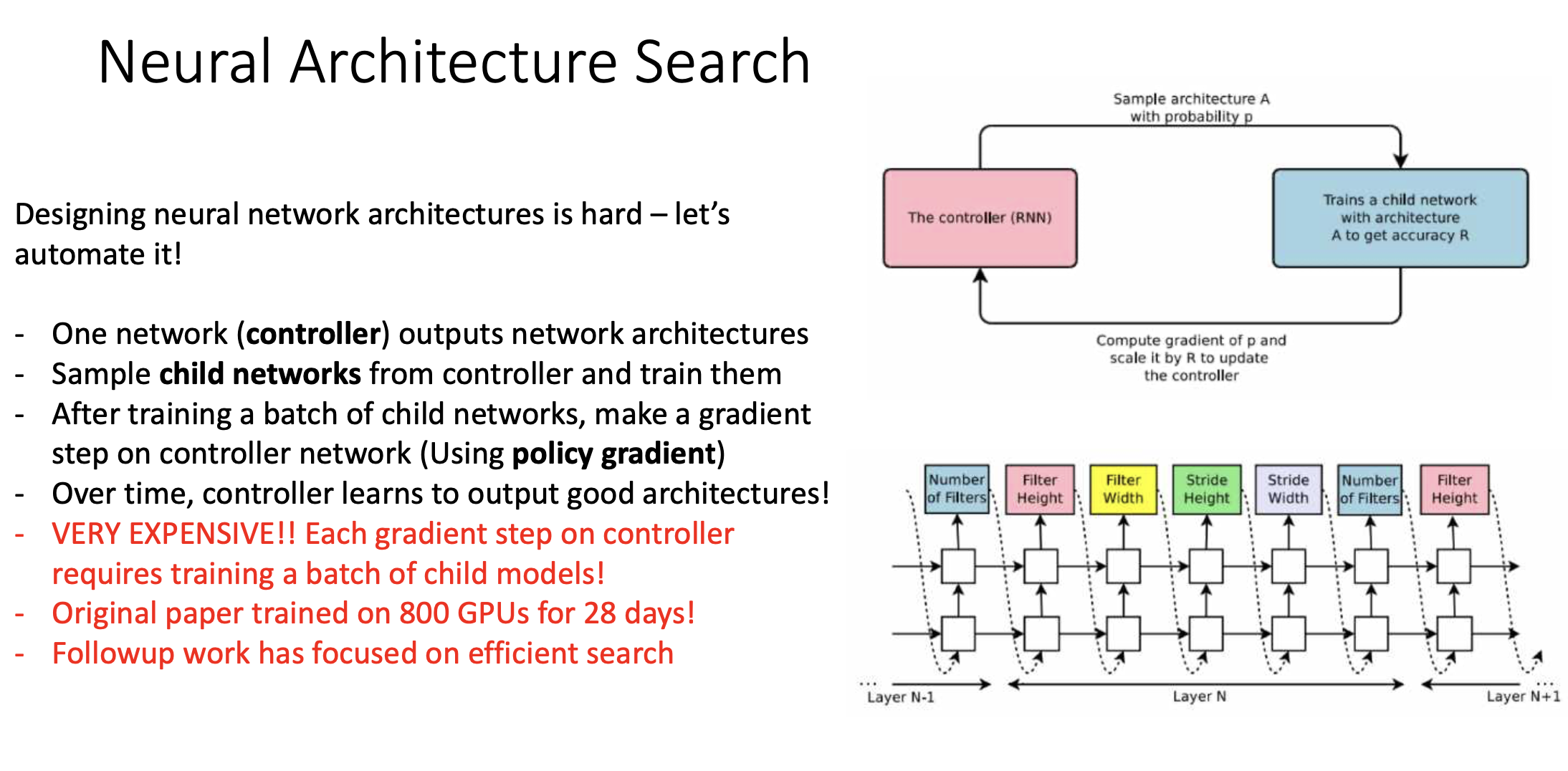
Neural Architecture Search
Neural Architecture자체를 자동화할 수 있는 방법. 어떤 원리로 찾냐면 네트워크를 training시키는 네트워크를 하나 만듦.