Introduction
클라우드 컴퓨팅 서비스 제공업체는 최적의 자원 이용률로 데이터센터를 운영하고자 한다. 그렇게 하기 위해서는 가상 머신 이주를 통한 동적 자원 관리가 필수적이다. 호스트 머신에 여분의 자원이 충분하다면 자원 이용률이 일정 수준 이상인 가상머신에 호스트 머신의 자원을 추가로 할당할 수 있다. 하지만 호스트 머신에 여분의 자원이 부족한 경우, 가상머신 이주가 불가피하다.
가상머신을 이주하는 방법은 크게 2가지이다.
- 사전 예방적 (proactive) : 호스트 머신의 과다적재 상태를 예측하고 미리 이주 작업을 수행
- 사후 대응적 (reative) : 실제 과다적재된 호스트가 발생하면 이주 작업을 수행
본 논문에서는 사전 예방적 방법을 위해 SVR과 ARIMA 모델을 학습하고 비교한다.
Background
ARIMA
ARIMA 모델은 ARIMA(p,d,q)로 나타내며, p와 q는 각각 자기회귀(AR), 이동평균(MA) 모델의 차수를, d는 원 시계열에 대한 차분 변환 적용 횟수를 의미함. 원 시계열의 d차 차분 계열에 자기회귀(AR)모델과 이동평균(MA) 모델의 선형결합인 AR(p,q)를 적용하는 방식으로 ARIMA의 예측값을 얻을 수 있다. 본 논문에서는 ARIMA를 비교기준 모델(baseline model)로 선택한다.
SVR
SVR은 SVM을 회귀 문제 풀이에 적합한 형태로 개조한 알고리즘으로 학습 데이터를 고차원 특징 공간으로 대응시킨 후 내적하는 과정을 커널 함수를 이용하여 수행한다. 이 과정에서 계산량을 줄이고 비선형 회귀식을 얻을 수 있다. 본 논문에서는 RBF 커널을 사용하여 성능 평가를 진행하였다.
관련 연구 및 연구 동기
기존 연구로는 ARIMA와 같은 통계기반 방법론, LSTM-RNN과 같은 딥러닝 방법론, GRU와 지수평활법은 결합한 GRU-ES라는 하이브리드 방법론 등이있다.
최근 연구에서는 커널 방법론인 SVR이 state-of-the-art 예측 정확도와 강건한 예측 성능을 보인다는 주장이 있다.
따라서 SVR 기법이 가상 머신 자원 이용률을 추적한 실제 데이터 Bitbrain, PlanetLab, Google Cluster Workload Traces 등에서도 우수한 예측 성능을 보이는지 검증할 필요성을 느낀 것이 연구 동기이다.
실험
실험 환경
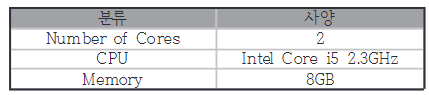
실험에 사용된 컴퓨터 사양은 다음과 같다.
실험 데이터는 Bitbrain 데이터센터에서 시랭된 가상머신 1250개의 자원 이용률을 5분 간격으로 1달 동안 추적한 결과를 담고 있는 fastStorage를 사용하였다. 전체 데이터를 7:3 비율로 나누어 학습과 예측 선으 테스트에 사용하였다. 또한, 학습 데이터의 개수와 예측 구간의 길이 별 성능 비교를 위하여 원 데이터를 100, 50, 20, 12, 6 주기로 샘플링한 데이터에 대하여 모델 학습 및 추론을 진행하였다.
평가 지표는 MSE를 사용하였다. 모델이 다양한 패턴에 대하여 강건한 예측 성능을 보이는지 확인하기 위하여 모든 시계열에 대해 측정된 MSE 평균값을 기준으로 성능을 비교 및 분석하였다.
