Visualizing and Understanding
참고 : https://velog.io/@kangtae/EECS-498-007-598-005-14.-Visualizing-and-Understanding
Intro
이번 강의는 convolutional neural network에서의 Visualizing and Understanding에 대해 다루어본다.
첫번째 토픽은 neural net내부를 들여다봐 training data에 대해 배운다는 것이 무엇인지 이해하려하는 테크닉이고
두번째 토픽은 neural net을 Visualizing 하고 Understanding하는데 사용되는 많은 테크닉들이 deep dream, style transfer와 같은 application에서도 사용될수 있다는 것이다.
Inside Convolutional Networks
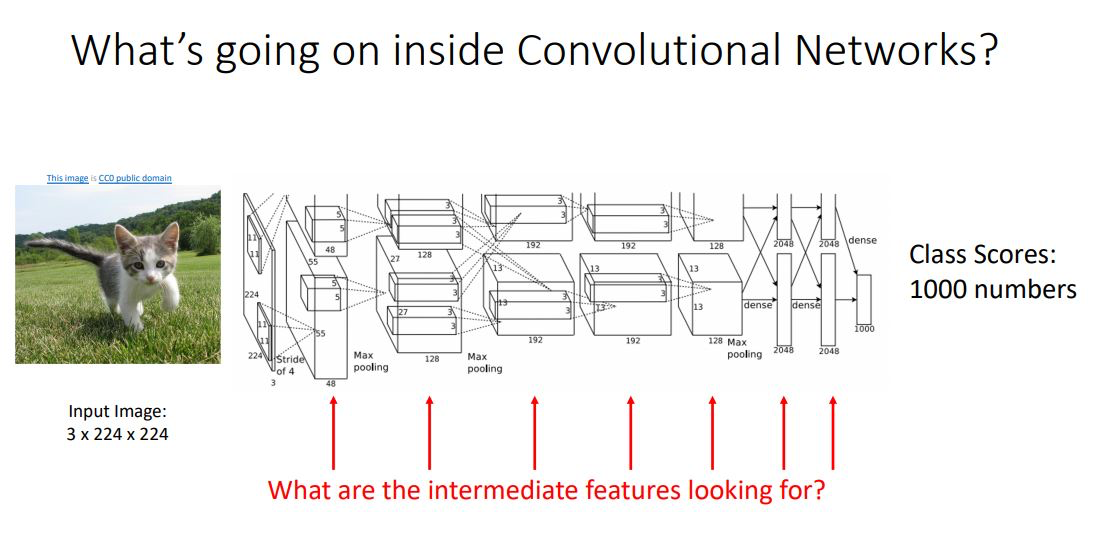
CNN내부의 각각의 다른 layer들과 feature들을 살펴보고 각각이 “why it works or why it dosen’t work”인지 알아봄 으로써 more intuition을 얻을 수 있다.
First Layer : Visualize Filters
Lec3 classification에서도 언급되었듯 neural net안에서 무슨일이 일어나는지 알아보는 가장 기본적인 아이디어로 first layer에서 filter를 시각화 해보는 것이다.

위 그림에서처럼 여러 CNN model의 첫번째 layer의 filter를 살펴보면 다음과같이 나타나며 이는 각각의 filter들이 나타내는 일종의 templates묶음이라고 생각해 볼 수 있다.
위에 나오는 architecture들은 각각 다른 구조를 가지고 있지만 첫번째 layer의 filter를 위처럼 시각화해서 나타내보면 상당히 비슷하다는 것을 알 수 있다.
Higher Layers : Visualize Filters

