Introduction
Motivation
클라우드 제공자는 분석된 데이터 통계를 사용하여 다양한 응용 프로그램을 실행하기위한 컴퓨팅 리소스를 할당/할당해제 한다. 따라서 본 논문은 컴퓨팅 리소스를 효율적으로 할하기 위한 시계열 예측 프로세스를 향상시킬 수 있는 예측 모델을 식별하는 것을 목표로 한다. 이를 proactive auto-scaling mechanism이라고도 하는데, 과거의 리소스 활용도를 활용하여 그 다음 기간 동안 필요한 리소스 양을 추정한다.
Contribution
이 논문의 contribution은 클라우드 서버를 통한 네트워크 트래픽을 예측하기 위해 LSTM을 사용해 시계열 데이터 예측 분석을 했다는 것이다. 또한 LSTM 모델의 예측 정확도를 RMSE, MSE, MAE 세가지 메트릭을 사용해 측정했다.
Background Approaches for Workload Prediction
A. Simple Movine Average(SMA)
이 방법은 time series forecasting의 가장 단순한 방법으로 moving average를 계산하여 예측한다. 식은 아래와 같다.

이동 평균은 모델의 포착된 패턴에 따라 추세가 상승 또는 하강 중인지 빠르게 식별하는데 사용된다.
B. Autoregressive Moving Average(ARMA)
확률적 시계열 데이터의 경우, 연구자들은 자기 회귀 이동 평균 모델(ARMA(p,q)) 을 사용한다. p는 자기회귀 다항식의 차수이고 q는 이동평균 다항식의 차수이다. 식은 아래와 같다.

C. Autoregressive Integrated Moving Average(ARIMA)
ARIMA는 자기 회귀(AR) 방법과 이동 평균(MA) 방법을 통합하는 ARMA 모델의 통계 모델이다. 이 두 가지를 사용하여 결합된 모델을 구축하고 시계열 예측에 사용한다.
ARIMA에서 세가지 중요한 요소는 다음과 같다.
- p : 시계열이 지연되어야하는 lag는 p로 나타난다.
- d : 시계열 데이터를 Nonstationary에서 Stationary로 변환하는데 차분이 사용된다. 시꼐열에서 Stationary 상태로 변환하기 위해 필요한 차분 변환의 수는 d로 표시된다.
- q : 오류 성분의 지연은 q로 표시된다. 계산된 오류 성분은 추세 또는 계절성이 설명할 수 없는 시계열의 일부이다.
Description of Long Short-Term Memory (LSTM)
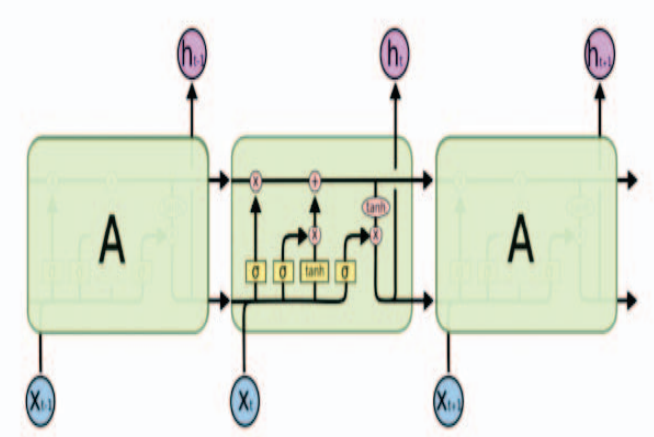
RNN은 short-term memory에 관한 문제가 있다. 시퀀스 길이가 길어지면 later time step에서 초기 time step을 반영하지 못한다. LSTM은 이러한 문제를 보완하기 위해 고안된 모델이다.
LSTM은 게이트라고 알려진 내부 메커니즘으로 구성되어 있다. 이러한 게이트는 주어진 시퀀스에서 어떤 데이터가 중요한지 또는 중요하지 않은지를 학습할 수 있기 때문에 이러한 방식으로 관련된 정보만 긴 시퀀스 chain에 전달되어 예측을 할 수 있다.