실험 결과 비교 및 분석
<표2 : MSE로 나타낸 SVR, ARIMA의 샘플링 주기별 최고 성능>
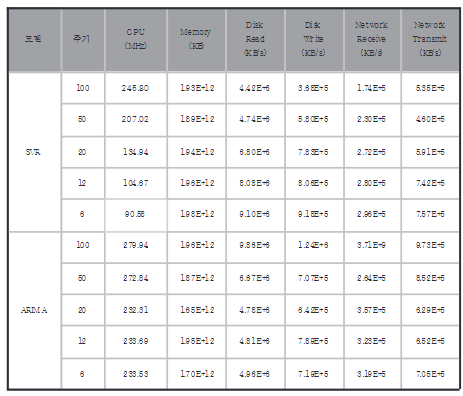
표2는 샘플링 주기를 다르게 하여 SVR, ARIMA의 MSE 성능을 나타낸 표이다. 표에서 확인할 수 있듯, CPU사용량 예측에서는 SVR이 모든 샘플링 주기에 걸쳐서 더 우수한 성능을 나타냈다. 하지만 샘플링 주기 20, 12, 6의 디스크 읽기, 쓰기, 데이터에 대한 예측 성능의 경우 ARIMA 모델의 오차가 더 적었다.
<표 3 : SVR, ARIMA의 샘플링 주기별 최고/최저 성능 비율>
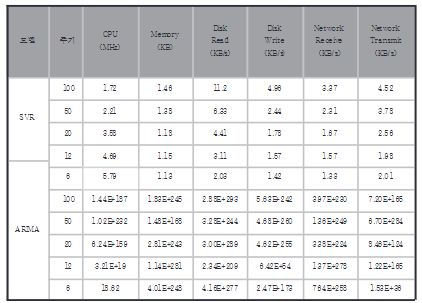
표 3에서 나타는 최고/최저 성능 비율 측면에서는 두 모델이 극명한 차이를 보였다. SVR은 샘플링 주기 100, 50의 디스크 읽기의 경우 11.2 6.33인 것을 제외하면 최고/최저 성능 비율이 모두 6 이하였다. 특히 메모리에서는 모든 샘플링 주기에서 최고/최저 성능 비율이 1.5보다 낮았다.
ㄸ모한 SVR은 CPU를 제외한 나머지 모든 종류의 자원에 있어서 샘플링 주기가 짧아질수록 최대/최저 성능 비율이 감소하는 양상을 보였다 이는 SVR자체가 구조적 위험 최소화를 통한 일반화 성능 최대화를 목표로 설계된 모델이기 때문에, 샘프링 주기가 짧아지고 더 많은 데이터로 학습한 결과 더욱 강건한 예측 성능을 보인 것으로 해석할 수 있다. 반면 ARIMA에서는 샘플링 주기와 최고/최저 성능 비율 사이의 뚜렷한 상관관계가 나타나지 않았다. 뿐만 아니라, 모든 샘플링 주기 및 자원 유형에서 SVR의 최저 성능 모델 MSE가 ARIMA의 최고 성능 모델 MSE의 5배 미만으로 나타났다.
결론 및 향후 연구
실험 결과를 비교해봤을 때, SVR과 ARIMA의 최고 성능 간에는 명백한 우열이 존재한다고 보기 어렵지만 성능 안정성 측면에서는 현격한 존재가 존재한다. 따라서 위험 관리 측면에서 볼 때 다양한 학습 데이터의 크기, 매개변수 설정 및 예측 대상 시계열 속에서 일정한 예측 성능을 꾸준히 보여주는 SVR의 비교 우위를 확인할 수 있다.
<그림1 : Bitbrain FastStorage 데이터 중 디스크 읽기 및 네트워크 수신 처리량>
하지만 본 논문은 여러개의 시계열이 주어지는 예측 문제에서 각각의 시계열에 대해 개별 모델을 만드는 방식이다. 이 경우, 시계열의 과거 값들이 학습 데이터로 활용되기 때문에 새롭게 실행된 가상머신의 경우 자원 이용률 예측이 잘 이뤄지기 어렵다. 또한 아래 그림1 에서 볼 수 있듯이 자원 이용량 데이터에서는 급격한 증감 패턴, 즉 스파이크가 산발적으로 나차난다. 가상머신이 일정기간 이상 실행되어 충분한 과거 데이터가 누적되었다고 해도, 이러한 패턴이 처음 나타나는 경우 예측이 정확하게 이루어지기 어렵다. 실제 퍼블릭 클라우드 공급 업체가 이와 같은 문제를 겪는다면 서비스 수준계약을 위반하게 될 가능성이 높게 된다는 한계점이 존재한다.