첫번째 layer에서 fiter를 시각화 했던 것 처럼 higher layer에서도 filter를 시각화 해 볼 수 있는데 위 그림처럼 두번째 세번째 layer만 보았을 때에도 channel과 dimension이 커지며 뭐가뭔지 이해하기 힘들어진다.
그렇기에 layer에서 무슨 일이 일어나고 있는지 알기위한 다른 테크닉이 필요하다.
Last Layer
Neural net이 뭘하고있는지 이해하기 위해 중간 layer들을 건너뛰고 마지막 fully-connected layer를 살펴볼 수 있다
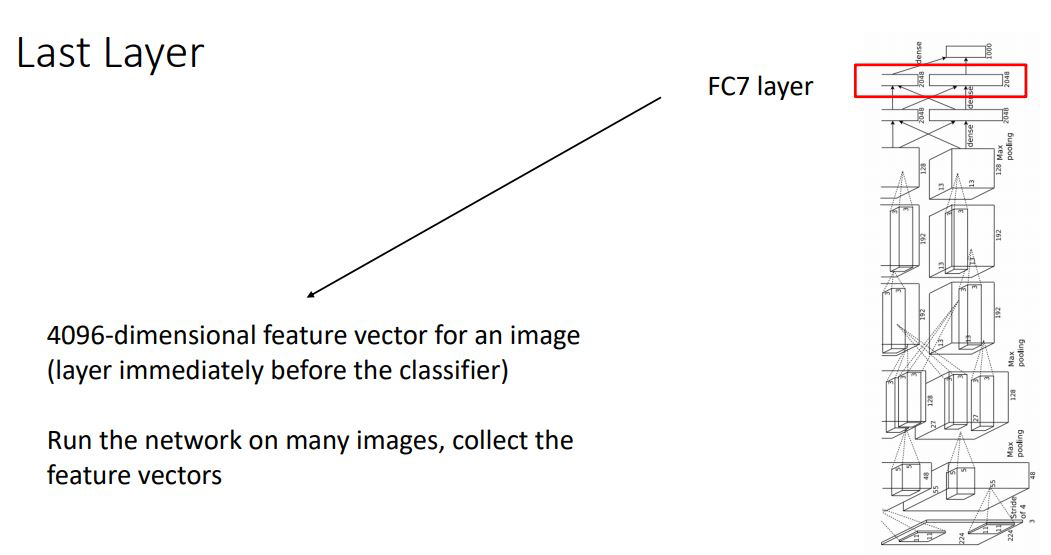
ImageNet dataset을 학습시킨 AlexNet에서 1000개의 class score를 도출하기 직전 4096-dimensional feature vector를 가진 FC7-layer를 다양한 테크닉을 통해 시각화화여 살펴봄으로써 network가 무엇을 “represent” 하려하는지 이해해보자.
Last Layer : Nearest Neighbors