모든 셀은 gate로 구성되어있다. 각 셀에 대해 데이터 폐기, 데이터 필터링 또는 다음 셀에 대한 일부 데이터 추가가 수행된다. 네트워크를 통해 흐르는 값을 조절하기 위해 항상 0과 1사이 값으로 값을 줄이는 시그모이드 활성화 함수가 사용된다.
- Forget Gate : 0과 1 사이의 숫자 제공. 1은 해당 정보 보관, 0은 해당 정보 잊음
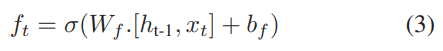
- Input Gate : 입력게이트는 셀 state를 업데이트 하는데 사용됨. 현재 입력과 마지막 hidden state가 시그모이드 함수로 전달되고 이 함수는 0과 1 사이의 값을 반환.
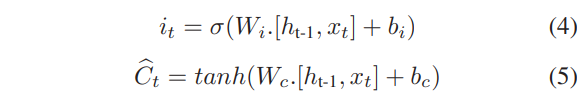
- Output Gate : 출력게이트는 다음 hidden state에 대한 결정을 내림. hidden state는 예측에 사용됨

Experimental Setup and Result Analysis
Dataset
24시간 간격 동안 분산 서버의 시간당 평균 load를 예측하는 모델이 사용된다. 예측 모델을 학습시키고 제안 방법을 평가하기 위한 입력 데이터는 마드리드 Computense University의 실제 웹 서비스 로그에서 얻은 것ㅇ디ㅏ. 데이터세트 timestamp와 hit수라는 두가지 속성이 있다.
Approach
모델은 2개의 레이어를 사용한다. 첫번째 레이어는 LSTM이고 다른 레이어는 Dense이다. Dense는 출력계층이고 LSTM은 입력 계층이다. 모델을 구축한 후 adam 최적화 도구와 MSE를 loss를 사용해서 파라미터를 업데이트한다. 예측의 정확도는 평균절대오차(MAE)와 근평균제곱오차(RMSE) 2가지를 사용하였다.
Dataset Splitting
데이터에서 70%는 학습에 사용되고 30%는 테스트에 사용되었다. 또한 splitting 비율을 변경하여 실험을 해보았는데 그 결과가 아래 그림이다.
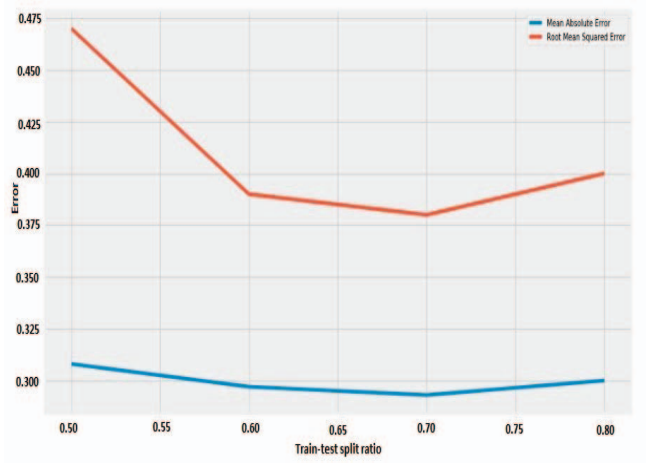
위의 그림을 보면 70%일때 가장 error가 작다.
Compiling the Model
모델 컴파일하려면 optimizer와 loss가 필요한데 Optimizer parameters는 learning rate를 조정하는 데 사용된다. Learning rate는 적용된 모델에 대한 최적 데이터가 얼마나 빨리 계산되는지 알려준다. 손실함수는 MSE를 사용하여 구현되고 이 값은 원래 데이터와 예측 데이터의 평균 제곱 차이를 사용하여 계산된다. 값이 0에 가까울수록 더 우수한 모델이다.