- 가장 간단한 방법으로 4096-dimesional vector에 nearest neighbors를 적용해보자.
- 그림 왼쪽은 학습 시키기 전 pixel space에서 nearest neighbors를 적용시킨 모습이고 오른쪽 그림은 last layer(FC7)의 feature space에서 nearest neighbors를 적용시켜본 그림이다
- 이렇게 feature space에서의 NN은 오른쪽 그림의 코끼리처럼 머리가 어느방향으로 가있든 NN으로 찾은 test image가 trining image의 label과 동일 하다는 것을 볼 수있다
- 이를 통해 raw pixel value가 다르더라도 model을 거쳐 feature vector로 표현되는 것은 같은 label을 갖을수 있다는 것을 보여준다
Last Layer : Dimensionality Reduction
- 이러한 feature space에서 적용해볼수있는 또다른 방법으로는 몇몇의 dimensionality reduction algorithms을 사용해보는 것 이다
- FC-7의 4096-dimesional를 2-dim과 같이 low-dim space로 변환시켜 우리가 구분할수 있게끔 만들어준다.
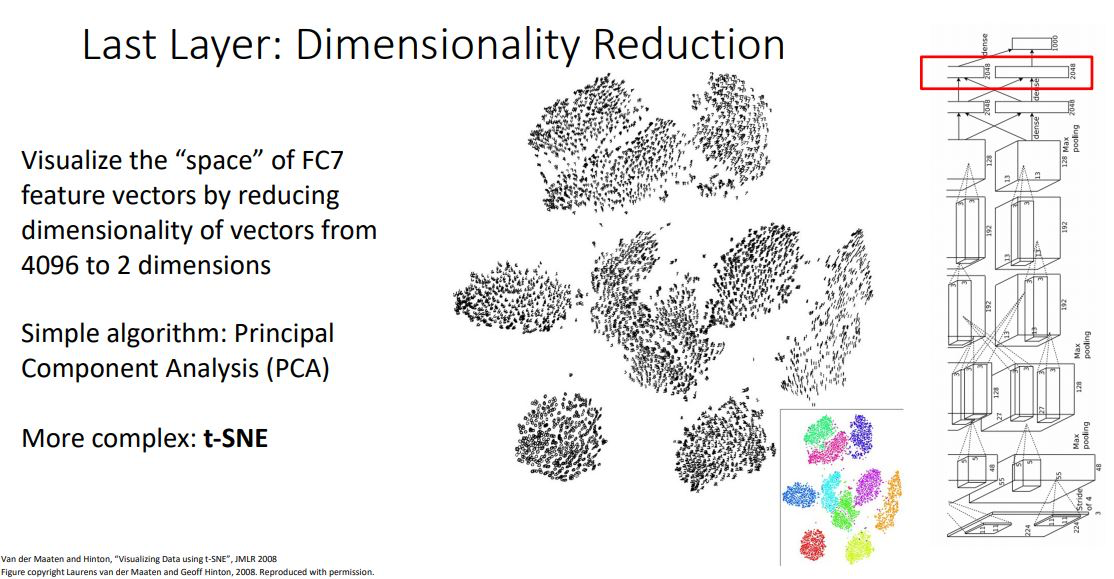
- ML에서 흔히 볼 수 있는 algorithm인 PCA를 적용하여 선형적으로 dimesion을 축소해볼 수 있다. (또다른 인기있는 dimensional reduction algorithm인 t-SNE를 적용해 볼 수도 있다(non-linearity reduction 방법))
- 위 그림은 10class를가진 MNIST를 학습한 model에서 모든 test-set image를 t-SNE를 적용하여 2-dim에 point로 나타낸 모습이다.
- 이때 reduction결과가 10개의 cluster로 나눌수 있는 모습을통해 학습을 통한 model의 feature space가 일종의 identity of the class를 encoding하였다고 생각해 볼 수 있다.

- 위 그림은 MNIST를 학습시킨 model이 아닌 ImageNet을 학습시킨 model의 feature space를 dimensional reduction시킨 모습이다.
- 위 그림으론 이해하기 어렵지만 아래 링크의 high-resolution version을 통해 살펴보면 different sorts of semantic categories에 대응하는 differnet region of space를 살펴볼 수 있다고한다. -> high-resolution version으로 줌해서 살펴보면 각각 class들이 cluster를 이루는 것을 볼 수 있다.
Visualizing Activation
Neural net model 중간 layer의 weights를 시각화하는 것은 어렵기 때문에 다른 방법으로 CNN의 중간 conv layer의 activation map을 시각화 해 볼 수 있다.
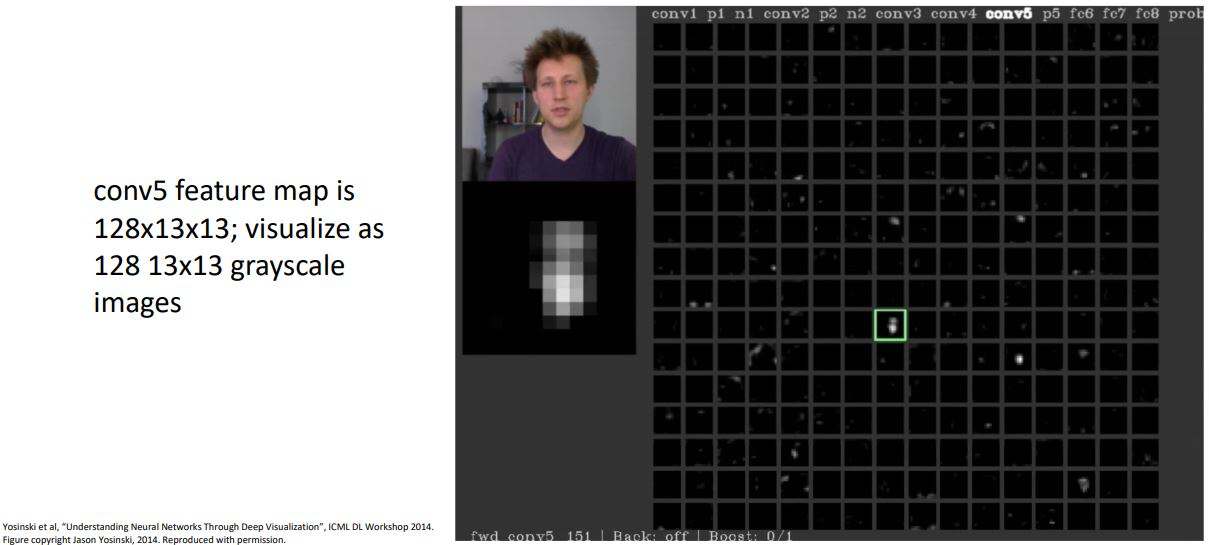
- 위 그림은 conv5 layer의 128x13x13 activation map을 각 channel별로 gray scale로 시각화 한 것으로 이들중 가운데 초록색 박스로 나타낸 activation map을 살펴보게되면 각 positional 값들이 input image의 얼굴에 대해서 높은 activation값을 갖는것으로 보여지며
- 위와같이 다른 이미지 별로 각 layer의 activation map을 살펴봄 으로서 각각의 layer의 filter들이 무엇을 나타내고 있는지에 대한 직관을 살펴볼 수 있다.
- 여기서 대부분 filter의 값들이 black에 가까운 이유는 ReLU non-linearlity를 거쳤기 때문이라고 한다.
Maximally Activating Patches
또 다른 방법으로 위 처럼 random image 혹은 random filter에 대해서 visualize해보는 것이 아닌 neural net내부의 다른 filter간 Maximally activation값을 찾는 것이다.
한 layer의 한 filter를 선택해 모든 training set, 모든 test set이미지의 patch를 기록하고 highest responses를 찾는 것이다

- 쉽게말해 위 그림처럼 fix된 layer에서 fix된 channel의 가장큰 activation이 큰 neuron을 모아 visualization해보니 각 카테고리별로 해당 layer의 각각의 channel이 image에서 중요하게 생각하는 부분이 비슷하다는 것을 알수있다.(sequence data에서 attention이 적용되는 mechanism과 어느정도 비슷하다고 생각이 든다)
- 이때 위 visualization grid의 한 row의 각 column인 element는 patch에서 매우 높은 responce를 보인 것들이다.
- 결국 어떤 neruon에서 큰 activation을 보이는지는 중요하지 않고 각 layer의 각 channel에서 카테고리별로 attention하는 부분이 비슷하다 라는 것을 생각해 볼 수 있다.
- 아래의 grid는 좀더 깊은 network에서 visualize한 못습으로 한 neuron의 receptive field 가 크니 input image에서 넓은 영역을 보고있다
Which Pixels Matter ?
또 다른 방법으로는 input image에서 어떤 pixel이 실제로 model이 중요하게 생각하는지 알아보는 것이다. 다시말해 이미지의 어떤 부분이 network가 분류를 위한 결정의 근거가 되는지 알아보는 것이다.