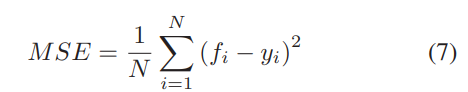
Training the Model
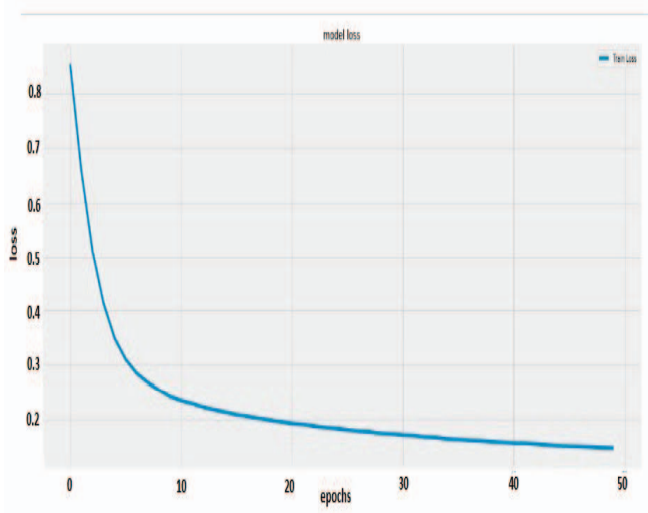
위의 그림은 loss plot을 나타낸 것으로 epoch이 증가할때마다 loss가 줄어들고 있다.
Prediction
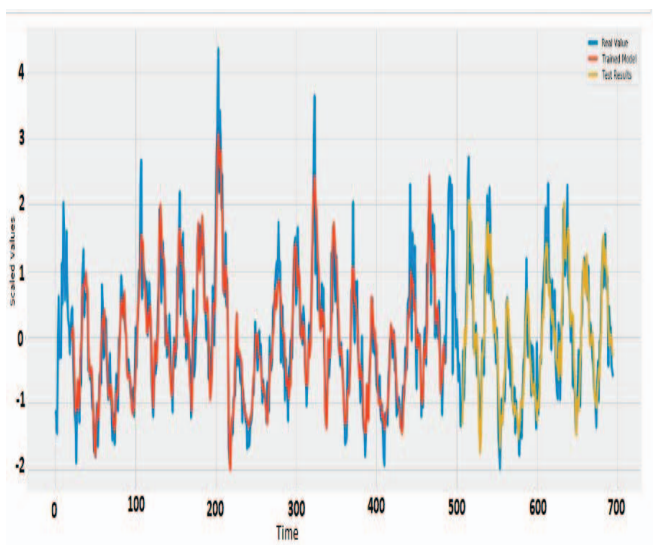
위의 그림에서 파란색 선은 orginal dataset이고 Red와 yello line은 training과 예측한 dataset이다.
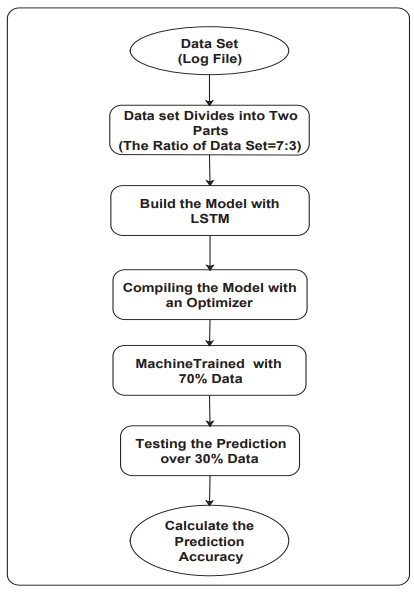
모델의 flow chart를 나타내면 다음과 같다.
Result Analysis
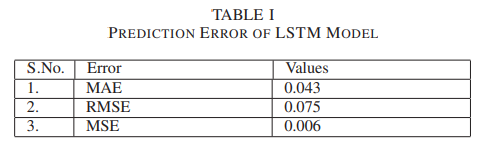
위의 테이블은 LSTM모델은 다른 measure를 사용해서 측정한 결과이다. 테이블을 보면 MAE, RMSE, MSE로 측정한 LSTM 모델의 예측 정확도는 0.043,0.075,0.066이라는 결론을 얻었다.