- 위 그림처럼 이미지의 특정 부분을 gray값 등으로 변환시키는 masking을 모든 position별 shifting시켜 (sliding window마냥) score(probability)를 구하여 Saliency map을 도출하고 이를통해 어떤 부분의 pixel들이 가장 판단에 영향을 미치는가를 볼 수 있다.
- 이때 특정 부분을 masking하면 score(softmax에서 probability)가 급격히 떨어지는 (붉은색) 부분을 heat map을 통해 살펴 볼 수 있고 이러한 부분들이 중요한 부분임을 나타낸다
Saliency via Backprop

- 또다른 Saliency map을 도출하는 방법은 한 image의 class score값을 backprop시켜 어떤 pixel에서 activation이 있는지 살펴보는 것이다.
- 이미 학습된 weights 값들은 변하지 않지만 test image를 backprop시켜보면 어떤 pixel의 activation이 살아나는지 볼 수 있다.
- 여러 이미지에대해 살펴보면 다음과같이 나타남


위 그림처럼 Saliency map에서 GrabCut방법을 사용하면 따로 label을 주지 않고도 un-supervised로 segmentation 작업을 학습할 수 있다는 장점이 있다고 한다. 하지만 역시 supervised보단 정확도가 매우 떨어진다고 한다.
Intermediate Features via (guided) backprop
Backprop을 통해 살펴보는 또다른 방법으로 guided backprop이 있다.
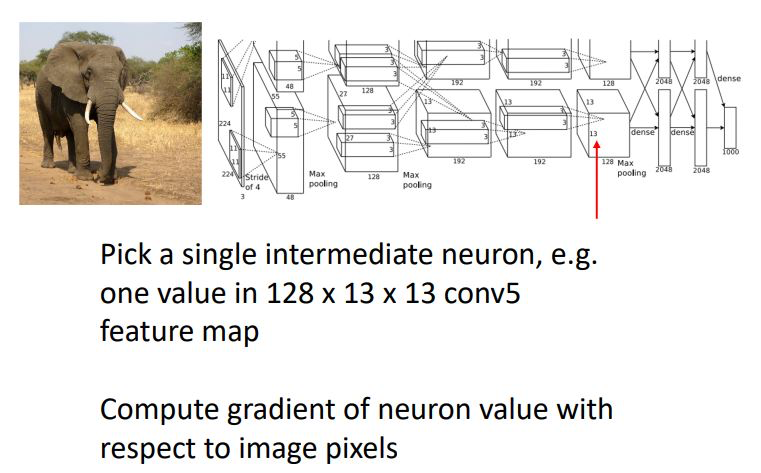
- 이전에 class score를 backprop시킨 것과 다르게 intermediate feature를 backprop시켜 image의 어떤 부분이 class score가 아닌 선택한 singel neuron에 영향을 주는지를 살펴보는 것 이다
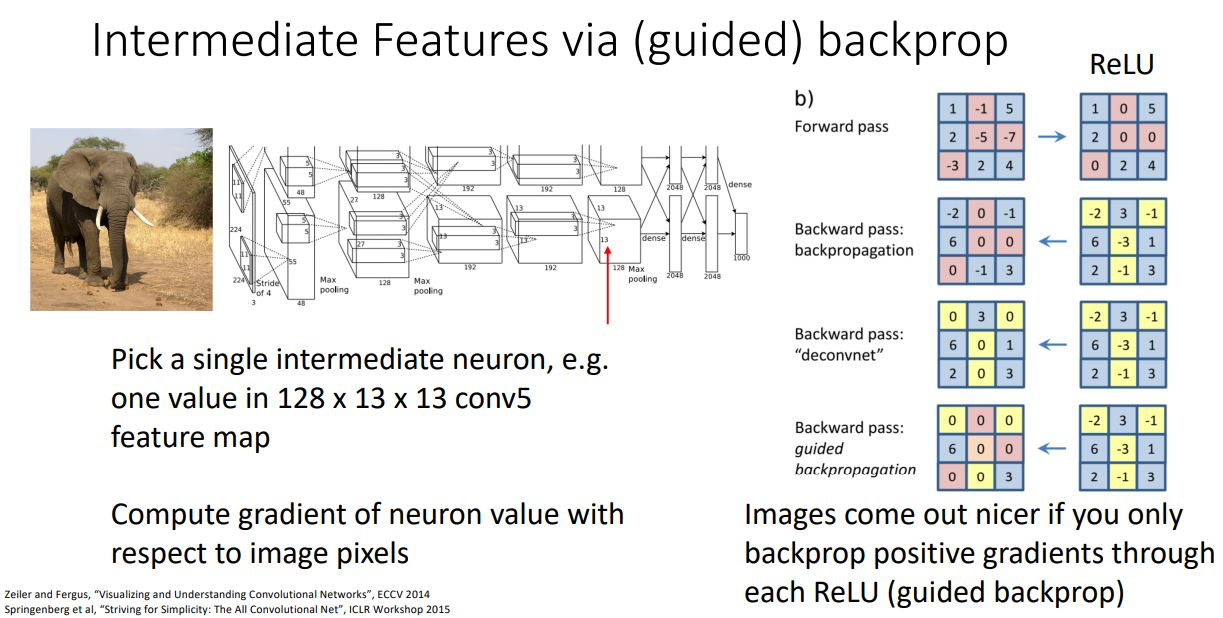
- 이때 backpro과정에서 일반적인 backprop을 수행하는 것이 아니라 조금 다른 과정을 거치게 된다.
- 위 그림처럼 forward pass과정에서 ReLU를 거치면 negative값들이 zero가 되기 때문에 backprop에서도 negative upstream gradient를 죽여 zero로 만든다. (upstream gradient에 forward pass와 같은 masking을 하겠다는 것)
- 이러한 과정을 통해 깔끔한 visualize가 된다고 한다.
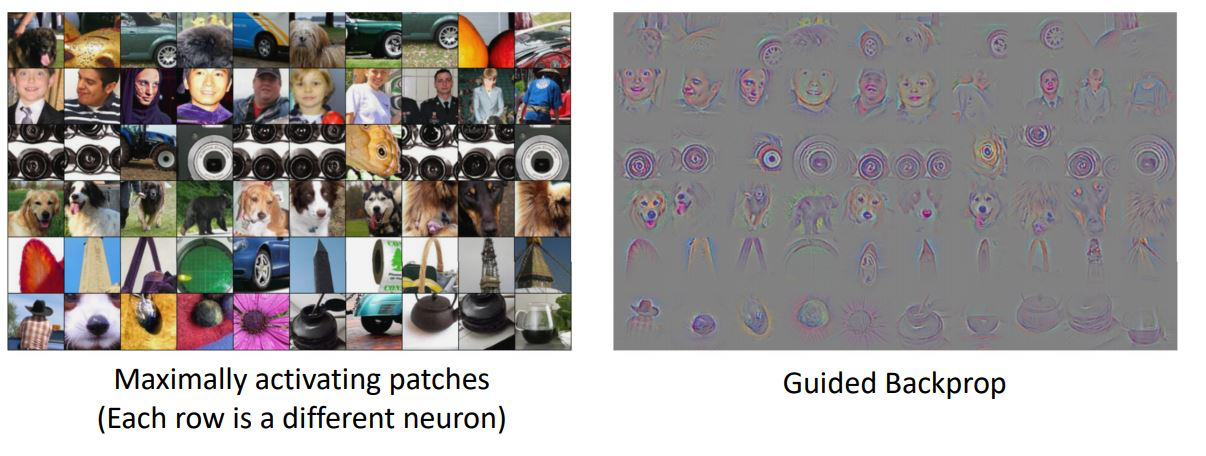
- 위 결과를 살펴보니 Maximally activating patches에서의 각 neuron이 어떤 pixel에 영향을 받는지를 살펴보면 동일한 부분을 살펴보고 있다는 것을 알 수 있다.
- 이러한 방법은 test image 혹은 input patch의 제한된 부분이 (or pixel이) 특정 neuron에 얼마나 영향을 미치는가를 나타낼 뿐이다
- 그렇다면 모든 possible image에서 어떤 image가 해당 neuron을 maximally activate시키는지를 알수있는 방법은????
Gradient Ascent

우리가 원하는 것은 특정 neuron이 maximized value를 갖게하는 새로운 synthetic image를 생성하는 것이다.
위 그림의 수식에서 I* 는 우리가 선택한 neuron이 maximally activate값을 갖게하는 image이며
f(I)는 우리가 선택한 neuron의 value이고
R(I)는 일종의 regularizer로 이미지를 생성할 때 natural하게 만들어주게된다.
이러한 Gradient Ascent는 weights를 훈련하는 것이 아닌 선택한 neuron이 maximally activation 값을 갖는 혹은 클래스 스코어를 최대화 시키는 image(의 pixel)을 학습하는 것 이다.
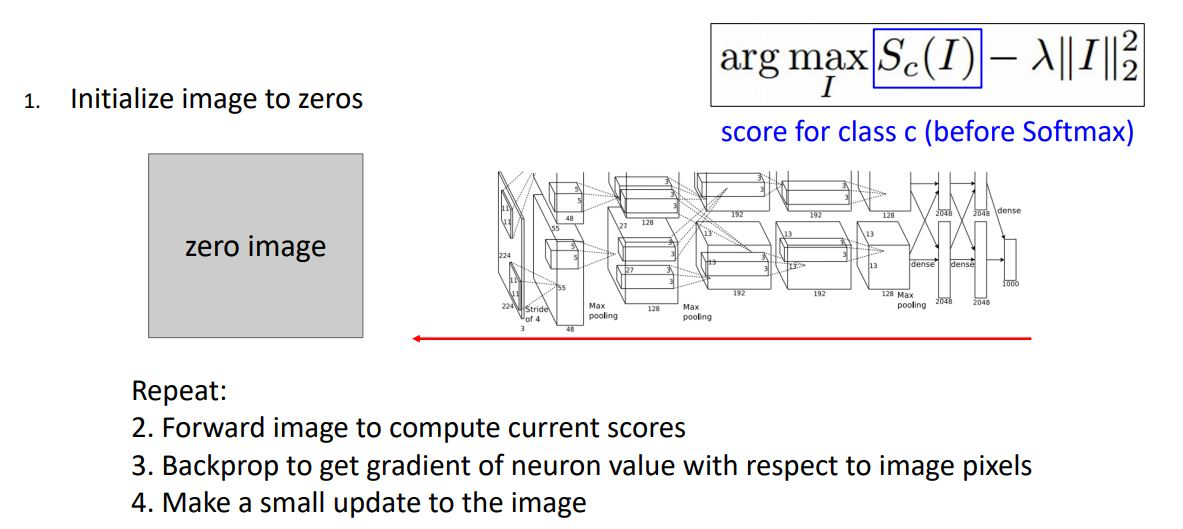
Gradient ascent를 통해 이미지를 생성하기 위해 일단 input 이미지를 zeros, random noise등으로 initialize시킨다.
그리고선 image를 network에 forward시켜 하나의 neuron값 혹은 score를 구하고 각 pixel에 대한 해당 neuron 혹은 score의 gradient를 계산하기 위해 backprop시킨다.
이러한 과정을 반복하여 score 혹은 neuron의 activation값을 최대화 시키게끔 pixel을 update한다.

이때 일반적인 gradient descent에서는 weights가 overfit하는 것을 막기위해 penelty를 주는 방식으로 regularization term을 사용하는 반면에 Gradient ascent에서는 반대로 생성되는 이미지들이 학습된 model에 overfit하는 것을 막기 위함이다.
하지만 위와같은 결과는 natural해보이지 않는다. 그래서 regularizer를 변형하여 이용해 보면 다음과 같다.

사람들은 생성되는 이미지가 좀더 네츄럴해 보이도록 여러 regularizer들을 연구해왔고 그 방법 중 하나가 위와같이 l2 norm 에다가 주기적으로 Gaussian blur를 적용하고 pixel 을 cliping하는 방법이다.

이 전 그림처럼 socre에 대해 gradient ascent를 하는 것이 아닌 network 내부에서 각 layer, neuron에 maximally activation을 위한 gradient ascent를 해주면 위 그림과같다.
위 같은 방법 이외에 여러 논문들에서 효과적인 regularizer를 연구하여 훨씬 네츄럴한 이미지를 생성하기위한 방법들이 제시되고 있음을 아래그림을 통해 볼 수 있다.

Adversarial Examples
Adversarial(fooding) image를 생성하는 방법은 아래와 같다.
- 임의의 이미지를 골라
- 해당 이미지의 다른 카테고리를 선택 후
- 선택한 카테고리의 class score를 gradient ascent를 통해 maximize 시켜 이미지를 약간 변형시킨다

이러한 adversarial 기법을 통해 위 그림과같이 코끼리를 코알라로 자신있게 classify 하게끔 network를 속일 수 있는데 이때 pixel을 아주 약간 변형하였기에 거진 차이가 없다
Feauture Inversion
Gradient ascent를 활용하여 network가 뭘하고 있는지 이해하는 또 다른 방법으로 Feature Inversion이 있다.



위 예제를 통해 우리는 두 이미지를 Feature Inversion시키면 각 layer에서 ReLU를 통해 어떤 feature information이 보존되거나 버려지는지 살펴볼 수 있다.
DeepDream
DeepDream은 이미지의 특정 feature를 maximize하는 대신 amplify 시키는 것 이다
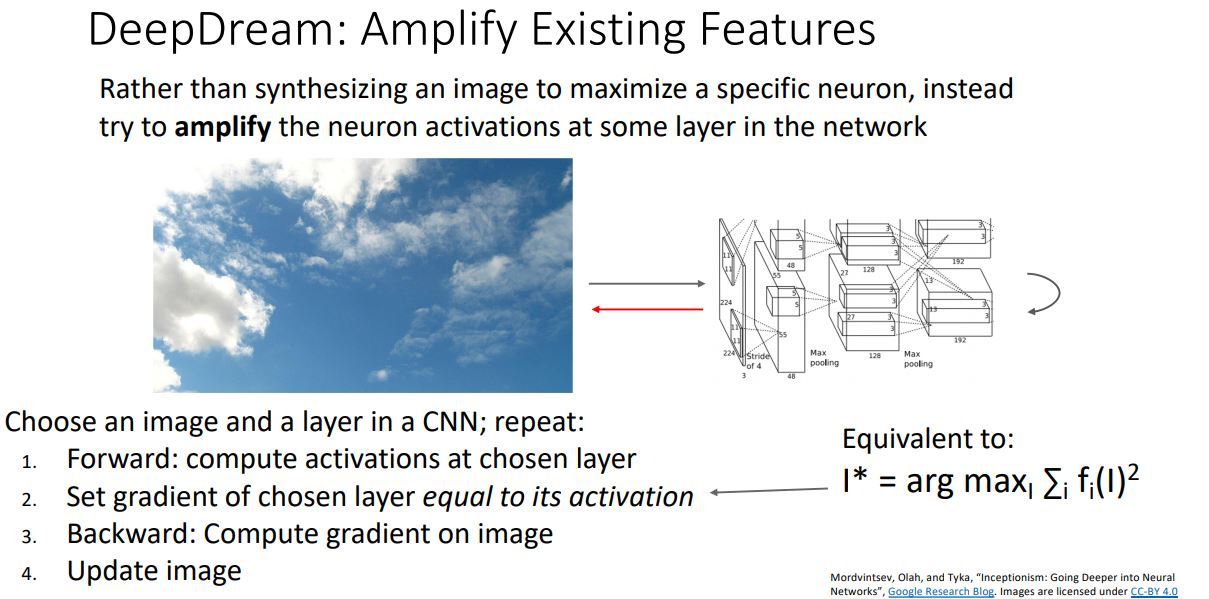
DeepDream은 다음과 같은 메커니즘을 갖는다.
- 이미지를 CNN에 forwarding시켜 특정 layer에서 feature를 추출한다.
- 해당 layer의 gradient를 해당 activation value로 설정해준다.
- 설정된 gradient를 backprop시키고 image를 update시킨다.
위와같은 과정을 통해 특정 feature의 activation을 훨씬 크게 작용하도록 image를 변형하는 것 이다.